







1、一些概念
1.1 数据库
数据库(database) 保存有组织的数据的容器(通常是一个文
件或一组文件)。数据库是通过DBMS创建和操纵的容器。数据库可以是保存在硬设备上的文件,但也可以不是。
理解数据库的一种最简单的办法是将其想象为一个文件柜。
1.2 数据库管理系统(DBMS)
通常并不直接访问数据库;你使用的是DBMS,它替你访问数据库。
1.3 RDBMS
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
1.3.1 表
在文件柜中创建文件,然后将相关的资料放入特定的文件中。在数据库领域中,这种文件称为表。表是一种结构化的文件,可用来存储某种特定类型的数据。
数据库中的每个表都有一个名字,用来标识自己。此名字是唯一的,
模式(schema)
关于数据库和表的布局及特性的信息
如可以存储什么样的数据,数据如何分解,各部分信息如何命名,等等。描述表的这组信息就是所谓的模式,模式可以用来描述数据库中特定的表以及整个数据库(和其中表的关系)。
1.3.2 列和数据类型
表由列组成。列中存储着表中某部分的信息。
列(column) 表中的一个字段。所有表都是由一个或多个列组
成的。
正确地将数据分解为多个列极为重要。
数据库中每个列都有相应的数据类型。
数据类型(datatype) 所容许的数据的类型。每个表列都有相
应的数据类型,它限制(或容许)该列中存储的数据。
数据类型限制可存储在列中的数据种类(例如,防止在数值字段中录入字符值)。数据类型还帮助正确地排序数据,并在优化磁盘使用方面起重要的作用。因此,在创建表时必须对数据类型给予特别的关注。
1.3.3 行
表中的数据是按行存储的,所保存的每个记录存储在自己的行内。
行(row) 表中的一个记录(record)。
1.3.4 主键
表中每一行都应该有可以唯一标识自己的一列(或一组列)。
主键(primary key) 一列(或一组列),其值能够唯一区分表中每个行。
唯一标识表中每行的这个列(或这组列)称为主键。主键用来表示一个特定的行。
应该总是定义主键 虽然并不总是都需要主键,但大多数数据
库设计人员都应保证他们创建的每个表具有一个主键,以便于
以后的数据操纵和管理。
表中的任何列都可以作为主键,只要它满足以下条件:
任意两行都不具有相同的主键值;
每个行都必须具有一个主键值(主键列不允许NULL值)。
主键值规则 这里列出的规则是MySQL本身强制实施的。
在使用多列作为主键时,上述条件必须应用到构成主键的所有列,所有列值的组合必须是唯一的(但单个列的值可以不唯一)。
主键的最好习惯 除MySQL强制实施的规则外,应该坚持的
几个普遍认可的最好习惯为:
不更新主键列中的值;
不重用主键列的值;
不在主键列中使用可能会更改的值。(例如,如果使用一个
名字作为主键以标识某个供应商,当该供应商合并和更改其
名字时,必须更改这个主键。)
还有一种非常重要的键,称为外键。
1.3.5 外键
引用完整性
2、什么是SQL
SQL 是结构化查询语言(Structured Query Language)的缩写。SQL是一种专门用来与数据库通信的语言。
SQL有如下的优点:
SQL不是某个特定数据库供应商专有的语言。几乎所有重要的
DBMS都支持SQL,所以,学习此语言使你几乎能与所有数据库
打交道。
SQL简单易学。它的语句全都是由描述性很强的英语单词组成,
而且这些单词的数目不多。
SQL尽管看上去很简单,但它实际上是一种强有力的语言,灵活
使用其语言元素,可以进行非常复杂和高级的数据库操作。
DBMS专用的SQL SQL不是一种专利语言,而且存在一个标
准委员会,他们试图定义可供所有DBMS使用的SQL语法,但
事实上任意两个DBMS实现的SQL都不完全相同。
编写SQL语句需要对基础数据库的设计有良好的理解。不知道什么信息存储在什么表中,表之间如何相互关联以及行内数据如何分解,是不可能编写出高效的SQL的。
3、MySQL
最容易得到的客户机软件是mysql命令行实用程序。
(它包含在每个MySQL安装中)。另外两个重要实用程序是MySQL
Adiminstrator 和 MySQL Query Browser。
3.1 mysql 工具
3.1.1 mysql
4、关系数据库设计
各种数据的组织和关系
1、多表间的关系
为什么要有多表
拆表
单表的缺点:
有些情况下,使用一张表表示数据不好维护, 存在数据冗余,比较乱的现象
使用多张表时,需要对数据进行约束,不约束,添加的数据会不合法
外键约束
表和表之间存在一种关系,但是这个关系需要谁来维护和约束?
1.1 外键约束作用
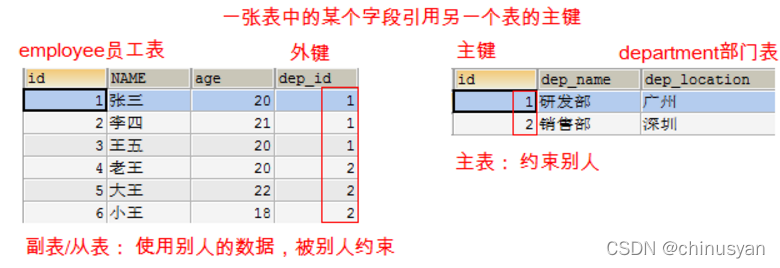
- 用来维护多表之间关系
外键: 一张从表中的某个字段引用主表中的主键
主表: 约束别人
副表/从表: 使用别人的数据,被别人约束
1.2 外键的语法
添加外键
1. 新建表时增加外键:
[CONSTRAINT] [外键约束名称] FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名)
关键字解释:
CONSTRAINT -- 约束关键字
FOREIGN KEY(外键字段名) –- 某个字段作为外键
REFERENCES -- 主表名(主键字段名) 表示参照主表中的某个字段
2. 已有表增加外键:
ALTER TABLE 从表 ADD [CONSTRAINT] [外键约束名称] FOREIGN KEY (外键字段名) REFERENCES 主表(主键字段名);
删除外键
- alter table 表 drop foreign key 外键名称;
为已存在的表添加外键,注意:外键字段上不能有非法数据
-- 往员工信息表中添加非法数据---部门id不存在
INSERT INTO employee (NAME, age, dep_id) VALUES ('老张', 18, 6);-- 失败
1.3 外键的级联
- 要把部门表中的id值2,改成5,能不能直接修改呢?
UPDATE department SET id=5 WHERE id=2;
不能直接修改:Cannot delete or update a parent row: a foreign key constraint fails 如果副表(员工表)中有引用的数据,不能直接修改主表(部门表)主键
- 要删除部门id等于1的部门, 能不能直接删除呢?
DELETE FROM department WHERE id = 1;
不能直接删除:Cannot delete or update a parent row: a foreign key constraint fails 如果副表(员工表)中有引用的数据,不能直接删除主表(部门表)数据
什么是级联操作:
在修改和删除主表的主键时,同时更新或删除副表的外键值,称为级联操作
ON UPDATE CASCADE – 级联更新,主键发生更新时,外键也会更新
ON DELETE CASCADE – 级联删除,主键发生删除时,外键也会删除
具体操作:
- 删除employee表
- 重新创建employee表,添加级联更新和级联删除
CREATE TABLE employee (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(30),
age INT,
dep_id INT,
CONSTRAINT employee_dep_fk FOREIGN KEY (dep_id) REFERENCES department(id) ON UPDATE CASCADE ON DELETE CASCADE
);
多表间关系
- 一对多
- 多对多
- 一对一
一对多(1:n)
例如:班级和学生,部门和员工,客户和订单
一的一方: 班级 部门 客户
多的一方:学生 员工 订单
一对多建表原则: 在从表(多方的一方)创建1一个字段,字段作为外键指向主表(一方)的主键

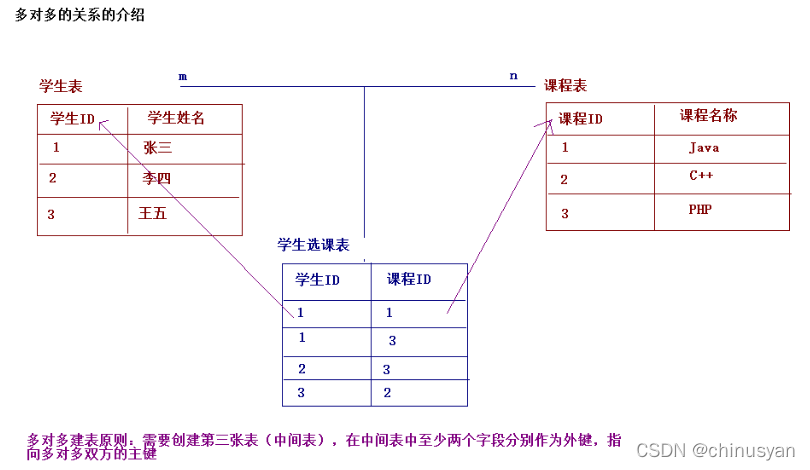
多对多(m:n)
例如:老师和学生,学生和课程,用户和角色
一个老师可以有多个学生,一个学生也可以有多个老师 多对多的关系
一个学生可以选多门课程,一门课程也可以由多个学生选择 多对多的关系
一个用户可以有多个角色,一个角色也可以有多个用户 多对多的关系
多对多关系建表原则: 需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的主键。
一对一(1:1)(通常单表)
例如: 一个公司可以有一个注册地址,一个注册地址只能对一个公司。
例如:一个老公可以有一个老婆,一个老婆只能有一个老公
在实际的开发中应用不多.因为一对一可以创建成一张表。
两种建表原则:
- 外键唯一:主表的主键和从表的外键(唯一),形成主外键关系,外键唯一UNIQUE
- 外键是主键:主表的主键和从表的主键,形成主外键关系
2、连接查询
-- 创建部门表
CREATE TABLE dept (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
INSERT INTO dept (NAME) VALUES ('开发部'),('市场部'),('财务部');
-- 创建员工表
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
gender CHAR(1), -- 性别
salary DOUBLE, -- 工资
join_date DATE, -- 入职日期
dept_id INT
);
交叉查询
1、语法
select ... from 表1,表2 ;
select a.字段,b.字段 from a,b ;
select a.*,b.* from a,b ;
--或者
select * from a,b;
练习: 使用交叉查询部门和员工
SELECT * FROM dept, emp;
左表的每条数据和右表的每条数据组合,这种效果称为笛卡尔乘积
交叉查询其实是一种错误.数据大部分是无用数据,叫笛卡尔积
内连接查询
1 隐式内连接
隐式里面是没有inner关键字的
select [字段,字段,字段][*] from 表1,表2 where 连接条件 --(外键的值等于主键的值)
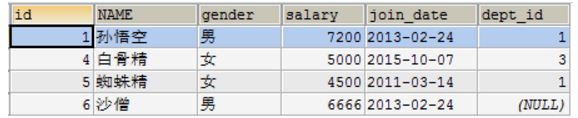
select * from emp,dept where emp.dept_id = dept.id;
- 练习:查询员工的id,姓名,性别,薪资,加入日期,所属部门
select emp.id,emp.name,emp.gender,emp.salary,emp.join_date,dept.name from emp,dept where emp.dept_id = dept.id;
-- 取别名---开发中一般使用取别名的方式
select e.id,e.name,e.gender,e.salary,e.join_date,d.name from emp e,dept d where e.dept_id = d.id;
2 显示内连接
显示里面是有inner关键字的
select [字段,字段,字段][*] from a [inner] join b on 连接条件 [ where 其它条件]
select * from emp inner join dept on emp.dept_id = dept.id
select * from emp inner join dept on emp.dept_id = dept.id where emp.id = 2
select * from emp join dept on emp.dept_id = dept.id where emp.id = 2
内连接查询的是公共部分,满足连接条件(主外键关系)的部分
使用主外键关系做为条件来去除无用信息.
显示内连接里面的,on只能用主外键关联作为条件,如果还有其它条件,后面加where
外连接
我们发现内连接查询出来的是公共部分. 如果要保证某张表的全部数据情况下进行连接查询. 那么就要使用外连接查询了. 外连接分为左外连接和右外连接
1 左外连接
以join左边的表为主表,展示主表的所有数据,根据条件查询连接右边表的数据,若满足条件则展示,若不满足则以null显示.
可以理解为:在内连接的基础上保证左边表的数据全部显示
左外连接=内部连接+左边表中失配元组
语法
select [字段][*] from a left [outer] join b on 条件
练习:查询所有部门下的员工
SELECT * FROM dept as d LEFT OUTER JOIN emp as e on d.id = e.dept_id ORDER BY d.id;
2 右外连接
以join右边的表为主表,展示右边表的所有数据,根据条件查询join左边表的数据,若满足则展示,若不满足则以null显示
可以理解为:在内连接的基础上保证右边表的数据全部显示
语法
select 字段 from a right [outer] join b on 条件
查询所有员工所对应的部门
SELECT * FROM dept RIGHT OUTER JOIN emp ON emp.dept_id=dept.id order by emp.id;
3、子查询
1 什么是子查询
直观一点: 一个查询语句里面至少包含2个select
- 一个查询语句的结果作为另一个查询语句的条件
- 有查询的嵌套,内部的查询称为子查询
- 子查询要使用括号
- 子查询结果的三种情况:
子查询的结果是一个值的时候
子查询结果是单列多行的时候
子查询的结果是多行多列
2 子查询进阶
尽管子查询的语法很灵活,没有固定的写法.但是它也有一些规律.
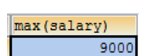
子查询的结果是一个值的时候
子查询结果只要是单个值,肯定在WHERE后面作为条件
SELECT 查询字段 FROM 表 WHERE 字段[= > < <>](子查询)
查询工资最高的员工是谁?
根据最高工资到员工表查询到对应的员工信息
SELECT * FROM emp WHERE salary=(SELECT MAX(salary) FROM emp);
查询工资小于平均工资的员工有哪些?
- 查询平均工资是多少
SELECT * FROM emp WHERE salary < (SELECT AVG(salary) FROM emp);
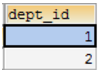
子查询结果是单列多行的时候
子查询结果只要是单列,肯定在WHERE后面作为条件
子查询结果是单列多行,结果集类似于一个数组,父查询使用IN运算符
SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
查询工资大于5000的员工,来自于哪些部门的名字
先查询大于5000的员工所在的部门id
再查询在这些部门id中部门的名字
SELECT dept.name FROM dept WHERE dept.id IN (SELECT dept_id FROM emp WHERE salary > 5000);
子查询的结果是多行多列
子查询结果只要是多行多列,肯定在FROM后面作为表
SELECT 查询字段 FROM (子查询) 表别名 WHERE 条件;
子查询作为表需要取别名,否则这张表没有名称无法访问表中的字段
- 查询出2011年以后入职的员工信息,包括部门名称
在员工表中查询2011-1-1以后入职的员工
查询所有的部门信息,与上面的虚拟表中的信息组合,找出所有部门id等于的dept_id
SELECT * FROM dept d, (SELECT * FROM emp WHERE join_date > '2011-1-1') e WHERE e.dept_id = d.id;
另一写法:内连接
SELECT * FROM dept join emp on dept.id = emp.dept_id where emp.join_date > '2011-1-1';
4、MySQL函数
4.1 使用MySql函数的目的
为了简化操作,MySql提供了大量的函数给程序员使用(比如你想输入当前时间,可以调用now()函数)
4.2 函数可以出现的位置
插入语句的values()中,更新语句中,删除语句中,查询语句及其子句中。
4.3 if 相关函数
1) if函数
语法
if(expr1,expr2,expr3)
说明: 如果 expr1 是TRUE,则 IF()的返回值为expr2; 否则返回值则为 expr3。if() 的返回值为数字值或字符串值,具体情况视其所在语境而定。
示例
练习1:获取用户的姓名、性别,如果性别为1则显示1,否则显示0;要求使用if函数查询:
SELECT uname, IF(sex, 1, 0) FROM t_user;

2) ifnull函数
ifnull(expr1,expr2)
说明:假如expr1 为 NULL,则 IFNULL() 的返回值为 expr2; 否则其返回值为 expr1。ifnull()的返回值是数字或是字符串,具体情况取决于其所使用的语境。
示例
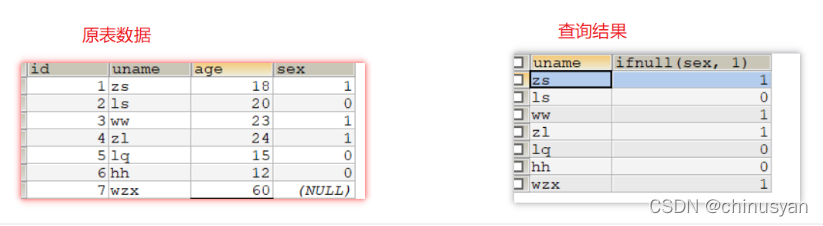
练习1:获取用户的姓名、性别,如果性别为null则显示为1;要求使用ifnull函数查询:
SELECT uname, IFNULL(sex, 1) FROM t_user;
4.4 字符串函数
1) 字符串连接函数(拼接)
字符串连接函数主要有2个:
| 函数或操作符 | 描述 |
|---|---|
| concat(str1, str2, …) | 字符串连接函数,可以将多个字符串进行连接 |
| concat_ws(separator, str1, str2, …) | 可以指定间隔符将多个字符串进行连接; |
练习1:使用concat函数显示出 你好,uname 的结果
SELECT CONCAT('你好,' , uname) FROM t_user;
练习2:使用concat_ws函数显示出 你好,uname 的结果
SELECT CONCAT_WS(',', '你好', uname) FROM t_user;
2) 字符串大小写处理函数
字符串大小写处理函数主要有2个:
| 函数或操作符 | 描述 |
|---|---|
| upper(str) | 得到str的大写形式 |
| lower(str) | 得到str的小写形式 |
练习1: 将字符串 hello 转换为大写显示
SELECT UPPER('hello'); -- HELLO
练习2:将字符串 heLLo 转换为小写显示
SELECT LOWER('heLLo'); -- hello
3) 移除空格函数
可以对字符串进行按长度填充满、也可以移除空格符
| 函数或操作符 | 描述 |
|---|---|
| trim(str) | 将str两边的空白符移除 |
练习1: 将用户id位8的用户的姓名的两边空白符移除
-- 表中数据是:' lb ', 使用trim后是: 'lb'
SELECT TRIM(uname) FROM t_user WHERE id = 8;
4) 子串函数(截取)
字符串也可以按条件进行截取,主要有以下可以截取子串的函数;
| 函数或操作符 | 描述 |
|---|---|
| substr()、substring() | 获取子串: 1:substr(str, pos) 、substring(str, pos); 2:substr(str, pos, len)、substring(str, pos, len) |
练习1:获取 hello,world 从第二个字符开始的完整子串
SELECT SUBSTR("hello,world", 2); -- ello,world
练习2:获取 hello,world 从第二个字符开始但是长度为4的子串
SELECT SUBSTR("hello,world", 2, 4); -- ello
4.5 时间日期函数
mysql提供了一些用于获取特定时间的函数:
| 函数或操作符 | 描述 |
|---|---|
| current_date() | 获取当前日期,如 2019-10-18 |
| current_time() | 获取当前时:分:秒,如:15:36:11 |
| now() | 获取当前的日期和时间,如:2019-10-18 15:37:17 |
4.6 数值函数
常见的数值相关函数如下表:
| 函数或操作符 | 描述 |
|---|---|
| abs(x) | 获取数值x的绝对值 |
| ceil(x) | 向上取整,获取不小于x的最小整数值 |
| floor(x) | 向下取整,获取不大于x的最大整数值 |
| pow(x, y) | 获取x的y次幂 |
| rand() | 获取一个0-1之间的随机浮点数 |
其它函数
last_insert_id()
查询最后一个自增长的id的值
5、存储过程
存储过程简单来说,就是为以后的使用而保存的一条或多条MySQL语句的集合。可将其视为批文件,虽然它们的作用不仅限于批处理。
5.1 为什么要使用存储过程
- 通过把处理封装在容易使用的单元中,简化复杂的操作(正如前面例子所述)。
- 由于不要求反复建立一系列处理步骤,这保证了数据的完整性。
如果所有开发人员和应用程序都使用同一(试验和测试)存储过程,则所使用的代码都是相同的。 - 简化对变动的管理。如果表名、列名或业务逻辑(或别的内容)有变化,只需要更改存储过程的代码。使用它的人员甚至不需要知道这些变化
这一点的延伸就是安全性。通过存储过程限制对基础数据的访问减少了数据讹误(无意识的或别的原因所导致的数据讹误)的机会。 - 提高性能。因为使用存储过程比使用单独的SQL语句要快。
- 存在一些只能用在单个请求中的MySQL元素和特性,存储过程可以使用它们来编写功能更强更灵活的代码
换句话说,使用存储过程有3个主要的好处,即简单、安全、高性能。
5.2 执行存储过程
MySQL称存储过程的执行为调用,因此MySQL执行存储过程的语句为CALL。CALL接受存储过程的名字以及需要传递给它的任意参数。
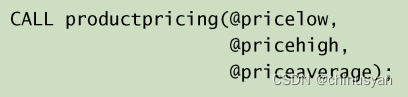
其中,执行名为productpricing的存储过程,它计算并返回产
品的最低、最高和平均价格。
存储过程可以显示结果,也可以不显示结果,
5.3 创建存储过程

此存储过程名为 productpricing,用CREATE PROCEDURE 语句定义。如果存储过程接受参数,它们将在()中列举出来。
此存储过程没有参数,但后跟的()仍然需要。
BEGIN 和 END语句用来限定存储过程体
存储过程实际上是一种函数,所以存储过程名后需要有()符号(即使不传递参数也需要)。
mysql命令行客户机的分隔符,默认的MySQL语句分隔符为
;

为恢复为原来的语句分隔符,可使用DELIMITER ;。
除\符号外,任何字符都可以用作语句分隔符
5.4 删除存储过程
存储过程在创建之后,被保存在服务器上以供使用,直至被删除。
DROP PROCEDURE
DROP PROCEDURE productpricing
如果指定的过程不存在,则DROP PROCEDURE
将产生一个错误。当过程存在想删除它时(如果过程不存在也
不产生错误)可使用DROP PROCEDURE IF EXISTS。
5.4.1 使用参数

关键字 OUT 指出相应的参数用来从存储过程传出一个值(返回给调用者)。MySQL支持IN(传递给存储过程)、OUT(从存储过程传出,如这里所用)和INOUT(对存储过程传入和传出)类型的参数。
存储过程的代码位于BEGIN和END语句内,如前所见,它们是一系列SELECT语句,用来检索值,然后保存到相应的变量(通过指定INTO关键字)
参数的数据类型 存储过程的参数允许的数据类型与表中使用
的数据类型相同。
注意,记录集不是允许的类型,因此,不能通过一个参数返回
多个行和列。这就是前面的例子为什么要使用3个参数(和3
条SELECT语句)的原因。
CALL productpricing(@priceLow, @priceHigh, @priceAverage);
变量名 所有MySQL变量都必须以@开始。
为了获得3个值,可使用以下语句:
select @priceLow, @priceHigh, @priceAverage;
5.5 建立智能存储过程
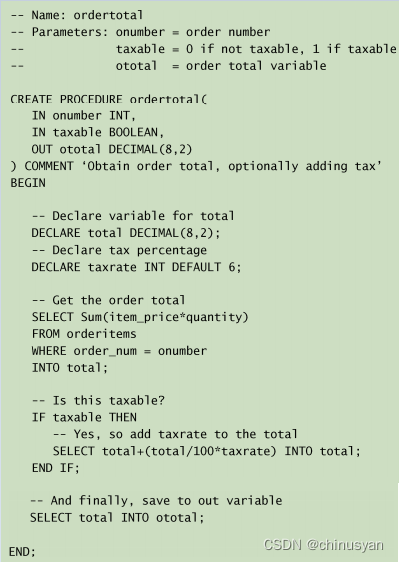
首先,增加了注释(前面放置 --)。在存储过程复杂性增加时,这样做特别重要。
添加了另外一个参数taxable,它是一个布尔值(如果要增加税则为真,否则为假)。
在存储过程体中,用DECLARE语句定义了两个局部变量。DECLARE要求指定变量名和数据类型,它也支持可选的默认值(这个例子中的taxrate的默认被设置为6%)。
SELECT语句已经改变,因此其结果存储到total(局部变量)而不是ototal。
IF语句检查taxable是否为真,如果为真,则用另一SELECT语句增加营业税到局部变量total。最后,用另一SELECT语句将total(它增加或许不增加营业税)保存到ototal。
COMMENT关键字 本例子中的存储过程在CREATE PROCEDURE语句中包含了一个COMMENT值。它不是必需的,但如果给出,将在SHOW PROCEDURE STATUS的结果中显示。
BOOLEAN值指定为1表示真,指定为0表示假(实际上,非零值都考虑为真,只有0被视为假)。
IF语句
IF语句还支持ELSEIF和ELSE子句(前者还使用THEN子句,后者不使用)。
5.6 检查存储过程
为显示用来创建一个存储过程的CREATE语句,使用SHOW CREATE PROCEDURE语句:
SHOW CREATE PROCEDUR ordertotal;
为了获得包括何时、由谁创建等详细信息的存储过程列表,使用SHOW PROCEDURE STATUS。
限制过程状态结果 SHOW PROCEDURE STATUS列出所有存储过程。为限制其输出,可使用LIKE指定一个过滤模式,例如:
SHOW PROCEDURE STATUS like 'ordertotal';
6、分组数据
涉及两个新SELECT语句子句,分别是GROUP BY子句和HAVING子句。
DISTINCT
一般只统计获取不同记录数
SELECT
COUNT( DISTINCT user_id )
FROM
my_table
6.1 过滤分组
规定包括哪些分组,排除哪些分组。例如,可能想要列出至少有两个订单的所有顾客。为得出这种数据,必须基于完整的分组而不是个别的行进行过滤。
WHERE过滤指定的是行而不是分组。事实上,WHERE没有分组的概念。














 1240
1240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









