






同Caffe的关系
- 完全兼容Caffe。Pluto基于开源库Caffe扩展而来,是Caffe的超集,完全兼容Caffe的配置和数据,使用过Caffe的同学几分钟就能用Pluto跑起多机多卡版程序。
- Pluto的单机核心代码同开源社区版本保持同步,所以开源社区提供的一些新特性我们能够迅速merge到Pluto里面
新特性
我们来源于Caffe,但同时根据我们的用户需求我们提供了一些Pluto独有的新特性,帮助用户在模型训练中提高效率。
- 多机多卡,通过并行计算提高计算和收敛速度。
- 数据读取提供多lmdb支持。开源版本只能从一个lmdb读取训练数据,Pluto提供支持从多个lmdb按概率(可配置)读取数据,可以更好的支持用户训练数据的增量更新,不会因为训练数据增加而重新制作lmdb文件。
- hdf5文件prefetch支持。因为hdf5文件读取时需要全部load进内存的特点,当以hdf5文件作为数据存储格式时数据读取时间同计算时间无法进行overlap。Pluto提供文件级的prefetch支持,通过独立线程在计算时preload下一份hdf5文件,缩短训练时间。
- Sequential learning支持。Sequence learning对于语音识别和自然语言处理中存在时序关联的数据进行处理建模拥有天然的优势。Pluto中提供的Sequence learning的相关支持,包括常用的RNN/LSTM以及双向的LSTM,可以高效准确的进行自然场景图片描述(如Image Caption)和自然语言处理中的相关建模任务。
- 多种同步模式支持。用户可以配置多卡间的同步轮数间隔,默认每轮同步一次;也可以配置按时间同步,即每张卡独立的迭代一段时间后同步一次,适用于资源竞争激烈或快慢机明显的环境。
- Sparse 数据格式支持。支持sparse格式的训练数据。
性能分析
实验环境
- GPU Device: Tesla K40m with 12GiB display memory, two cards in each box
- Network: InfiniBand, GPU direct
- cuDNNv2:open
Alexnet在Imagenet数据集上的实验结果
梯度平均
在每轮计算都做一次梯度平均,可以获得同单机一模一样的收敛结果,即acc57.1%,计算和收敛加速比如下:
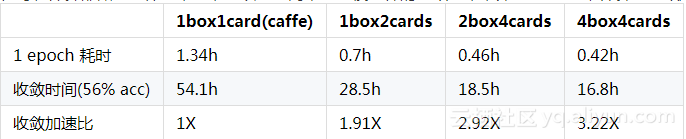
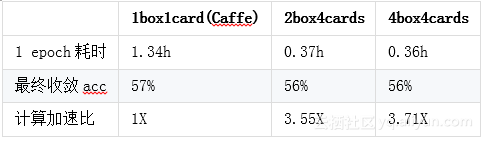
模型平均 每张卡各自计算若干轮后做一次模型平均,会 影响收敛结果 ,但是可以 提高计算加速比 ,结果如下:
收敛曲线


Googlenet在Imagenet数据集上的实验结果:
模型平均
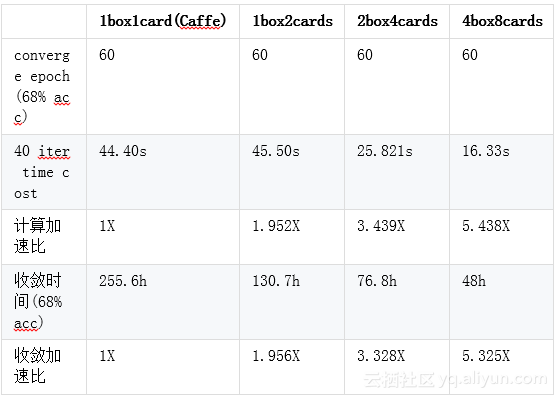
收敛曲线


如何使用
- 在阿里云机器学习平台PAI上,可以选择Caffe组件使用。
- 使用文档见: https://help.aliyun.com/document_detail/49571.html?spm=5176.doc42745.6.548.Dd4AFR#Caffe

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









