






下文总结于 2014-12-20
全排列
第一个算法需求:字符串的全排列。
说明:貌似这个算法题,面试的公司特别喜欢考。
SCALA版本:
object TestQuanPaiLie extends App {
quanpailie(Array.apply('a', 'b', 'c', 'd'), 0, true)
def quanpailie(str: Array[Character], index: Int, isPrint: Boolean) {
if(isPrint) printStr(str)
for (i <- index until str.length) {
var display = false
val tmpStr = copyStr(str)
if (i > index) {
val tmpC = tmpStr(index)
tmpStr(index) = tmpStr(i)
tmpStr(i) = tmpC
display = true
}
quanpailie(tmpStr, index + 1, display)
}
}
def printStr(str: Array[Character]) = {
str.foreach(c => print(c))
println
}
def copyStr(str: Array[Character]) = for (c <- str) yield c
}java版本:
public class JTestQuanPaiLie {
public static void main(String[] args) {
quanpailie(new char[] { 'a', 'b', 'c', 'd' }, 0, true);
}
public static void quanpailie(char[] str, int index, boolean isPrint) {
if (isPrint) {
printStr(str);
}
for (int i = index; i < str.length; i++) {
boolean isdisplay = false;
char[] tempStr = copyStr(str);
if (i > index) {
tempStr[index] = (char) (tempStr[index] ^ tempStr[i]);
tempStr[i] = (char) (tempStr[index] ^ tempStr[i]);
tempStr[index] = (char) (tempStr[index] ^ tempStr[i]);
isdisplay = true;
}
quanpailie(tempStr, index + 1, isdisplay);
}
}
public static char[] copyStr(char[] str) {
char[] tmpStr = new char[str.length];
for (int i = 0; i < str.length; i++) {
tmpStr[i] = str[i];
}
return tmpStr;
}
public static void printStr(char[] str) {
for (char c : str) {
System.out.print(c);
}
System.out.println();
}
}
优先队列、堆排序
这里介绍下堆,堆就是完全二叉树(构建一颗完全二叉树我们只需计算最后叶子节点的编号,插入就可以了,所以这个原理很重要,堆排序就是这么变种玩的),二叉树是个很好玩很神奇的数据结构,一阴一阳能解决不少问题。这里用堆来做优先队列,优先队列我们不一定非得全部排序才能玩,这样在数据很大的时候效率极低。但是堆可以说你数据巨大的时候它还能保持极快的效率,因为二叉树的节点个数是(2^n) - 1这个就像细胞分裂一样一个细胞分裂成两个两个分裂成四个,完全是指数级的。
堆如何实现优先队列,首先必须保证插入和删除时每个父节点的值都比孩子节点大(这里假设为递减的优先队列)且始终都是完全二叉树。
这里我们使用数组来表示二叉树(而不是链式的),这样具有较高的检索效率。如果第一个节点的编号是0以此类推,那么左孩子=编号*2 + 1;右孩子=编号*2 + 2; 父节点=(编号-1)/2;
SCALA版源码:
class PriorityQueue {
val heap = new Array[Integer](100)
var size = 0
def pop = heap(0)
def poll(): Integer = {
var i = 0
val head = heap(i)
size = size - 1
val last = heap(size)
heap(0) = last
heap(size) = null
val half = size >>> 1
while (i < half) {
i = (i << 1) + 1
val left = heap(i)
val right = heap(i + 1)
if (left == null) {
return head
}
val bigChirld = if (right == null || left >= right) {
left
} else {
i += 1
right
}
if (last < bigChirld) {
heap((i - 1) >>> 1) = bigChirld
heap(i) = last
} else {
return head
}
}
head
}
def add(v: Int) {
if (size == 0) {
heap(0) = v
size = size + 1
return
}
var i = size >>> 1
var index = size
while (index > 0) {
val node = heap(i)
if (node >= v) {
heap(index) = v
size = size + 1
return
} else {
heap(i) = v
heap(index) = node
}
index = i
i = i >>> 1
}
size = size + 1
}
}java版本:
class PriorityQueue {
Integer[] heap = new Integer[100];
private int size = 0;
public Integer pop() {
return heap[0];
}
public Integer poll() {
int i = 0;
Integer head = heap[i];
Integer last = heap[--size];
heap[0] = last;
heap[size] = null;
int half = size >>> 1;
while (i < half) {
i = (i << 1) + 1;
Integer left = heap[i];
Integer right = heap[i + 1];
if (left == null) {
return head;
}
Integer bigChirld = null;
if ((right == null) || (left >= right)) {
bigChirld = left;
} else {
bigChirld = right;
i++;
}
if (last < bigChirld) {
heap[(i - 1) >>> 1] = bigChirld;
heap[i] = last;
} else {
return head;
}
}
return head;
}
public void add(int v) {
int i = size >>> 1;
int index = size++;
while (index > 0) {
Integer node = heap[i];
if (node >= v) {
heap[index] = v;
break;
} else {
heap[i] = v;
heap[index] = node;
}
index = i;
i = i >>> 1;
}
heap[index] = v;
}
}
插入排序
先介绍下插入排序和shell排序
插入排序,这排序算法很简单但也有巧妙之处。
常规思路是,把第一个元素作为有序序列,然后从第二个开始取出来,在前面找到自己的位置,然后后面的元素往后挪动腾出空间,然后插进去以此类推。

但是也可以往后找插入点,这种方式能比较有想象力一些。
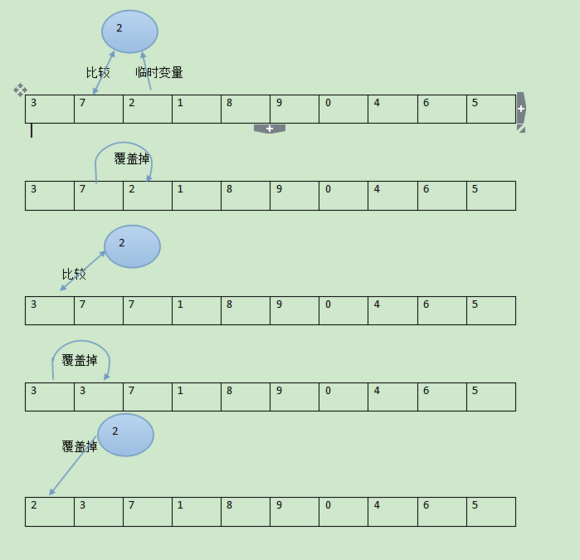
先看看常规思路的代码
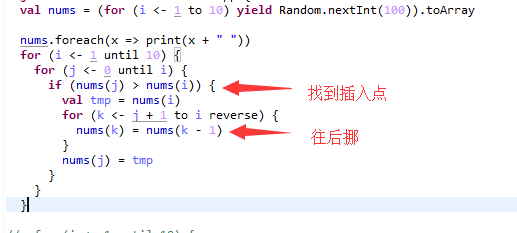
比较有想象力往后找的代码如下
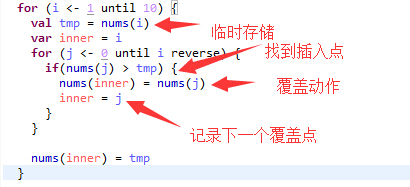
我们可以看到,插入排序最大问题是往后挪的过程,如果一个数组基本有序那么插入排序往后挪的过程就会少,那么效率就很高,但是若数组非常无序那么挪的动作就会很平凡这样就很慢了~
有了插入排序的基础,那我们来看看希尔排序是肿么回事呢?
shell排序既然是从插入排序而来,那么他做了什么优化让效率大大的提高了呢?
恩,也就是我们刚才提到的往后挪的动作让它变少,如何变少,那么有个极具想象力的动作办到了,我国教育死套,很多孩子墨守成规就很难有这样的想象力。说出来很简单,但是就是没几个想得到,到底什么方法这么吊?
希尔排序
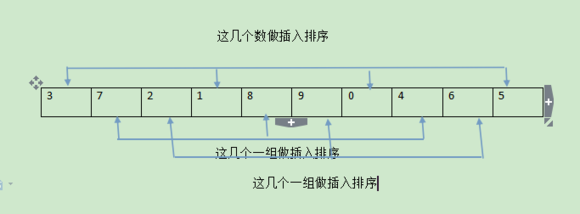
这样的结果就是,无序的数做了大跨度的移动,如果我们第一次使用一个较大的跨度然后逐渐减小跨度,那么数据到后面基本有序又没有挪动多少次,因为很多次挪动都是大范围的跨度,到最后我们只需要把跨度缩小到一,这样就能以很快的速度完成排序。。
请务必注意不管如何设计你的跨度最后一定要回到1的跨度,,如果你仔细研究会发现其实希尔排序的1跨度就是一个普通的插入排序而已。只是这个数组已经基本有序了所以很快。
下面来上代码,你会发现真的值做了很小的改动。
这里还有一个大师给的跨度数列的通项公式:h = 3*h + 1; 这个跨度公式被证明是排序很快的一组序列。
SCALA版:

通常Scala的代码要比java短,不晓得这次是不是依然如故。
Java版:
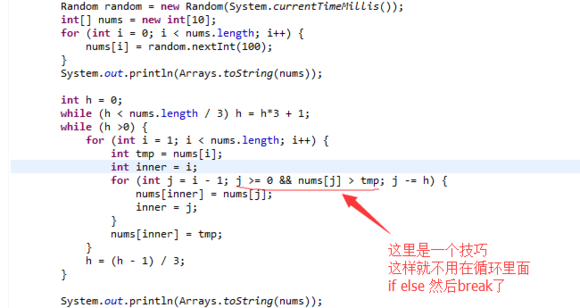
这里稍微解释下为什么
while (h < nums.length / 3) h = h*3 + 1;
是这样写的,条件为什么要除以3, 因为 h * 3 + 1了,长度除以3就肯定没问题了,或者这样也可以while (h*3 < nums.length) h = h*3 + 1;
这样就得到了最大的序列元素
后面还有条语句
h = (h - 1) / 3;
这是肿么回事呢
h3 = (h2 * 3) + 1 =》 h2 * 3= h3 - 1 => h2 = (h3 - 1) / 3
快速排序
介绍下快速排序。看这名字就晓得有点NB,敢叫快速。快速排序也算是对冒泡的一个改进吧,我们都知道冒泡是一个一个的比然后往上冒,一层一层的往上冒。但这样效率太低了,因为每次只能往前走一步,有没有办法让它尽可能的多走几步呢???
好比有人欠你100块钱,他每次只还你1块钱,隔两天还你一块钱,你心里肯定想:“你这SB敢不敢一次还清,你TM的10块钱一次也成啊”。
那么快速排序呢大多数情况下就是这样的,为什么说大多数时候呢这个后面再讨论。
在介绍快速排序前,我们来看下数组的划分。我们这里有一个需求就是把一个数组分为两部分,左边部分的数字比右边部分的小中间个元素呢就在他们之间。
实现这个需求的办法肯定有很多,那我这里有个一个方式供给大家参考:
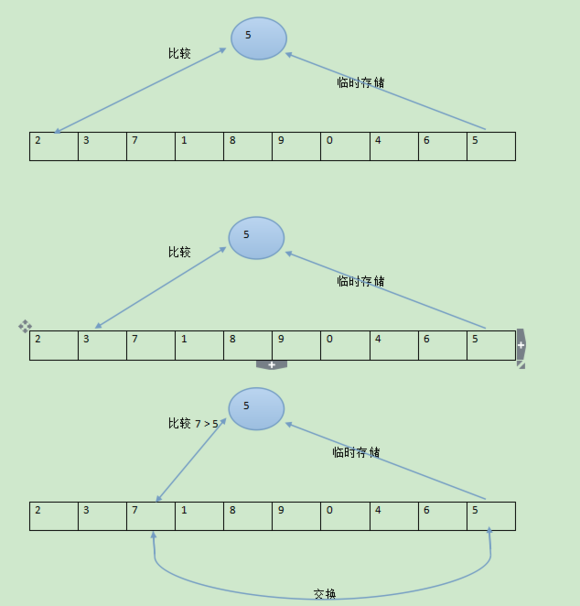
那刚才呢,我们看到了左边的一个划分情况,这下我们来看下右边的划分情况
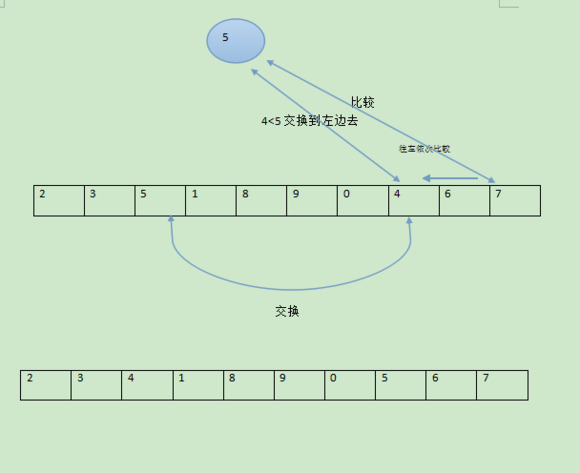
这个过程就是首先拿出最右边的一个数作为中间元素,先从左边扫描如果发现比它大的那么果断交换到右边去,此时停止左边的扫描开始右边的扫描,同样的道理发现比中间元素小的值马上果断交换到左边去,然后又开始左边的扫描如此往复。直到左边和右边两个指针相遇。
下面我们来看下关于划分代码的实现:

好划分的需求我们实现了,我们再来讨论快排和划分有什么关系呢?
我们试想一下,我一次划分就把数组分为了两部分左边小于右边,那么我在把左边和右边的继续划分包括他们划分出来的子分组都通通划分是不是到最后不能划分了这个数组就有序了呢~~恩,这就是快速排序啦。。。说来高大上,其实就是不停的划分知道不能划分为止。
那,这样不断的划分我们很容易想到的就是递归,那这里我们看看递归如何实现的:
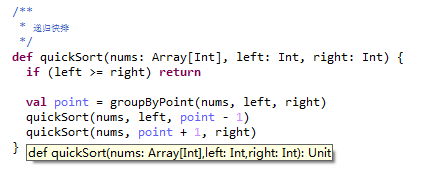
恩代码相当简单,但是有一个问题,如果数组很大很大,这样递归也不是个办法啊,我们都知道JVM的stack是有上限的虽然我们在跑JVM的时候可以指定这个区域的大小但也不能无底线无节操吧~~~~那这个区域既然有限是不是会OOM呢?啊是必须的啊~~~那么问题来了,我们如何才可以避免这样的OOM呢?那么这个问题后面再说,留给你思考下,你觉得如何实现?
刚才说了,大多数时候快速排序是很快的,下面我们来聊聊为什么。
快速排序快速排序,它一定很快吗???啊不一定,没有最NB的,只有最合适的~~~有的人总喜欢说C/C++哪里哪里NB比java好多啦,然后java阵营的有的又说你C++又如何如何了。这种争论嘛搞好耍还可以,你要认真那就已经错了~~~~任何语言都有它的优缺点在特定的环境下它就是好的。找媳妇儿也是,我们不找最漂亮的,但一定找最合适的这样生活才舒服~~
好,来看快排。我们试想下一个已经有序的数组丢给快速排序算法会有什么情况呢,每次划分都是1和n-1两组(你表示元素个数),那这里我们给以推导出一个公式
T(N) = T(N-1) + 1;
这样递归下去我们其实可以发现这个就是一个等差数列我们可以求和公式得到和,那么它的时间复杂度我们也可以得到是
O(((1 + n) / 2) * n + n) 约等于O((n/2)^2) 也就是 O(n^2)
靠着效率也太低了吧,是的,如果快速排序的每次划分都是划分为1和n-1那么它效率极差,所以说嘛,没有最好的只有最合适的,一个基本有序的还不如直接用插入排序呢~~~
那么问题来了,我们如何避免这种最坏的情况发生呢?
这里有一个办法就是如果被划分的元素个数大于3的话,我分别从最左边中间和最右边取3个元素,选出中间大小的一个元素作为划分的基准数,这样呢就可以避免最坏的情况发生了~
好,回过头来,我们在来看看刚才那个OOM的问题,哦你不信啊,那你试一试一个大数组吧十几万应该够了吧,不够你再加加。
那快速排序用非递归咋实现呢,它本身就是一个递归思想要我用非递归实现也太难为人了吧,嘿,但是还真有办法,这个办法呢,其实在很多情况下是一个很好的编程思想,它不单单可以把快排改成非递归,还可以把所有递归都改成非递归。。。。如何改?
递归改循环
JVM的函数调用递归循环也是类似道理
其实这个思想来自编译器和计算机体系结构,计算机如何处理递归的呢?想知道吗?恩,相知的我告诉你,不想知道的关掉
我们的程序每一次方法调用的时候其实CPU会执行一个方法调用指令,这个指令会把当前CPU的所有信息都入栈,到底什么信息建议你看看汇编语言程序设计。然后当方法退出时就会把入栈的信息出栈再接着执行下面的指令。
到这里我们其实已经可以推测出,我们的递归其实不断的入栈直到有一个调用函数退出时然后栈里的东西再POP,那递归的底层也就是这个样子,不过JVM有他自己的封装但是也大同小异,JVM有一个栈空间就用来做这个事情的,顺便带一句你进入方法时你的所有局部变量包括形参都被放在了栈里,方法退出时栈指针移动所有的局部变量都成了孤儿,所有局部变量空间分配那是相当快的。
好,我们的快速排序递归改成循环也这么干,我把一些必要的信息都入栈下一次循环在POP出来那就和递归差不多了吗~
我们来看看代码如何实现:
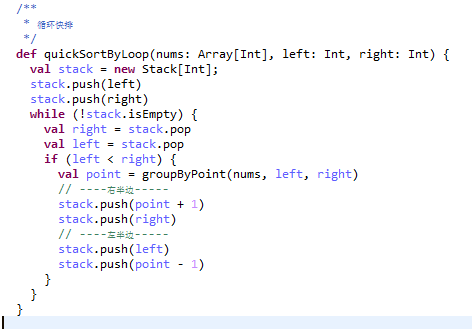
OK,这下我们不怕栈空间OOM啦,只要堆够使,你要多达数组我们都能给你排~
刚才贴了很多SCALA的代码,下面完整贴出java代码:
















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









