






Big Data Analytics
Is the process of examining large data sets to uncover hidden patterns, unknown correlations.
Big Data Analytics Types
Batch Analytics
Analytics based on the data collected over a period of time; Using historical data
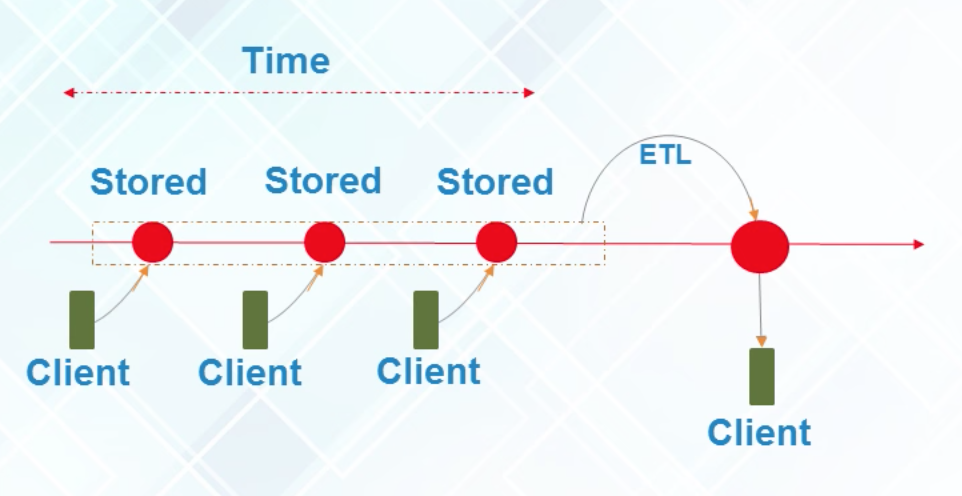
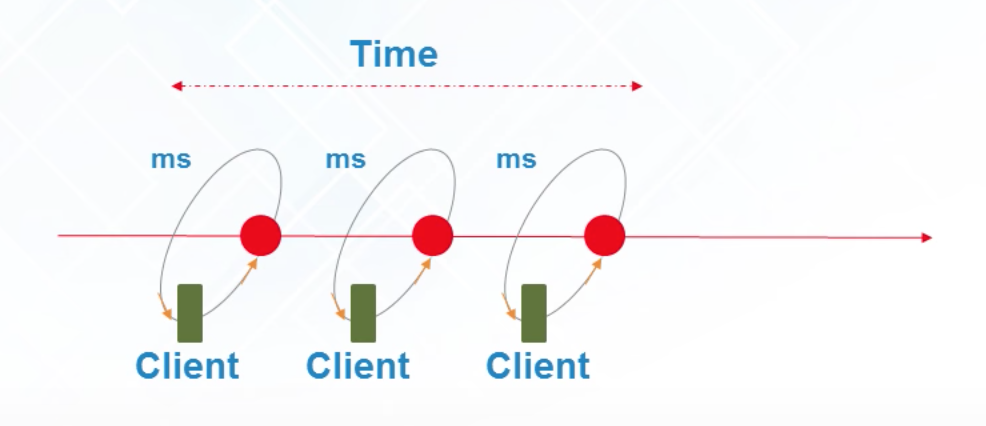
Real-Time Analytics
Analytics based on immediate data for instant result
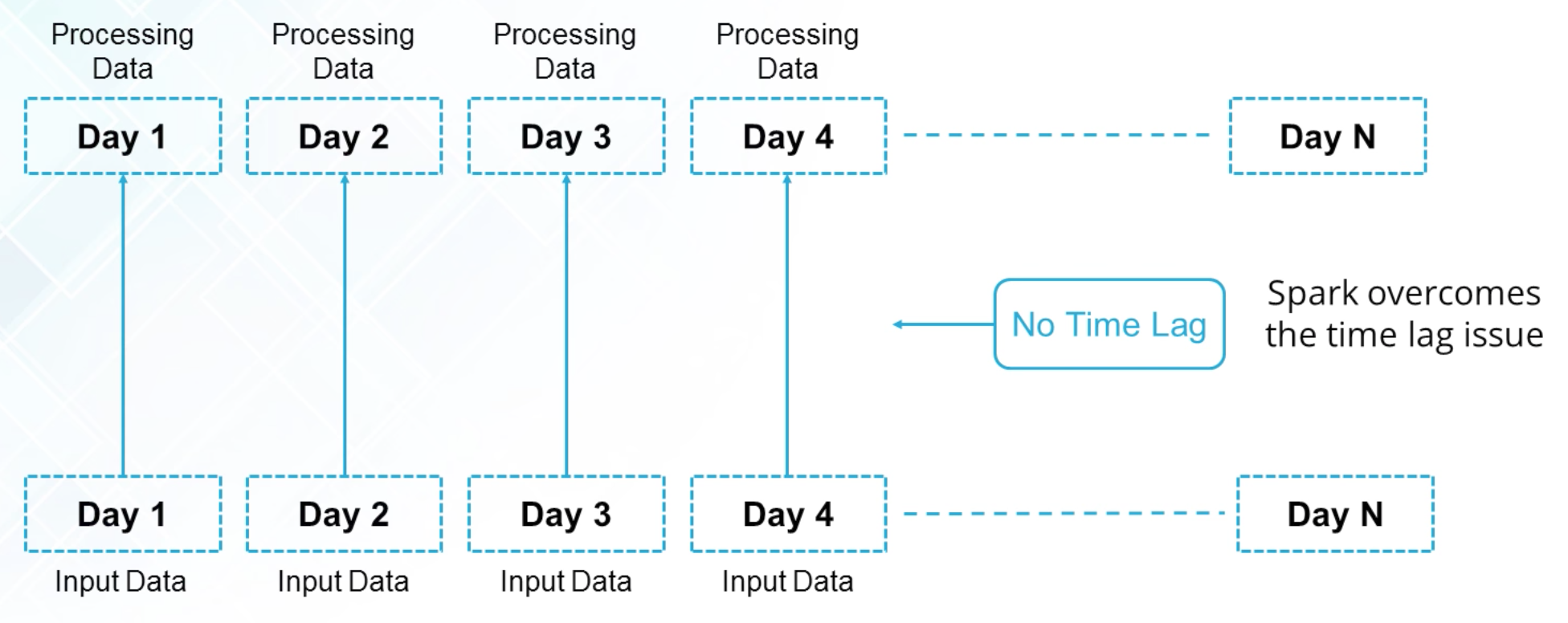
Spark v.s. Hadoop


Hadoop is used for batch processing.
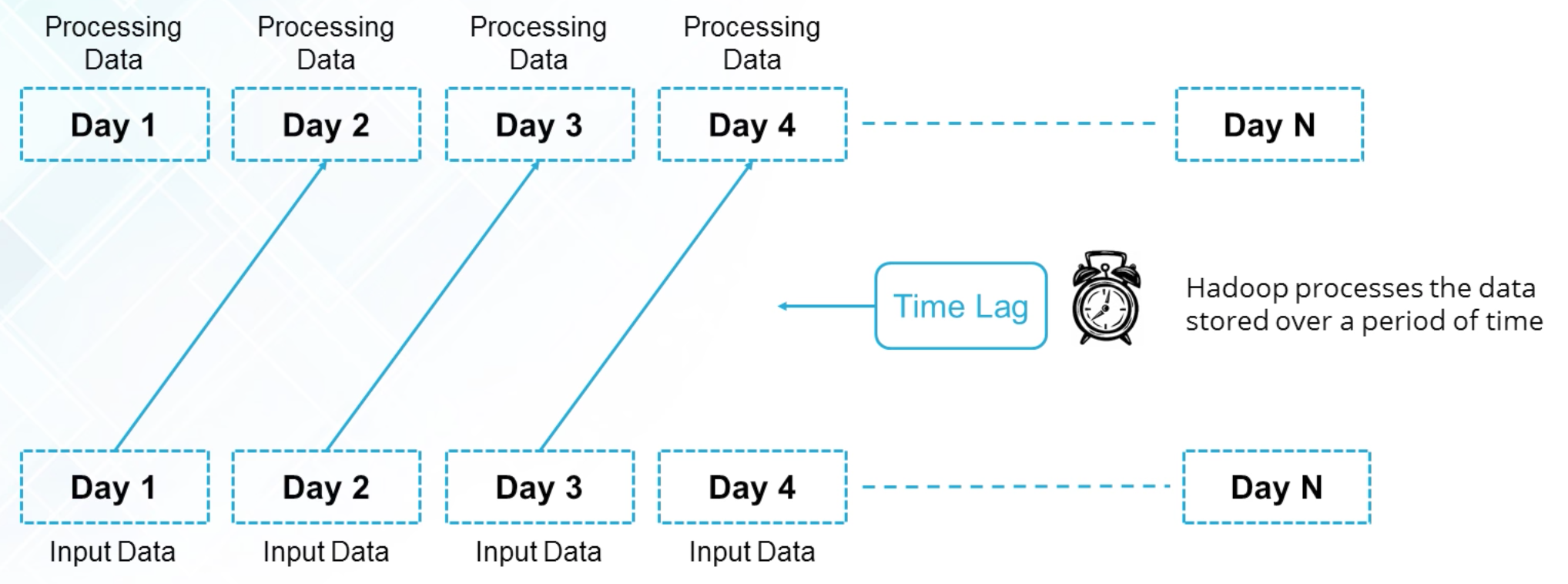
Spark can be used for both batch processing and real-time processing.
MapReduce Challenges
- Reading 128M data from Disk
- Writing result back to Disk
- Result Sent to Reduce over Network
- Reducer Save the result to Disk
Spark Solution
- RDD = Resilient Distributed Data; (Resilient = Reliable); Immutable (Not able to change)
- RDD to create another RDD (Transformation)
- RDD to get the result (Action)
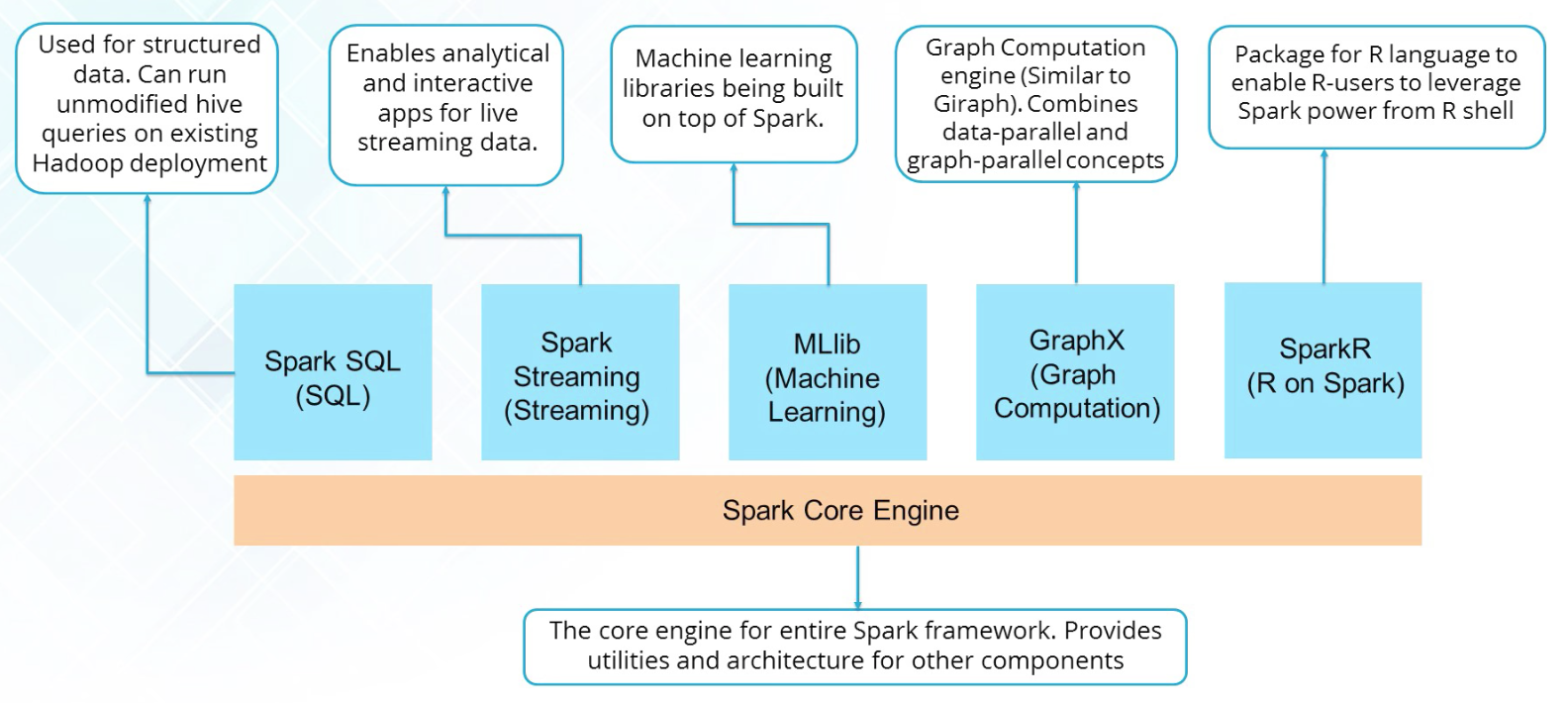
Spark Features
- Speed: in-memory computation.
- Polyglot: Java, Scala, Python, R.
- Advanced Analytics:
- Hadoop Integration
- Machine Learning: Mahout (Hadoop) -> MLib (Spark)
DAG
Directed: only a single direction
Acyclic: no looping
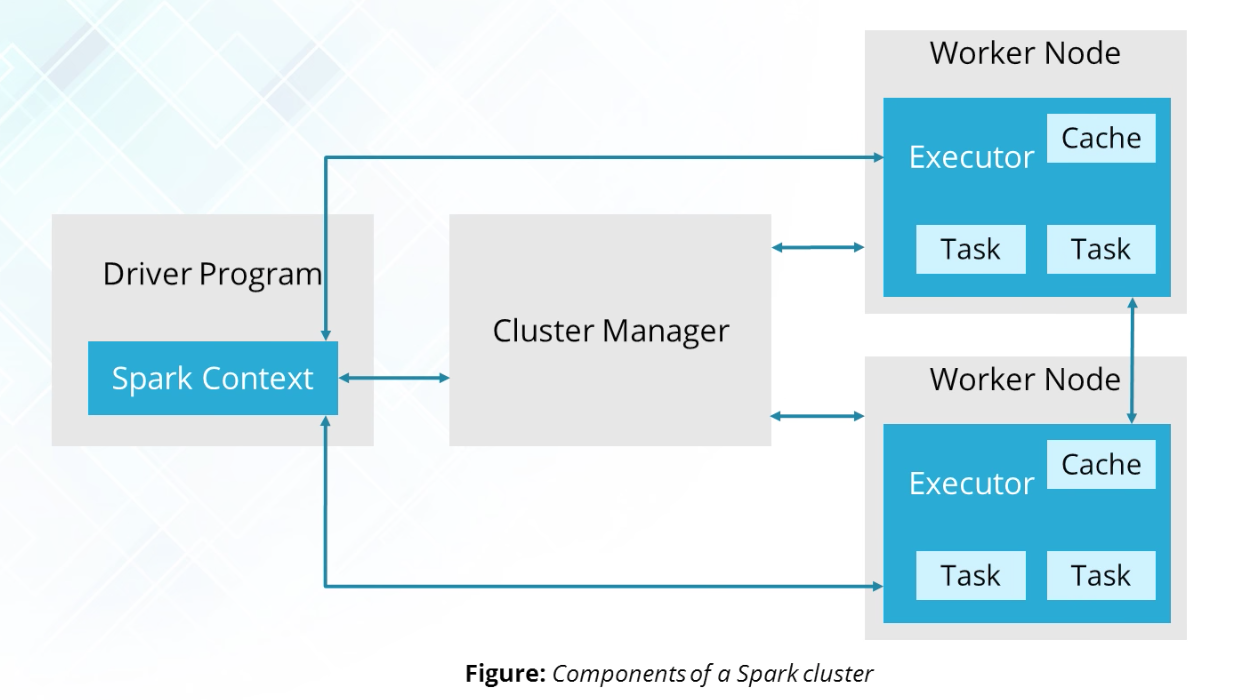
Structure
Driver
- Broadcast
- Take
- DAG
Executor
Shuffle
RDD
- A set of data that can not change
- Replay is import
- In Memory
- Many Caching Options
- DataFrame
- RDD[Row] with a Schema
DAG
One way map flow control, that doesn't reverse back. Source, Transformation, RDD, Action;
Action
- count
- take
- foreach
Transformation (build the DAG, but doesn't execute until the question is asked i.e. action)
- Map
- ReduceByKey
- GroupByKey
- JoinByKey
Flume Java
do distributed programming with the same code you could do non-distributed programming
// setting up SparkContext
val conf = new SparkConf().setMaster("local[2]")
val sc = new SparkContext(conf)
// RDD Read this file for me into
val line = sc.textFile(path, 2)
// RDD Split each line based on space
val words = lines.flatMap(_.split(" "))
// RDD (word, 1), i.e. tuple
val pairs = words.map(word => (word, 1))
// Reduce By Key to get the aggreated value of each key
val wordCounts = pairs.reduceByKey(_+_)
// Local Collection
val localValues = wordCounts.take(1000)
localValues.foreach(r => println(r))
Managing Parallelism
- Too many sub-tasks lead to excessive amount of start/shutdown tasks;
- Skew - most of the tasks go to one machine (joining on a null value;
- Hash -> Mod and Salt.
- Cartesian Join
- Nested Structures
- Windowing
- ReduceByKey
- Repartitioning















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









