






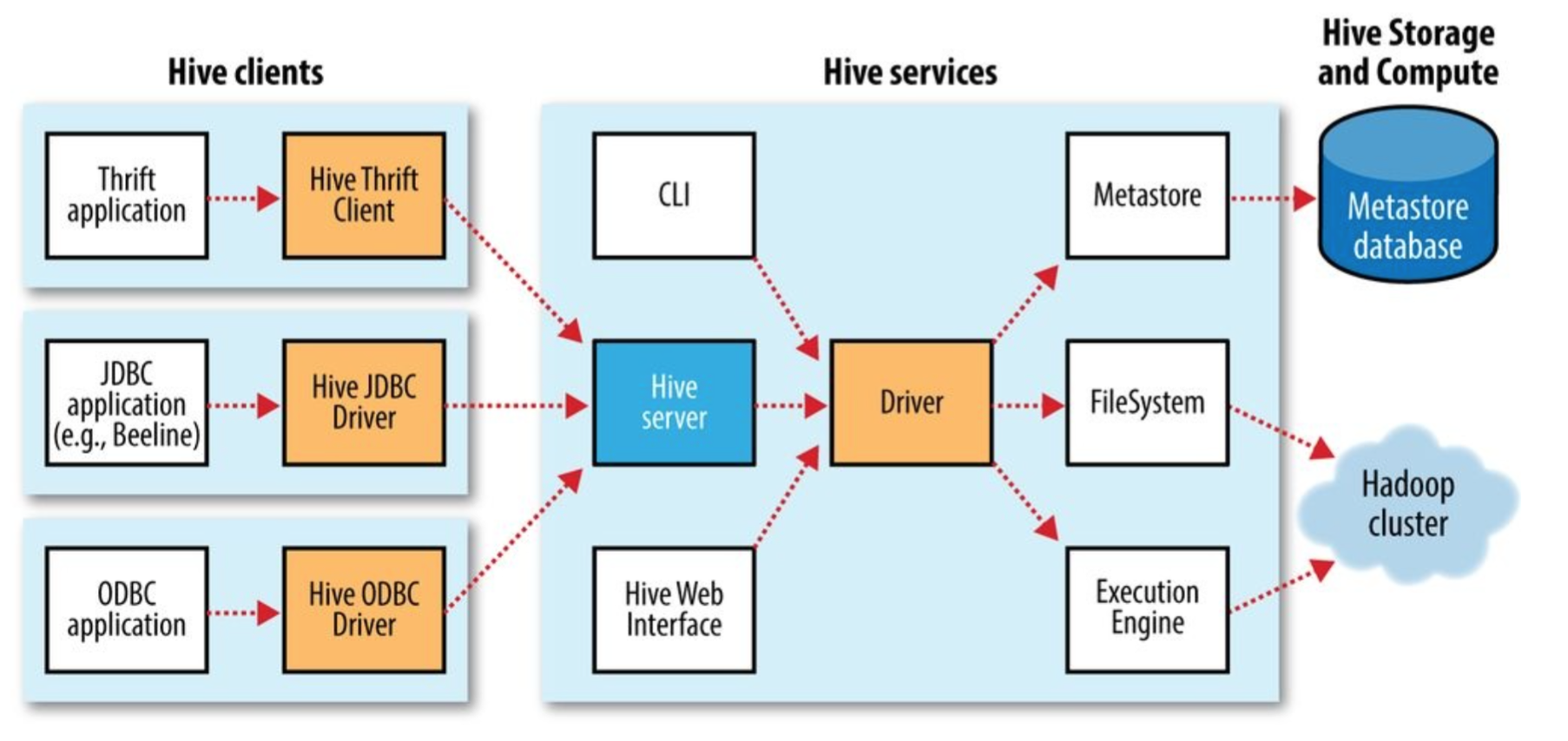
Hive Service
Hive Shell/CLI, beeline, HiveServer2, Hive Web Interface, jar, metastore.
Hive Shell
The primary way to interact with Hive by issuing command in HiveQL.
- %hive
- hive> hiveql ...
- %hive -f 'script'
- %hive -e 'hiveql'
HiveServer2
Run hive as a server exposing a Thrift service, enabling access from a range of clients written in different languages.
Hadoop Cluster
FileSystem
A Hive table is logically made up of the data being stored and the associated metadata describing the layout of the data in the table.
Data resides in Hadoop filesystem, which includes local filesystem, S3 and HDFS.
Metadata is stored separately in a RDBMS, which is default to Derby
Execution Engine
- hive.execution.engine=mapreduce, tez, spark;
- MapReduce is the default. Both Tez and Spark are general DAG engine that provides more flexibility and higher performance than MapReduce.
Resource Manager
- default to local job runner.
- yarn.resourcemanager.address.
Metastore
The central repository of Hive metadata, which is divided into two pieces:
- metadata service: by default, it's running in the same JVM as Hive
- metadata store: by default, it uses embedded Derby database backed by the local disk, which only allows one user to connect at a time.
Configuration
Precedence hierarchy of configuring Hive
- The Hive set command (hive>)
- The command line -hiveconf option
- hive-site.xml and Hadoop site files
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- Hive default and Hadoop default
- core-default.xml
- hdfs-default.xml
- mapred-default.xml
- yarn-default.xml
Table
Create Table
----- MANAGED TABLE -----
-- data is moved to Hive Warehouse
CREATE TABLE table_name (
field1 type1,
field2 type2,
field3 type3,
...
)
----- EXTERNAL TABLE ----
-- data remain as is, and not moved
CREATE EXTERNAL TABLE table_name (
field1 type1,
field2 type2,
field3 type3,
...
)
LOCALTION 'path'
----- STORAGE FORMAT ----
-- default : TEXTFILE,
-- row based binary: AVRO, SEQUENCEFILE,
-- column based binary: PARQUET, RCFILE, ORCFILE
STORED AS TEXTFILE
----- ROW FORMAT ------
-- only needed for TEXTFILE: DELIMINATED, SERDE
ROW FORMAT DELIMINATED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
....
)
----- STORAGE HANDLER -----
-- non-native storage, for example, HBase
STORED BY Load Data
----- LOAD DATA -----
LOAD DATA
LOCAL INPATH 'path to source file'
-- replace existing table
[OVERWRITE]
-- copy file to $HIVE/warehouse/table_name/
INTO TABLE table_name
----- IMPORT DATA -----
-- at creation
CREATE TABLE target_table (...)
AS
SELECT field1, field2 ...
FROM source_table
-- post creation
INSERT [OVERWRITE] TABLE target_table
[PARTITION (dt=value)]
SELECT fiel1, field2 ...
FROM source_table
-- one source to multiple targets
FROM source_table
INSERT [OVERWRITE] TABLE target_table1
SELECT ...
INSERT [OVERWRITE] TABLE target_table2
SELECT ...Others
Partition and Bucket
A way of coarse-grained parts based on the value of a partition column, such as a date. Using partitions can make it faster to do queries on sliced data.
--
CREATE TABLE log (ts BIGINT, line STRING)
PARTITIONED BY (dt STRING, country STRING)
--
LOAD DATA
LOCAL INPATH 'path to source'
INTO TABLE log
PARTITION (dt='2001-01-01', country='GB') 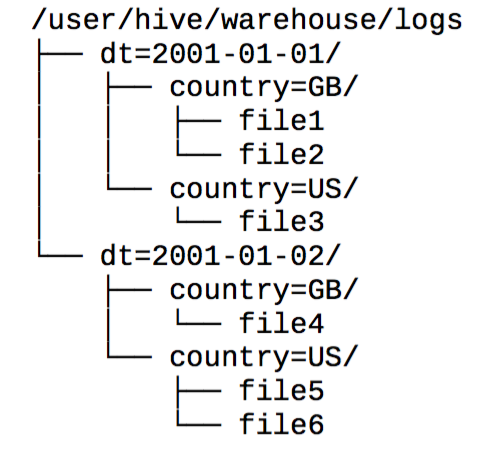
Query
Sorting and Aggregation, MapReduce Scripts, Subqueries, Views, Joins
- Inner Joins
- Outer Joins
- Semi Joins
- Map Joins
User Defined Function (UDF)
UDF and UDAF.















 2108
2108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









