






全文共3951字,预计学习时长8分钟

F. Scott Fitzgerald《了不起的盖茨比》封面,第一版,1925年
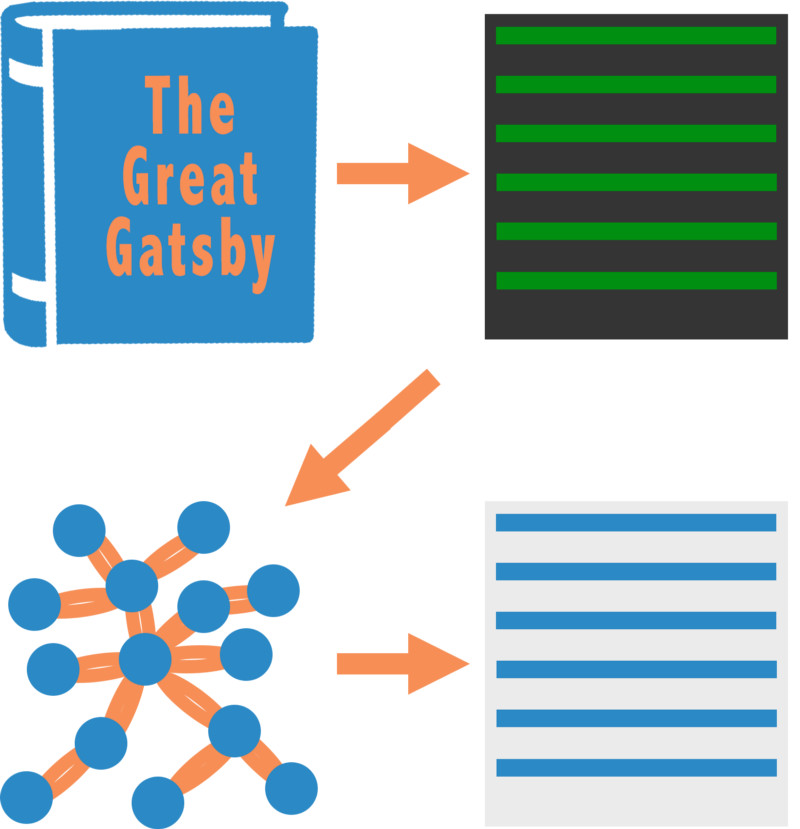
对美国的高中生来说,如果每一个高一新生在英语课上都有一项相同的作业,那这项作业一定是写一篇关于《了不起的盖茨比》的大意总结。《了不起的盖茨比》是一部引人入胜的文学作品,它的中心主题贯穿于社会与阶级、财富与地位、过去与现在。由此可见,对于一个高中生来说,写一篇关于这部小说的既简明又有说服力的总结并非易事。
在本文中,我们将使用自然语言处理(NLP)中的一些方法来总结《了不起的盖茨比》。自然语言处理是人工智能和机器学习的一个子领域,其分析领域为计算机如何处理和理解自然语言通信方法(例如书面语言)。这些术语可能听起来有些高深莫测,但是其基本概念还是容易理解的。

清除与整理
在做总结之前,首先需要获得这本书。所以,我们拿到了一份由澳大利亚古登堡项目所提供的该书的副本。接下来,第一步需要删除书中的停用词,即the、and、in、for、an等词。要写出格式良好的句子,使用停用词是必需的,但它们却并不为句子增加任何容易辨别的含义,且它们会影响词频的分析。所以,我们将使用此处的停用词列表。第二步,将把《了不起的盖茨比》分解为(键,值)对的映射。映射中的键是完整的句子(包含停用词和所有内容),而值表示已清除版本的数组。
停用词列表传送门:https://gist.github.com/sebleier/554280


具有余弦相似性的马尔可夫链
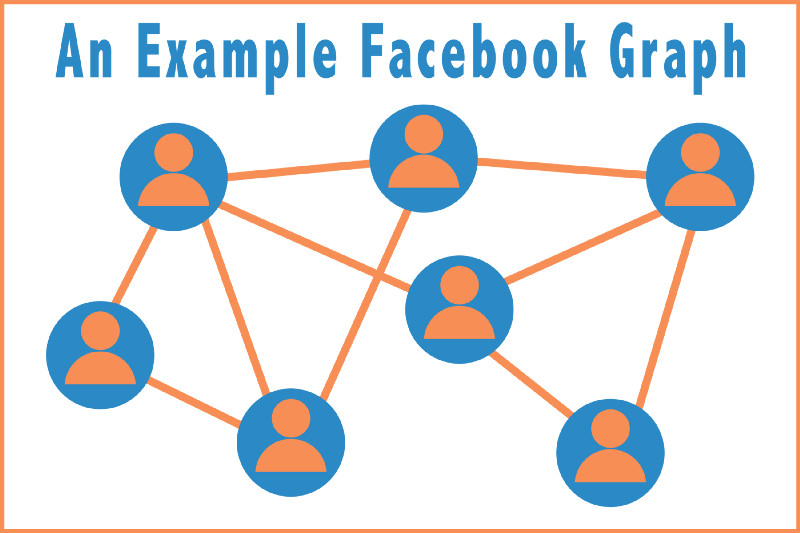
就算对于不熟悉图论的人来说,理解这个概念也是十分简单的。初等图由两部分组成:节点和边。节点代表现实世界中的一个概念,如人、电话号码或城市等。边则是两个节点之间的连接。如下图所示,Facebook就是一个常见的图形例子。图中的这些节点就代表Facebook用户。如果两个Facebook用户是朋友,那么这两个节点之间就会有一条边。
为了实现目标,可把《了不起的盖茨比》也表示为这样一个图,每个句子都代表一个节点。两个节点之间就会有一条边,而这条边就等于它们的句子相似性(对于这一点我们将在下文进一步介绍)。但是在做这件事之前,我们要明白,这种表示法为什么会有用呢?
这种图示实际上是将这本书表示为一个马尔可夫链。马尔可夫链是一种概率模型,通过定义从一种状态到另一种状态的转换概率来描述一系列状态。
比如,假设想用马尔可夫链来表示我开车到达的地点。那么,先假设我只开车往返于4个地点,即家、工作、商店和健身房,每个地点我都有可能开车到达。下面以图示来说明。如果节点之间没有连接,则开车往返于两个地点之间的概率为0%。例如,在下图中,我从不开车直接往返于商店与健身房,而是往往先回家一趟。
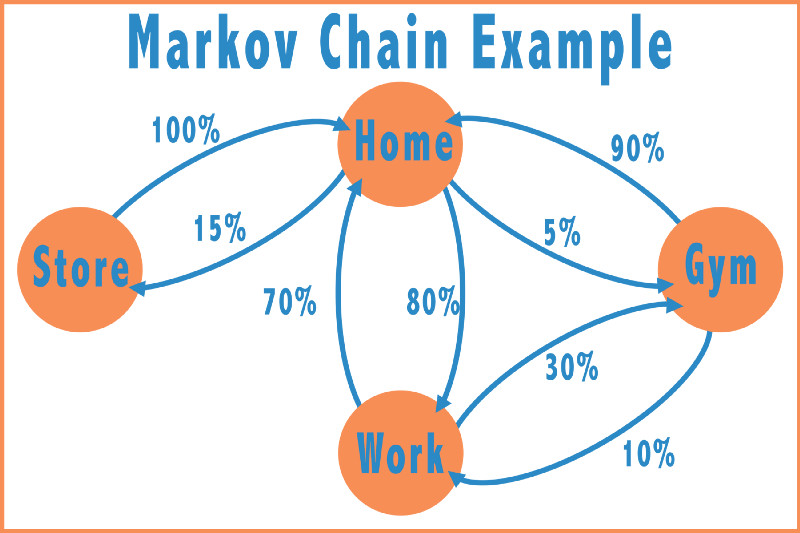
通过以上的马尔可夫链,可以得出我可能位于的任何给定地点的平稳概率。从上图中直观来看,在任何给定时间内,我最有可能是在家。这是因为有很多节点以极高的概率指向了家这个位置。
现在,让我们回到《了不起的盖茨比》上来。同理,将两个句子之间的转移概率定义为两个句子之间的余弦相似度。然后我们就可以获得该马尔可夫链的平稳概率分布。其中,在图中有着最多连接的节点就是具有最高平稳概率的句子。如在下面的示例中,节点A可能具有最高的平稳概率。
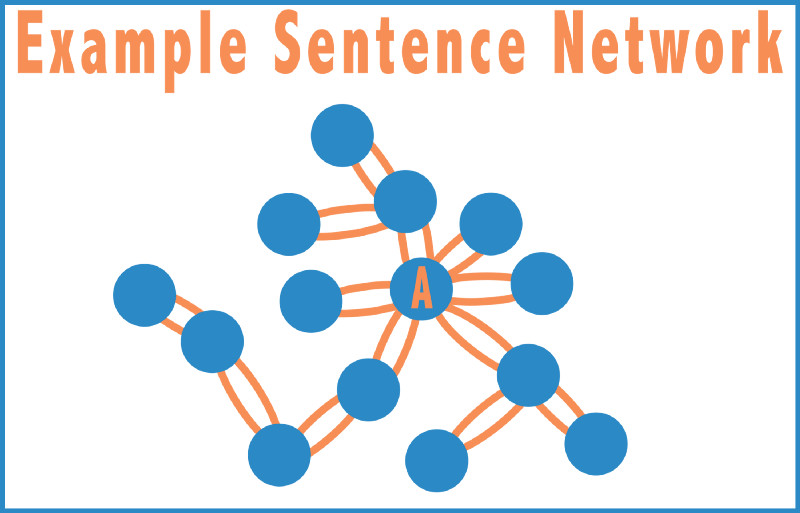
由此可见,高度连接的节点具有高平稳概率。而在这本书中,这样的节点就能代表一个关键主题的总结,因为这些节点与许多句子之间有着很高的相关性。但是,在我们说得太远之前,需要定义什么是余弦相似性。
假设这里有两个句子—“Jack and Jill went up the hill”和“Jill and Jack run down the hill”。余弦相似性就将这两个句子视为词的向量,并使用下面的公式计算它们的重叠度。余弦相似将计算两个词汇向量的点积,并将其除以每个向量大小的积。

理解这些之后,准备进行下一步了。我们将把图表示为一个矩阵。索引(x,y)处的值将是句子x和句子y之间的余弦相似性。该值是句子x和句子y之间的转换概率。使用这些转换概率来获得每个节点的平稳概率。
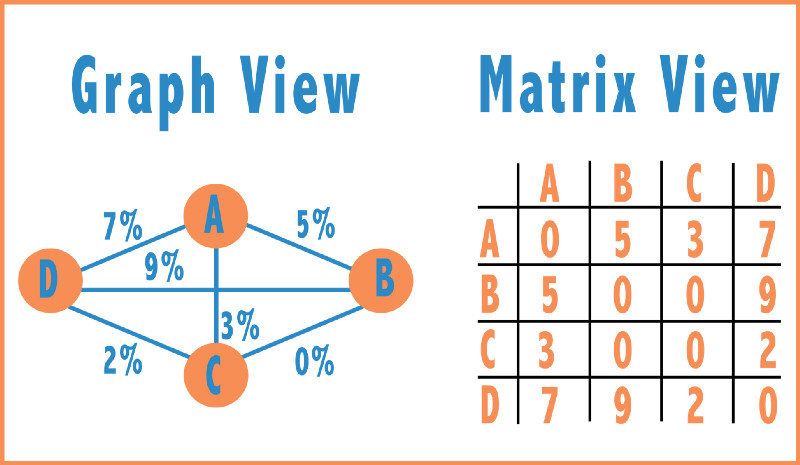
在马尔可夫链中获得平稳概率是相对简单的。可以重复地将转移概率矩阵相乘,直到达到一个稳定状态—即当所有转移概率都收敛到单个值时。除此之外,更有效的解决方案是使用左特征向量。
既然已经达到了一个稳定状态,就可以寻找最高概率值了。以下,就是具有最高稳态概率的句子。
"I'm Gatsby," he said suddenly.
--------------------------------------------------
"You two start on home, Daisy," said Tom. "In Mr. Gatsby's car."
--------------------------------------------------
"I told you I went there," said Gatsby.
--------------------------------------------------
"I want you and Daisy to come over to my house," he said, "I'd like to show her around."
--------------------------------------------------
She had told him that she loved him, and Tom Buchanan saw. He was astounded. His mouth opened a little and he looked at Gatsby and then back at Daisy as if he had just recognized her as some one he knew a long time ago.
现在,就来到了数据科学中最有趣的部分——得出了数据并不支持的结论。来评价一下下方得出的摘要吧。
In our last sentence, Daisy tells Gatsby she loves him and Tom Buchanan, her husband, sees. This sentence captures the complex relationship between Gatsby, Daisy, and Tom. In our fourth sentence, we see Gatsby wanting to show Daisy around his house. He’s convinced Daisy will want to be with him if she sees that he is now rich and successful. This captures Gatsby’s struggle to obscure his past with his current success, a central theme in the novel. And our first sentence captures the iconic moment of Gatsby introducing himself. Our model has done it! We have summarized The Great Gatsby!
(上述内容翻译如下:在最后一句中,黛西告诉盖茨比她爱他,但她的丈夫汤姆·布坎南看到了这一切。这个句子描述了盖茨比、黛西和汤姆三人之间复杂的关系。在第四句中,我们看到盖茨比想带黛西参观他的房子,他相信黛西在看到他现在的富有与成功之后,会愿意和他在一起。这一点反映了盖茨比为了用现在的成功来掩盖自己的过去而进行的斗争,而这正是小说的中心主题。并且,我们第一句就抓住了盖茨比进行自我介绍的标志性时刻。我们的模型成功了!我们成功总结了《了不起的盖茨比》!)

来源:《了不起的盖茨比》华纳兄弟2013
分析是如何得出这般总结的呢?其中的方法再简单不过,只需要跳过、跳过、再跳过。但根据之前的数据,是绝不会得出上述结果的。因为我们的方法是十分强大的,分析是经过深思熟虑的。但是上述结论的得出也由于引入了很多外部知识。
强调这一点并不是为失败开脱,而是要认识到这种方法的局限性。我们可以合理地得出结论,即盖茨比、黛西和汤姆是相关的人物,且盖茨比和黛西之间存在着某种关系。的确,我们找到了一些关键点,但还远远不能得出一个完整的总结。

展望未来
当然,我们可以通过一些方式来改进方法,主要是围绕如何确定句子相似性。比如,可以使用TF*IDF公式来计算句子中哪些单词是最相关的,并对它们进行相应的加权。以及,在计算余弦相似度时,不要只考虑严格的相等性,也要考虑词义相似但拼写不同的单词(例如,高兴和兴高采烈)。如果想更大胆一点,还可以使用先进的主题模型,如隐含狄利克雷分布模型(LDA)。
自动总结分为两个主要领域—提取方法和抽象方法。以上所讨论的一切都使用的是提取方法,即试图从文本本身中提取相关信息。但这种方法产生出来的摘要是不尽人意的,没有人会这么写。人类的思考方式是,先理清概念,再归纳总结,再考虑模式,最后产出结果。这是一种抽象的方法。为此,我们需要运用计算机科学中最流行的一个概念:深度神经网络。
代码传送门:https://github.com/andrewjoliver/NLPSummarization/tree/master/src
众所周知,清理数据和计算邻接矩阵是需要一定时间的,但如果使用Jupyter笔记本,则能一次性快速运行。并且,其方法的定义及代码结构都与这篇文章所讲到的类似,因此理解起来也相对容易。
留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









