






一、为什么表数据删掉一半,表文件大小不变
1、参数 innodb_file_per_table 设置数据存放位置:单独文件里还是共享表空间里;
2、数据删除流程:
delete 命令其实只是把记录的位置,或者数据页标记为了“可复用”,但磁盘文件的大小是不会变的。也就是说,通过 delete 命令是不能回收表空间的,可以复用但是没有被使用的空间好像‘空洞’;
不止是删除数据会造成空洞,插入数据也会;
更新索引上的值,可以理解为删除一个旧的值,再插入一个新值。不难理解,这也是会造成空洞的。
3、重建表
你可以使用 alter table A engine=Innodb;
在重建表的过程中,在原表上不能有数据插入,5.6后online 可以 ,引入row_log;
4、 online 和 inplace
二、count(*)为什么这么慢
1、为什么使用 innodb ,并发、数据安全、事务;
2、show table status TABLE_ROWS 采样获取 误差较大(30% - 40%);
3、用缓存系统保存计数;
4、用mysql 保存计数;
5、count(*) >= count(1) > count(id) > count(field)
三、 order by 工作原理
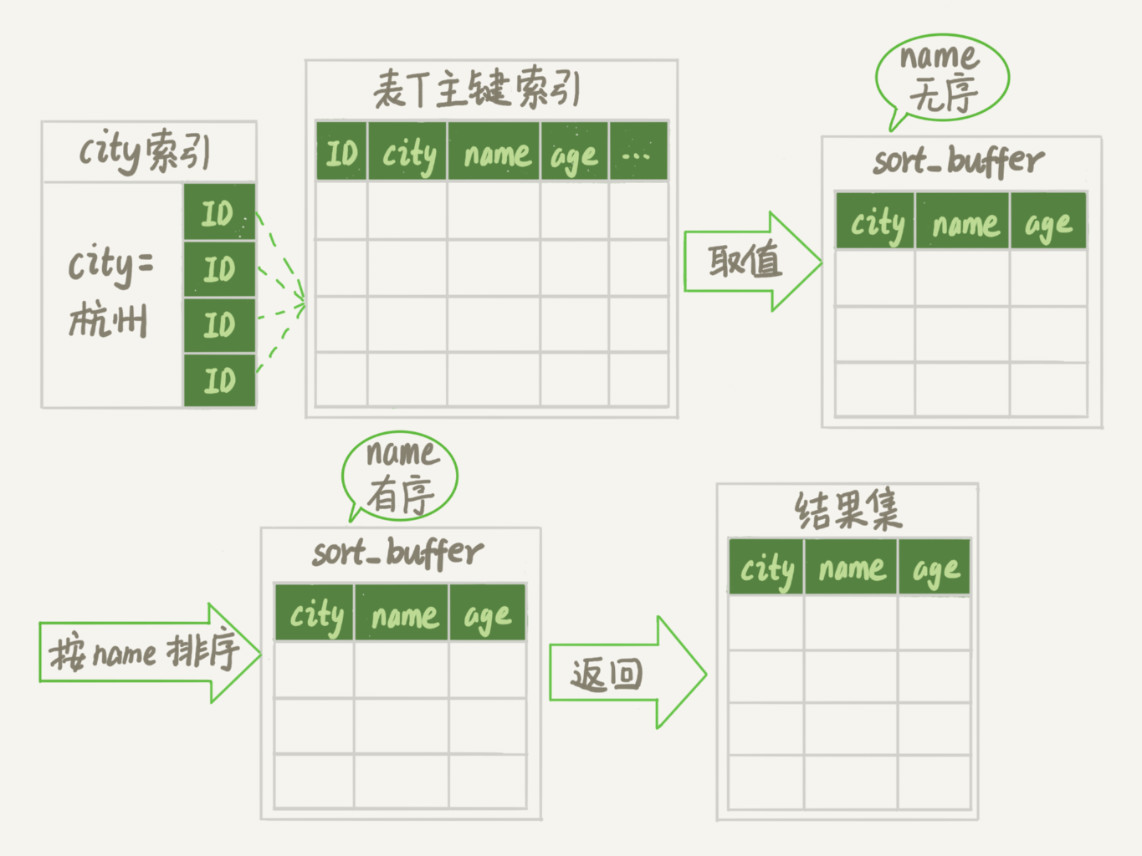
1、全字段排序
1)using fileSort 表明是排序;
2)mysql 为每个线程分配一块内存用来排序: sort_buffer(sort_buffer_size 设置大小);
3) 排序的流程
① 初始化 sort_buffer ,放入 要查询的字段
② 找到符合要求的记录的主键id;
③ 按主键id取出整行,放入到 sort_buffer
④ 重复 ②、③ 步骤;
⑤ 根据指定字段排序;
⑥ 返回结果;
4、sort_buffer_size (临时文件的数量)决定是内存排序还是外部排序
/* 打开 optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* @a 保存 Innodb_rows_read 的初始值 */
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 执行语句 */
select city, name,age from t where city='杭州' order by name limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
/* @b 保存 Innodb_rows_read 的当前值 */
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 计算 Innodb_rows_read 差值 */
select @b-@a;
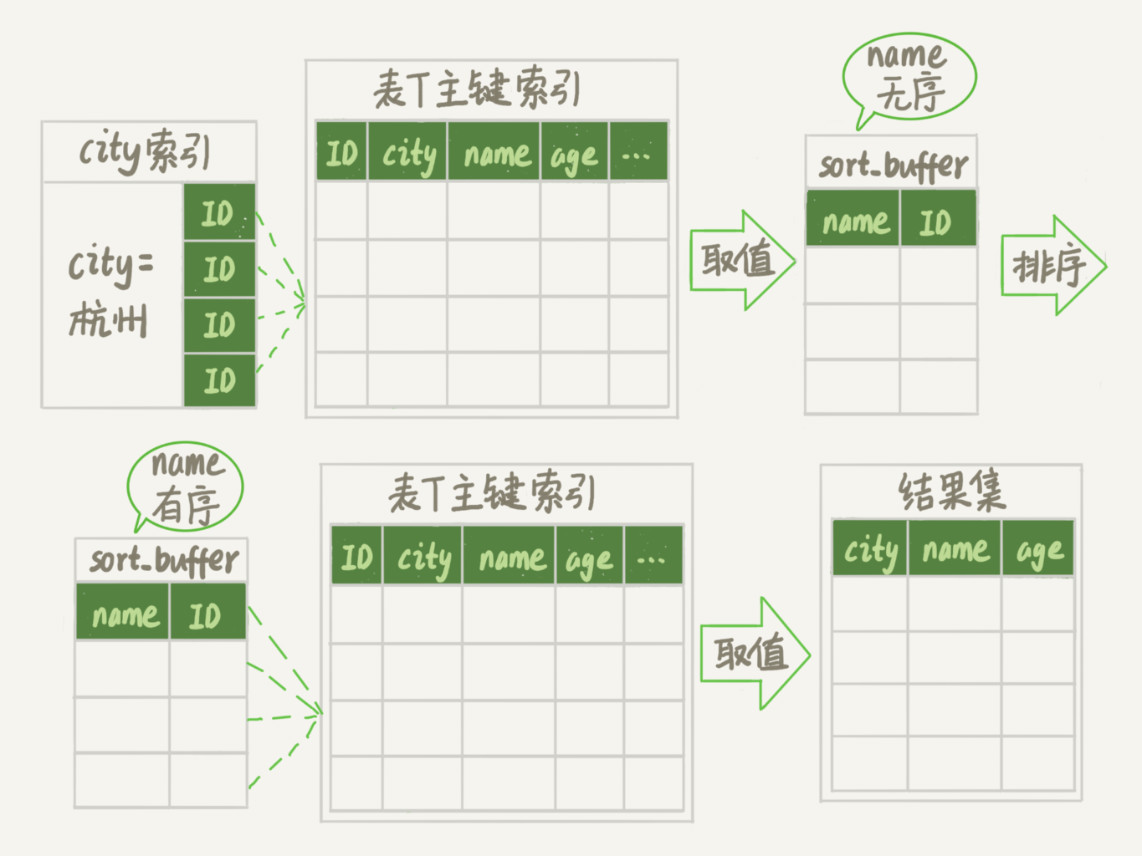
2、rowId 排序
1)设置每行数据阈值(max_length_for_sort_data);
2)流程图
3)执行数量
3、全字段排序 VS rowid 排序
1、默认如果内存够用,优先使用内存;
2、数据有序
(1) (主键id、排序字段) 回表;
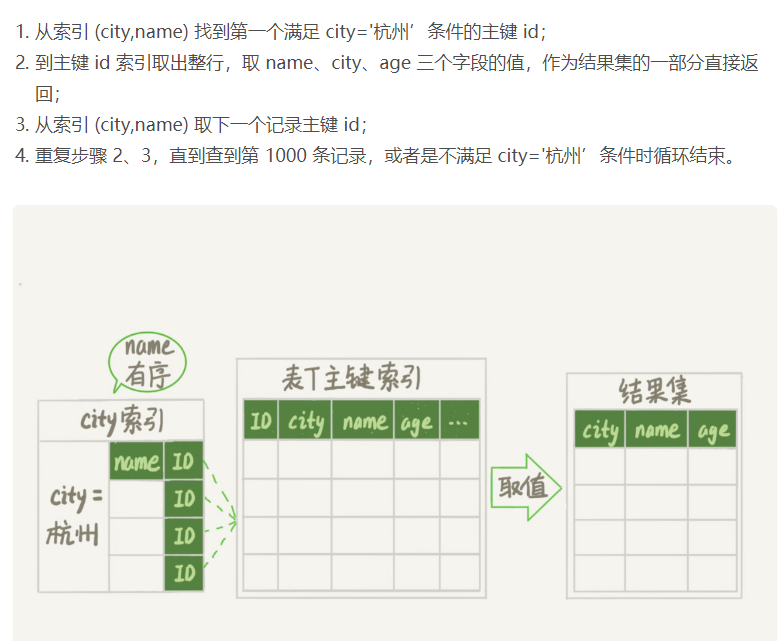
(2)覆盖索引 不用回表
















 42万+
42万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









