







集成算法(Emseble Learning)是构建多个学习器,然后通过一定策略结合把它们来完成学习任务的,常常可以获得比单一学习显著优越的学习器。周志华的书上说,“个体学习器的"准确性"和"多样性"本身就存在冲突,一般准确性很高之后,要增加多样性就需牺牲准确性。事实上,如何产生并结合‘好而不同’的个体学习器,恰是集成学习研究的核心”(对准确性和多样性的论述还不是很理解)。
按照个体学习器之间的关系,分为Bagging、Boosting、Stacking三大类。
Bagging的原理首先是基于自助采样法(bootstrap sampling)随机得到一些样本集训练,用来分别训练不同的基学习器,然后对不同的基学习器得到的结果投票得出最终的分类结果。自助采样法得到的样本大概会有63%的数据样本被使用,剩下的可以用来做验证集。
随机森林(Random Forest)其实也算Bagging的一种,但是有一点区别是随机森林在构建决策树的时候,会随机选择样本特征中的一部分来进行划分。由于随机森林的二重随机性,它具有良好的学习性能。
Boosting,提升算法,它通过反复学习得到一系列弱分类器,然后组合这些弱分类器得到一个强分类器,把弱学习器提升为强学习器的过程。主要分为两个部分,加法模型和向前分步。加法模型就是把一系列的弱学习器相加串联为强学习器,表示如下:
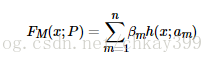
其中h(x; am)是一系列的弱学习器,am是该学习器训练得到的最优参数,βm是对应的弱学习器在强学习器中所占比例的系数。向前分步是指本轮得到的学习器是在上一轮学习器的基础上迭代训练得到的,可以表示为:
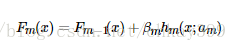
Boosting的算法族中有很多有名的算法,包括Adaboost、Xgboost、GBDT等。
Adaboost,基于对Boosting的理解,对Aboost需要弄清楚:①h(x; am)每次迭代都会根据上一轮来计算每个样本的权重,上一轮被分类错误的被赋予更大的权重,分类正确的权值变小,这理解为在决策面附近的点被分错的可能性很大所以需要加大权重,在计算时被更加重视,或者上轮计算结果与正确结果的残差被拿来重点分析;②βm的计算与学习器的误差率有关,误差率越低则该学习器所占比例的系数越高。其说法流程总结如下:
总结一下,得到AdaBoost的算法流程:
输入为训练数据集T={(x1,y1),(x2,y2),...,(xN,yN)},其中,xi∈X⊆Rn,yi∈Y={−1,1},迭代次数M;
1)初始化训练样本的权值分布为D1=(w1,1,w1,2,…,w1,i),w1,i=1/N,i=1,2,…,N;
2)对于m=1,2,…,M
—》使用具有权值分布Dm的训练数据集进行学习,得到弱分类器Gm(x);
—》计算Gm(x)在训练数据集上的分类误差率:
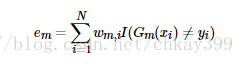
—》计算Gm(x)在强分类器中所占的权重(弱分类器在最总分类器中所占比例由损失函数推导出来,暂时不推):
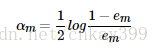
—》更新训练数据集的权值分布(这里,zm是归一化因子,使样本的概率分布和为1):
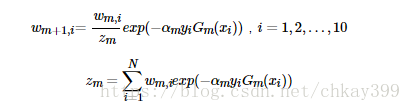
3)得到最终分类器:
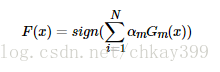














 930
930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









