










前言
MapReduce的源码分析是基于Hadoop1.2.1基础上进行的代码分析。
该章节会分析在MapTask端的详细处理流程以及MapOutputCollector是如何处理map之后的collect输出的数据。
map端的主要处理流程
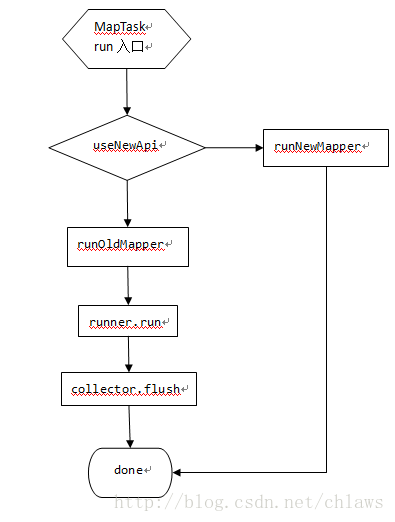
图1 MapTask处理流程
图1所示为MapTask的主要代码执行流程,在MapTask启动后会进入入口run函数,根据是否使用新的api来决定选择运行新的mapper还是旧的mapper,最后完成执行向外汇报。
在这,我们选择分析旧的api,也就是runOldMapper。在runOldMapper内部主要分为MapperRunner.run执行用户端编写的map函数,在所有都执行完毕后,会调用MapOutputCollector的flush,讲最后一部分内存中的数据刷入到磁盘中。
根据上述的流程我们对代码依次进行分析,先看入口代码:
public void run(finalJobConf job, finalTaskUmbilicalProtocol umbilical) throwsIOException, ClassNotFoundException, InterruptedException { this.umbilical = umbilical; // start thread that will handlecommunication with parent TaskReporter reporter = new TaskReporter(getProgress(), umbilical, jvmContext); reporter.startCommunicationThread(); booleanuseNewApi = job.getUseNewMapper(); initialize(job, getJobID(), reporter, useNewApi); .... if(useNewApi) { runNewMapper(job, splitMetaInfo, umbilical, reporter); } else{ runOldMapper(job, splitMetaInfo, umbilical, reporter); //运行旧的mapper } done(umbilical, reporter); }入口代码很简单,我们只需要关心是否使用新旧api来判断选择运行哪种mapper,在这里,分析runOldMapper,runOldMapper是封装了一个mapper是如何被执行,代码如下:
其中流程3,所说到的用户的job有reduce处理,那么就会调用MapOutputBuffer。这大多数场景下,都会有指定,因此需要详细看看在MapTask端数据输出是如何处理的。private<INKEY,INVALUE,OUTKEY,OUTVALUE> void runOldMapper(finalJobConf job, final TaskSplitIndex splitIndex, final TaskUmbilicalProtocol umbilical, TaskReporter reporter ) throws IOException,InterruptedException, ClassNotFoundException { InputSplit inputSplit = getSplitDetails(new Path(splitIndex.getSplitLocation()), splitIndex.getStartOffset()); //流程1 updateJobWithSplit(job, inputSplit); reporter.setInputSplit(inputSplit); RecordReader<INKEY,INVALUE> in = isSkipping() ? new SkippingRecordReader<INKEY,INVALUE>(inputSplit,umbilical, reporter) : newTrackedRecordReader<INKEY,INVALUE>(inputSplit, job, reporter); job.setBoolean("mapred.skip.on", isSkipping()); //流程2 intnumReduceTasks = conf.getNumReduceTasks(); LOG.info("numReduceTasks: "+ numReduceTasks); MapOutputCollector collector = null; if(numReduceTasks > 0) { //流程3 collector = new MapOutputBuffer(umbilical, job, reporter); } else{ collector = new DirectMapOutputCollector(umbilical, job, reporter); } MapRunnable<INKEY,INVALUE,OUTKEY,OUTVALUE> runner = ReflectionUtils.newInstance(job.getMapRunnerClass(), job); try{ runner.run(in, new OldOutputCollector(collector, conf), reporter); //流程4 collector.flush(); //流程5 in.close(); in = null; collector.close(); collector = null; } finally{ ... } }
MapOutputBuffer
什么是MapOutputBuffer
我们都知道在map处理方法中,对输入的kv键值对K1,V1进行处理转换后,会使用collector.collect(K2,V2)输出处理后的kv键值对。 很多人不知道collect之后具体做了什么,如何做的,带着这个问题,分析下代码。map方法内调用collector.collect,首先调用的是OutputCollector.collect,OldOutputCollector实现了OutputCollector接口,因此就是调用了OldOutputCollector.collect,代码如下:方法内对key计算得分区号后,调用了collector.collect,这个collector就是前面所说的MapOutputBuffer,MapOutputBuffer实现了MapOutputCollector接口。public void collect(K key, V value) throws IOException { try { collector.collect(key, value, partitioner.getPartition(key, value, numPartitions)); } catch (InterruptedException ie) { Thread.currentThread().interrupt(); throw new IOException("interrupt exception", ie); } }MapOutputBuffer是一个用来暂时存储map输出的缓冲区,它的缓冲区大小是有限的,当写入的数据超过缓冲区的设定的阀值时,需要将缓冲区的数据溢出写入到磁盘,这个过程称之为spill,spill的动作会通过Condition通知给SpillThread,由SpillThread完成具体的处理过程。如果缓冲区使用过的是简单的单向缓冲区,在一次写满后,flush到磁盘,那么在flush的过程中,将会严重影响到map向缓冲区写入的性能,因为在flush的时候,缓冲区是需要被锁定的。因此,MR采用了循环缓冲区,做到数据在spill的同时,仍然可以向剩余空间继续写入数据。缓冲区分析
MapOutputBuffer定义了三个缓冲区,分别是:
int [] kvoffsets, int[] kvindices, byte[] kvbuffer
kvoffsets是索引缓冲区,它的作用是用来记录kv键值对在kvindices中的偏移位置信息。
kvindices也是一个索引缓冲区,索引区的每个单元包含了分区号,k,v在kvbuffer中的偏移位置信息。
kvbuffer是数据缓冲区,保存了实际的k,v。
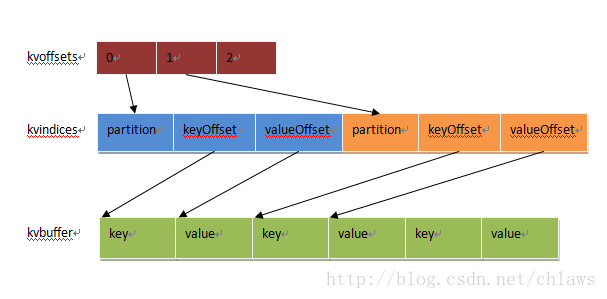
图1索引区关系
缓冲区之间的关系,从图1即可一目了然, kvoffsets作为一级索引,一个用途是用来表示每个k,v在kvindices中的位置,另一个是用来统计当前索引的缓存的占用比,当超过设定的阀值,就会触发spill动作,将已写入的数据区间spill出去,新写入的时候持续向后写入,当写到尾部后,回过头继续写入。
kvindices为什么要如此用这样结构表示是为了在指定了多个reducetask的时候,maptask的输出需要进行分区,比如有2个reducetask,那么需要将maptask的输出数据均衡的分布到2个reducetask上,因此在索引里引入了分区信息,另外一个是为了每个分区的key有序,避免直接在比较后直接拷贝key,而只要相互交换一下整形变量即可。
kvbuffer存储了实际的k,v,为了保证k,v的键值成对的出现,引入了mark标记上一个完成的k,v的位置。同时类似kvoffset一样也加入了表示缓冲区是否满足溢出的一些标志。还有一点就是,k,v的大小不向索引区一样明确的是一对占一个int,可能会出现尾部的一个key被拆分两部分,一步存在尾部,一部分存在头部,但是key为保证有序会交给RawComparator进行比较,而comparator对传入的key是需要有连续的,那么由此可以引出key在尾部剩余空间存不下时,如何处理。处理方法是,当尾部存不下,先存尾部,剩余的存头部,同时在copy key存到接下来的位置,但是当头部开始,存不下一个完整的key,会付出溢出flush到磁盘。当碰到整个buffer都存储不下key,那么会抛出异常MapBufferTooSmallException表示buffer太小容纳不小.
核心成员变量
先看看MapOutputBuffer的主要的一些成员变量
kvoffset相关的成员变量如下: private volatile int kvstart = 0; // marks beginning of spill private volatile int kvend = 0; // marks beginning of collectable private int kvindex = 0; // marks end of collected private final int[] kvoffsets; // indices into kvindices 在默认情况下kvstart,kvend是相等等,kvindex是表示在kvoffsets中下一个可以写入的位置,当缓冲区达到阀值的时候,kvend=kvindex。在完成溢出写入过程之后,kvend=kvstart。 注意,这里所的阀值是索引区满足一定使用量,在采用默认配置的时候是达到缓冲区的80%, 也就是kvoffsets.length * 0.8 kvindices相关的成员变量如下: private final int[] kvindices; // partition, k/v offsets into kvbuffer private static final int PARTITION = 0; // partition offset in acct private static final int KEYSTART = 1; // key offset in acct private static final int VALSTART = 2; // val offset in acct //RECSIZE表示一条索引记录占用16字节,即keoffsets中占用1个int,kvindices中占用3个int private static final int ACCTSIZE = 3; // total #fields in acct private static final int RECSIZE = (ACCTSIZE + 1) * 4; // acct bytes per record 在前面我们说过kvindices中的是按三个int作为一个单元(partition,keyoffset,valoffset)来表示k,v在keybuffer中的位置信息以及属于哪个分区。因此每次操作的时候都是 //ind是kvoffsets中存储的值 kvindices[ind + PARTITION] = partition; kvindices[ind + KEYSTART] = keystart; kvindices[ind + VALSTART] = valstart;kvbuffer相关的成员变量如下:
private volatile int bufstart = 0; // marks beginning of spill private volatile int bufend = 0; // marks beginning of collectable private volatile int bufvoid = 0; // marks the point where we should stop // reading at the end of the buffer private int bufindex = 0; // marks end of collected private int bufmark = 0; // marks end of record private byte[] kvbuffer; // main output bufferbufstart,bufend,bufindex的作用和kvoffsets中的kvstart,kvend,kvindex一样。
bufmark用来记录一个完整的k,v记录结束的位置,bufvoid用来表示kvbuffer中有效内存结束位置。kvbuffer也有一个阀值,在采用默认配置的时候是达到缓冲区的80%,是kvbuffer.length * 0.8。
还有一部分是和处理spill相关的成员变量
// spill accounting privatevolatileintnumSpills= 0;//记录当前spill的次数,还会用于组成spill输出的临时文件名 //key,value的序列化类 privatefinalSerializer<K> keySerializer; privatefinalSerializer<V> valSerializer; //BlockingBuffer是DataOutputStream类型,k,v的写入会通过流的形式写入到bb中,最后满足溢出条件才从kvbuffer写入到磁盘 privatefinalBlockingBuffer bb= newBlockingBuffer(); //满足溢出条件,干脏活累活的线程 privatefinalSpillThread spillThread= newSpillThread();初始化分析
final float spillper = job.getFloat("io.sort.spill.percent",(float)0.8); final float recper = job.getFloat("io.sort.record.percent",(float)0.05); final int sortmb = job.getInt("io.sort.mb", 100); intmaxMemUsage = sortmb << 20; intrecordCapacity = (int)(maxMemUsage * recper); recordCapacity -= recordCapacity % RECSIZE; kvbuffer= newbyte[maxMemUsage- recordCapacity]; bufvoid= kvbuffer.length; recordCapacity /= RECSIZE; kvoffsets= newint[recordCapacity]; kvindices= newint[recordCapacity* ACCTSIZE]; softBufferLimit = (int)(kvbuffer.length* spillper); softRecordLimit= (int)(kvoffsets.length * spillper);在MR的配置选项里有两个参数比较常见到的,一个是io.sort.spill.percent,另一个是io.sort.mb。前者表示在缓冲区使用到多少的时候开始触发spill,后者表示一个MapTask能使用多少的内存大小,将其用作输出的缓存。
从上面我们能够看到kvbuffer,kvoffsets,kvindices的在整个sortmb大小的内存中占用的比例,按默认值算分别是kvbuffer占95M,kvoffsets占1.25M,kvindices占3.75M。
另外,还有kvbuffer,kvoffsets使用到多少会触发spill的一个上限值,这里默认是其长度的80%。
// k/v serialization comparator= job.getOutputKeyComparator(); keyClass= (Class<K>)job.getMapOutputKeyClass(); valClass= (Class<V>)job.getMapOutputValueClass(); serializationFactory = newSerializationFactory(job); keySerializer= serializationFactory.getSerializer(keyClass); keySerializer.open(bb); valSerializer= serializationFactory.getSerializer(valClass); valSerializer.open(bb);comparator是key之间用于比较的类,在没有设置的情况下,默认是key所属类里面的一个子类,这个子类继承自WritableComparator。以Text作为key为例,就是class Comparator extends WritableComparator。
keyClass和valClass一般情况下用户都没有去设置的,也可以不用去设置,这种情况是指map的key,value的输出和reduce的key,value输出是一样的类型。因为在没有设置map阶段的key,value的输出类型的时候,会调用getOutputKeyClass/getOutputValueClass进行获取。
keySerializer和valSerializer这两个序列化对象,通过序列化工厂类中获取到的,实际上就是WritableSerialization类内的静态类:static class WritableSerializer implements Serializer<Writable>的一个实例。
关于WritableSerialization需要简单的说明下,这个类有包含了两个静态类,分别是WritableDeserializer和WritableSerializer,序列化和反序列化的操作基本类似,都是打开一个流,将输出写入流中或者从流中读取数据。对于序列化是对输入类型调用write接口得到序列化后的内容输出到流中:
public void serialize(Writable w) throws IOException { w.write(dataOut); }对于反序列化从流中读取输出,这个要读取解析的对象可以是构造时传入的,也可以是调用deserialize接口传入的类型。
public Writable deserialize(Writable w) throws IOException { Writable writable; if(w == null){ writable = (Writable) ReflectionUtils.newInstance(writableClass, getConf()); } else{ writable = w; } writable.readFields(dataIn); returnwritable; }最终调用的都是大家熟悉的hadoop在common包中org.apache.hadoop.io这个包内的各种writable类型的write/readFields接口。
keySerializer.open(bb)和valSerializer.open(bb)打开的是流,但不是文件流,而是BlockingBuffer,也就是说后续调用serialize输出key/value的时候,都是先写入到Buffer中,这个后续还会在提到。
collect分析
这里分析的collect是MapOutputBuffer中的collect方法,在用户层的map方法内调用collector.collect最终会一层层调用到MapOutputBuffer.collect,这个在前面的"什么是MapOutputBuffer"这一小节中有提到。
collect的代码我们分为两部分来看,一部分是根据索引区来检查是否需要触发spill,
另外一部分是操作buffer并更新索引区的记录。
第一部分代码如下:
public synchronized void collect(K key,V value, int partition ) throws IOException { ... //无关紧要的代码 finalintkvnext = (kvindex+ 1) % kvoffsets.length; //获取下一个的索引位置 spillLock.lock(); try{ boolean kvfull; do { if (sortSpillException != null){ throw (IOException)new IOException("Spill failed" ).initCause(sortSpillException); } //步骤1,判断是否需要触发 // sufficient acct space kvfull = kvnext == kvstart; //判断是否索引区满了 final boolean kvsoftlimit = ((kvnext > kvend) //判断索引区使用达到上限 ? kvnext - kvend > softRecordLimit : kvend - kvnext <= kvoffsets.length - softRecordLimit); if (kvstart == kvend&& kvsoftlimit) { //判断是否触发spill LOG.info("Spilling map output: record full = "+ kvsoftlimit); startSpill(); //发起通知,通知SpillThread开始做溢出动作 } //步骤2,缓冲区满的时候,是否需要等待 if (kvfull) { try { //spill动作还未完成,持续等待 while (kvstart != kvend){ reporter.progress(); spillDone.await(); } } catch (InterruptedException e) { throw (IOException)new IOException( "Collector interrupted while waiting for the writer" ).initCause(e); } } } while (kvfull); } finally{ spillLock.unlock(); }步骤1解析:
1.判断缓冲区是否满了(指kvoffsets),缓冲区满的判断标准是kvnext==kvstart,因为是循环缓存区,因此kvnext追上了kvstart所指示的起始位置,就是缓冲区满了
2. 在kvstart==kvend,并且kvoffsets的使用是否达到了上限,触发激活SpillThread开始执行spill动作。为什么会有kvstart==kvend这个判断呢,这是因为在缓冲区没有满足spill时,kvend都是指向kvstart,当触发spill时,kvend会指向kvindex位置,也就是说kvstart到kvindex这段区间会被标识出来,是需要spill这段区间,在spill动作完成之后,会将kvstart指向kvend。因此为了避免已经触发过的了动作再次触发,需要加入kvstart==kvend这个条件。
3.startSpill的动作,会执行这3条语句:
kvend= kvindex;//将kvend指向kvindex,表示spill的区域 bufend= bufmark;//将bufend指向bufmark,bufmark表示最后一个完整的kv记录结束的位置 spillReady.signal();//发起信号,唤醒SpillThread步骤2解析:
1.如果缓冲区已经满了,说明SpillThread还在执行spill动作的过程中,那么需要等待到spill动作的完成,在完成之后,SpillThread会将kvstart指向kvend,并且发送spillDone信号。
第二部分代码如下:
try { //步骤1:序列化key,判断是否需要对buffer进行调整 // serialize key bytes into buffer int keystart = bufindex; keySerializer.serialize(key); if (bufindex < keystart) { // wrapped the key; reset required bb.reset(); keystart = 0; } //步骤2:序列化value,并标记一个完整k,v的结束的位置 // serialize value bytes into buffer final int valstart = bufindex; valSerializer.serialize(value); int valend = bb.markRecord(); if (partition < 0 || partition >= partitions) { throw new IOException("Illegal partition for " + key + " (" + partition + ")"); } mapOutputRecordCounter.increment(1); mapOutputByteCounter.increment(valend >= keystart ? valend - keystart : (bufvoid - keystart) + valend); //步骤3:更新一级索引,二级索引。 // update accounting info int ind = kvindex * ACCTSIZE; kvoffsets[kvindex] = ind; kvindices[ind + PARTITION] = partition; kvindices[ind + KEYSTART] = keystart; kvindices[ind + VALSTART] = valstart; kvindex = kvnext; } catch (MapBufferTooSmallException e) { LOG.info("Record too large for in-memory buffer: " + e.getMessage()); spillSingleRecord(key, value, partition); mapOutputRecordCounter.increment(1); return; } }步骤1解析:
1.根据key的序列化类,序列化输出key到kvbuffer。
1)key是如何输出到kvbuffer的呢,带着这个问题,我们一步步分析。根据前面说过,keySerializer.serialize(key);将会调用的是WritableSerialization.WritableSerializer.serialize(Writable w)方法,为便于分析,现假设key为Text类型。那么serialize方法内执行的将会是Text中的write方法,也就是如下所示:
publicvoid write(DataOutput out) throws IOException { WritableUtils.writeVInt(out, length); out.write(bytes,0, length); }这里会写入Text的长度和数据内容。
这里的这个out又是什么呢,keySerializer在构造完成的时候,调用过一个open函数,传入了一个BlockBuffer的对象,BlockBuffer对象就是这里的out。
再来看看BlockingBuffer的构造:
public BlockingBuffer() { this(new Buffer()); } privateBlockingBuffer(OutputStream out) { super(out); }它new了一个Buffer传递给DataOutputStream,Buffer是BlockBuffer内部实现的一个继承自OutputStream的类,它实现了write接口。因此在调用out.write的时候,最终调用的是Buffer.write。
2)Buffer.write,对于输入的数据,会判断当前kvbuffer缓冲区是否满,如果满了或者是使用达到上限了,但是kvoffsets索引缓冲区还没有达到使用上限(也就是没有kvoffsets的使用没有触发spill),那么会调用startSpill去激活SpillThread执行spill。
2.当bufindex出现从kvbuffer尾部的位置重新循环到头部是,说明有key存在尾部存了一部分,头部存了一部分。由于key的比较函数需要的是一个连续的key,因此需要对key进行特殊处理。
重新写入一个完整的key。看具体处理代码:
protected synchronized void reset() throwsIOException { // key被拆分为两部分,第一部分是在尾部 int headbytelen = bufvoid - bufmark; //缩短bufvoid为最后一个kv记录结束的位置,也就是第一部分的key在后续不处理 bufvoid = bufmark; //因为bufindex已经循环了,索引bufindex肯定是在bufstart前面 //这里需要判断bufindex开始到bufstart这一段区间是否能容纳的下第一部分的key if (bufindex + headbytelen < bufstart) { //容纳的下,触发两次copy,先将第二部分key往后copy //再将第一部分的key copy到kvbuffer起始位置 System.arraycopy(kvbuffer, 0, kvbuffer, headbytelen, bufindex); System.arraycopy(kvbuffer, bufvoid, kvbuffer, 0, headbytelen); bufindex += headbytelen; } else { /* 当容纳不下的时候,先copy第二部分的key 然后将bufindex重置,重新写入第一部分的key,当缓存不足够写入第一部分的key 会触发spill;当可以写入则写入第一部分的key,在写入keytmp所存放的第二部分的key的时候,会触发spill,当spill完成之后该第二部分key仍不能完整的写入,则会throw一个异常,指出key太大。 // byte[] keytmp = new byte[bufindex]; System.arraycopy(kvbuffer, 0, keytmp, 0, bufindex); bufindex = 0; out.write(kvbuffer, bufmark, headbytelen); out.write(keytmp); } } }2.当kvindex从kvbuffer尾部重新循环到头部的时候,需要对不连续的的key进行特殊处理。
步骤2解析:
1.根据value的序列化类,序列化输出value到kvbuffer中,并在结束时,将bufmark置为value的结束位置。
步骤3解析:
1.更新kvoffsets的索引,在kvindex这个节点,记录下在kvindices的哪个节点记录了当前这个k,v键值对信息。并将kvindex指向下一个可用的位置。
总的来说,collect的流程就是如上所说的这些,至于涉及到的SpillThread的处理,在后续会单独解析。
flush分析
用户在结束map处理后,已经没有数据再输出到缓冲区,但缓存中还有数据没有刷到磁盘上,需要将缓存中的数据flush到磁盘上,这个动作就是由MapOutbutBuffer的flush来完成。
我们看看flush是在哪个时间段调用的,在文章开始处说到runOldMapper处理的时候,有提到,代码如下:
runner.run(in,newOldOutputCollector(collector,conf), reporter);
collector.flush();
是在MapRunner执行一个Mapper后,会调用collector将残留的数据flush出去,就是在这里被调用到的。
我们再看看flush函数的处理流程,逻辑还是比较简单的。
flush的处理分为上述4个步骤,分别在代码中注释了,其中步骤4的过程涉及到了对输出的文件进行排序,合并的过程,后面会单独再对此进行分析。public synchronized void flush() throws IOException,ClassNotFoundException, InterruptedException { LOG.info("Starting flush of map output"); spillLock.lock(); try{ //步骤1:如果已经在spill等待完成 while (kvstart != kvend){ reporter.progress(); spillDone.await(); } if (sortSpillException != null){ throw (IOException)new IOException("Spill failed" ).initCause(sortSpillException); } //步骤2:缓冲区还有数据没有刷出去,则触发spill if (kvend != kvindex){ kvend = kvindex; bufend = bufmark; sortAndSpill(); } } catch(InterruptedException e) { throw (IOException)new IOException( "Buffer interrupted while waiting for the writer" ).initCause(e); } finally{ spillLock.unlock(); } assert!spillLock.isHeldByCurrentThread(); // 步骤3:停止spill线程 try{ spillThread.interrupt(); spillThread.join(); } catch(InterruptedException e) { throw (IOException)new IOException("Spill failed" ).initCause(e); } kvbuffer= null; //步骤4:合并之前陆续输出的spill.1.out...spill.n.out为file.out mergeParts(); Path outputPath = mapOutputFile.getOutputFile(); fileOutputByteCounter.increment(rfs.getFileStatus(outputPath).getLen()); }














03-31
 303
303
303
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









