






【前言】别人都在你看不到的地方暗自努力,在你看得到的地方,他们也和你一样显得游手好闲,和你一样会抱怨,而只有你自己相信这些都是真的,最后,也只有你一个人继续不思进取 ……
【下载】个人结合诸多资料,总结的一些JavaEE常见面试题,主要针对初/中级程序员。想要word完整版下载的,评论里留言留下你的邮箱!
51.事务的特性?
答:①原子性(Atomicity)
指事务是一个不可分割的工作单位,事务中的操作要么全都发生,要么全不发生;
②一致性(Consistency)
事务前后数据的完成性必须保持一致;(例:转账前后的,两个人的金额总数是不变的)
③隔离性(Isolation)
指多个用户并发访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发事务之间要项目隔离;
④持久性(Durability)
指一个事务一旦被提交,它对数据库中数据的改变是永久性的,接下来即使数据库发生故障,也不应该对其有任何影响;
52.事务并发访问的问题?
答:①脏读:一个事务读到了另一个事务未提交的数据;
②不可重复读:在同一个事务中,多次查询的结果不一致(由update引起的)
③虚读/幻读:在同一个事务中,多次查询的结果不一致(由insert引起的)
53.隔离的级别?
答:①读未提交
read uncommitted;一个事务读到另一个事务没有提交的数据;
(未解决,3问题都存在)
②读已提交 —— oracle默认
read committed;一个事务读到另一个事务已提交的数据;
(解决脏读)
③可重复读 --- mysql默认
repeatable read;在一个事务中读到的数据始终保持一致,无论另一个事务是否提交
(解决脏读和不可重复读)
④串行化
serializable 串行化,同时只能执行一个事务,相当于单线程事务;
(都解决)
54.tuncate和delete区别?
答:① truncate数据ddl delete属于dml
② truncate是先删除drop该表,再create该表。而且无法回滚!!!
55.在Hibernate中实现数据检索的5种方式?
答:① 对象导航(关联级别的数据检索)
② HQL语句
③ SQL语句
④ QBC语句
⑤ 通过OID加载(get( ) / load( ))
56.Cascade与Inverse区别?
答:①Cascade主要用于级联操作(如:级联添加,删除等);
②Inverse主要用于控制权是否要反转,一般将控制权放在多方,可以提高效率;
如:当删除部门时,级联删除部门下的所有用户。
若inverse = “false” 默认值,可以不配
控制台输出3条语句:
Update user set deptId = null where deptId = 1;//解决父子关系
Delete from user where deptId is null; //先干掉子类
Delete from user where id=1; //再自杀
若inverse = “true” 代表控制权要反转,交给多方维护,相率会提高;
控制台输出2条语句:
Delete from user where deptId=1; //自杀
Delete from user where id=1;//自杀
57.PO类的定义规范?
答:①是一个共有类;
②提供无参共有构造方法;
③属性是私有的;
④为私有属性提供共有的getter/setter;
⑤不能使用final修饰;
⑥可以实现java.io.Serializbale接口;
⑦如果是基本类型,需要使用它的包装类;
58.请分别写出一对一,一对多,多对一,多对多的PO类映射文件?
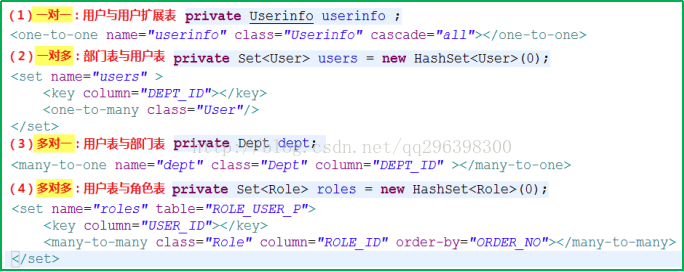
59.抽取BaseAction的理由?
答:①通过实现RequestAware、SessionAware、ApplicationAware接口,自定义protected Map<String,Object> request/session/application,并提供getter方法,继承setter方法,此时再编写Action类时,依赖的是自己的API,将来框架升级改造时,只要修改BaseAction就可以了,可以更好的实现与Struts2的解耦合;
②可以在BaseAction中抽取一些公共的操作方法;
60.XML文档定义有几种形式?它们之间有何本质区别?解析XML文档有哪几种方式?
答:(1)XML文档有两种约束方式:DTD约束和Schema约束;
(2)区别:
①DTD不符合XML的语法结构,schema符合XML的语法结构;
②DTD的约束扩展性比较差,XML文档只能引入一个DTD的文件。schema可以引入多个文件;
③DTD不支持名称空间(理解包结构),schema支持名称空间;
④DTD支持数据比较少,schema支持更多的数据类型;
(3)解析方式主要有三种:
①DOM解析:
(a)加载整个xml的文档到内存中,形成树状结构,生成对象;
(b)容易产生内存溢出;
(c)可以做增删改;
②SAX解析
(a)边读边解析;
(b)不可以做增删改;
③ DOM4J解析(hibernate底层采用)
(a)可让SAX解析也产生树状结构。
(b)主要api开发步骤:
1)SAXReader.read(xxx.xml)代表解析xml的文档,返回对象是Document;
2)Document.getRootElement(),返回的是文档的根节点,是Element对象;
3)Element:
.element(...) -- 获得指定名称第一个子元素。可以不指定名称;
.elements(...) -- 获得指定名称的所有子元素。可以不指定名称;
.getText() -- 获得当前元素的文本内容;
.elementText(...) -- 获得指定名称子元素的文本值
.addElement() -- 添加子节点
.setText() -- 设置子标签内容
4)XMLWriter.write("..") --写出
5)XMLWriter.close() --关闭输出流
61.你们项目为什么选用maven进行构建?
答:①首先,maven是一个优秀的项目构建工具。使用maven,可以很方便的对项目进行分模块构建,这样在开发和测试打包部署时,效率会提高很多。
②其次,maven可以进行依赖的管理。使用maven,可以将不同系统的依赖进行统一管理,并且可以进行依赖之间的传递和继承。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









