






mysql数据库
官方网站:https://dev.mysql.com;
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
什么是事务
事务:数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作; 事务是一组不可再分割的操作集合(工作逻辑单元);
典型事务场景(转账):
update user_account set balance = balance - 1000 where userID = 3;
update user_account set balance = balance +1000 where userID = 1;
mysql中如何开启事务:
begin / start transaction -- 手工
commit / rollback -- 事务提交或回滚
set session autocommit = on/off; -- 设定事务是否自动开启
JDBC 编程事务开启: connection.setAutoCommit(boolean);
特性:
原子性(Atomicity) 最小的工作单元,整个工作单元要么一起提交成功,要么全部失败回滚;
一致性(Consistency) 事务中操作的数据及状态改变是一致的,即写入资料的结果必须完全符合预设的规则,不会因为出现系统意外等原因导致状态的不一致;
隔离性(Isolation) 一个事务所操作的数据在提交之前,对其他事务的可见性设定(一般设定为不可见);
持久性(Durability) 事务所做的修改就会永久保存,不会因为系统意外导致数据的丢失;
四种隔离级别:
Read Uncommitted(未提交读):--未解决并发问题 事务未提交对其他事务也是可见的,脏读(dirty read);
Read Committed(提交读):--解决脏读问题 一个事务开始之后,只能看到自己提交的事务所做的修改,不可重复读(nonrepeatable read);
Repeatable Read (可重复读) :--解决不可重复读问题 在同一个事务中多次读取同样的数据结果是一样的,这种隔离级别未定义解决幻读的问题;
Serializable(串行化):--解决所有问题 最高的隔离级别,通过强制事务的串行执行;
inodb引擎对隔离级别的支持程度: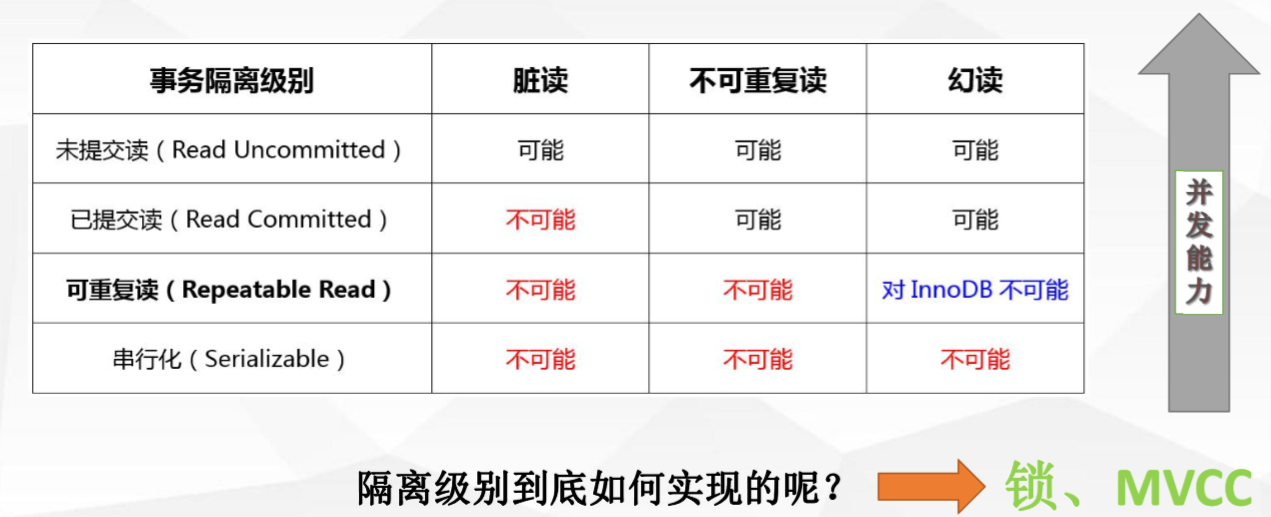
mysql中的锁
InnoDB中的锁
InnoDB的行锁是通过给索引上的索引项加锁来实现的。
只有通过索引条件进行数据检索,InnoDB才使用行级锁,否则,InnoDB 将使用表锁(锁住索引的所有记录)
表锁:lock tables xx read/write;
InnoDB和Myisam的区别:
索引:InnoDB用的是聚集索引(数据文件和索引在同一个文件中);而Myisam用的是非聚集索引(数据文件和索引在同一个文件中);
锁:InnoDB有行级锁,Myisam没有行级锁,只有表锁;
事务:InnoDB支持事务,Myisam不支持事务;
外键:InnoDB支持外键,MyISAM不支持;
count(*):InnoDB中不保存表的行数,如select count(*) from table时,InnoDB需要扫描一遍整个表来计算有多少行,MyISAM只要简单的读出保存好的行数即可。注意的是,当count(*)语句包含where条件时MyISAM也需要扫描整个表;
删除:清空整个表时,InnoDB是一行一行的删除,效率非常慢。MyISAM则会重建表;
共享锁(行锁)shared locks
又称为读锁,简称S锁,顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁, 都能访问到数据,但是只能读不能修改;
加锁释锁方式: select * from users WHERE id=1 LOCK IN SHARE MODE; commit/rollback
排它锁(行锁)exclusive locks
又称为写锁,简称X锁,排他锁不能与其他锁并存,如一个事务获取了一个数据行的排他 锁,其他事务就不能再获取该行的锁(共享锁、排他锁),只有该获取了排他锁的事务是可以对 数据行进行读取和修改,(其他事务要读取数据可来自于快照)。
加锁释锁方式: delete / update / insert 默认加上X锁 SELECT * FROM table_name WHERE ... FOR UPDATE commit/rollback
意向锁共享锁(表锁)intention shared locks
表示事务准备给数据行加入共享锁,即一个数据行加共享锁前必须先取得该表的IS(意向锁共享锁)锁, 意向共享锁之间是可以相互兼容的。
意向锁排它锁(表锁)intention exclusive locks
表示事务准备给数据行加入排他锁,即一个数据行加排他锁前必须先取得该表的IX(意向锁排它锁)锁, 意向排它锁之间是可以相互兼容的。
意向锁(IS、IX)是InnoDB数据操作之前自动加的,不需要用户干预
意义:当事务想去进行锁表时,可以先判断意向锁是否存在,存在时则可快速返回该表不能 启用表锁。
自增锁 AUTO-INC Locks
针对自增列自增长的一个特殊的表级别锁;
show variables like 'innodb_autoinc_lock_mode';
默认取值1,代表连续,事务未提交ID永久丢失;
行锁的算法
记录锁Record locks
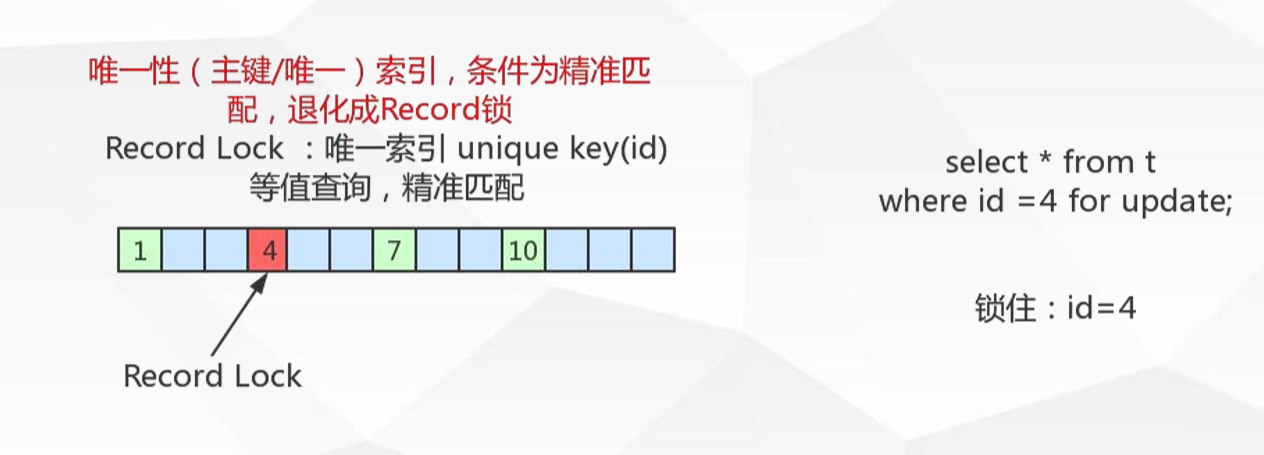
锁住具体的索引项:当sql执行按照唯一性(Primary key、Unique key)索引进行数据的检索时,查询条件等值匹 配且查询的数据是存在,这时SQL语句加上的锁即为记录锁Record locks,锁住具体的索引项。
临键锁Next-key locks
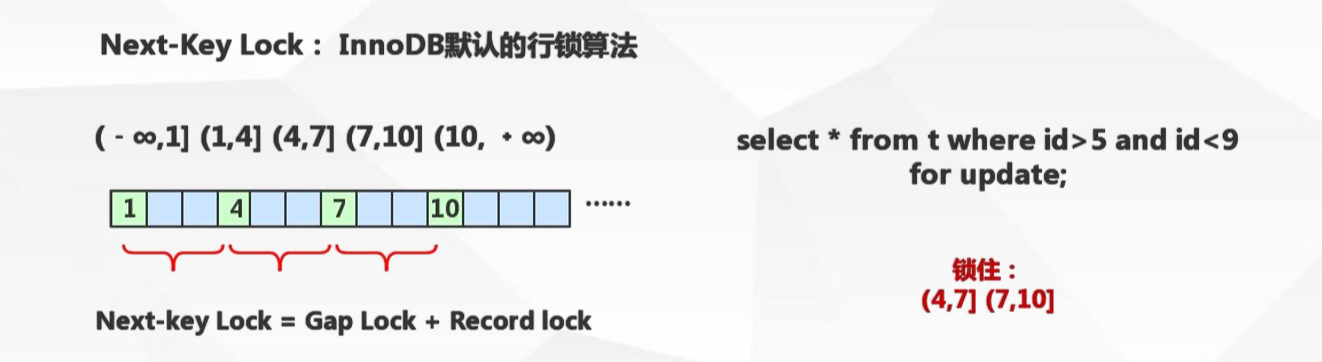
锁住记录+区间(左开右闭):当sql执行按照索引进行数据的检索时,查询条件为范围查找(between and、<、>等)并有数据命中则此时SQL语句加上的锁为Next-key locks,锁住索引的记录+区间(左开右闭)。
如图,一个表的id为主键索引,id分别是1、4、7、10这四条记录,当进行 select * from t where id>5 and id<9 for update 查询时,会将这些记录分成五个区间,然后锁住(4,7]和(7,10]区间,此时如果对7进行修改操作或者插入id=5,6,8,9的数据时都会面临锁等待。
间隙锁Gap Locks
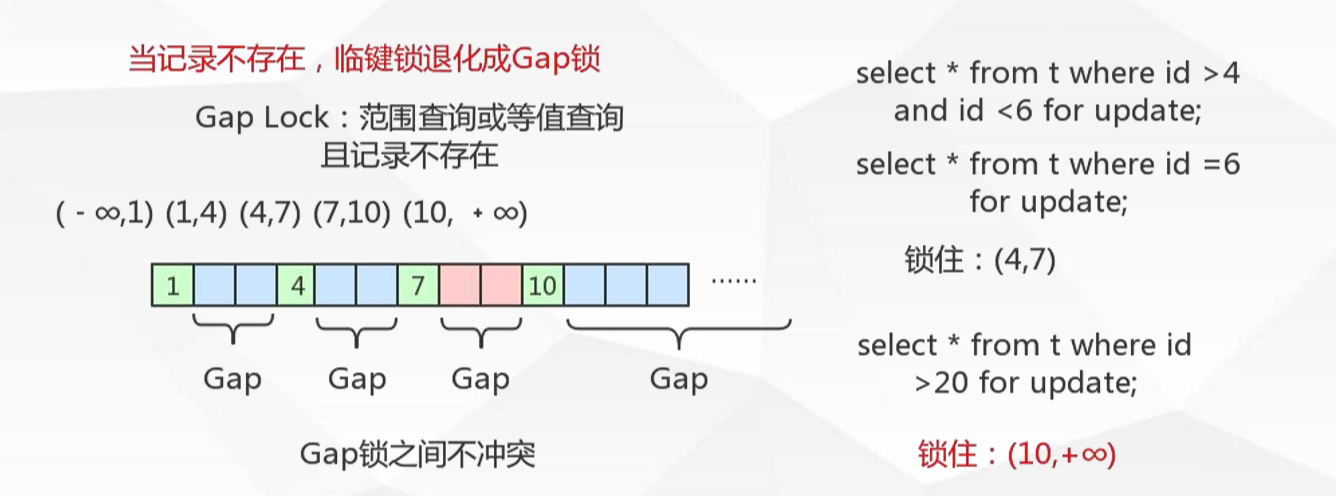
锁住数据不存在的区间(左开右开):当sql执行按照索引进行数据的检索时,查询条件的数据不存在,这时SQL语句加上的锁即为 Gap locks,锁住索引不存在的区间(左开右开)。
Gap只在RR事务隔离级别存在。
MVCC(Multiversion concurrencu control)—多版本并发控制
InnoDB引擎中才有MVCC——并发访问(读或写)数据库时,对正在事务内处理的数据做多版本的管理。以达到用来避免写操作的堵塞,从而引发读操作的并发问题。
当我们建立一个表格时,InnoDB会自动在表格上加上两个列,一个DB_TRX_ID,一个DB_ROLL_PT。如下:

当数据插入时:DB_TRX_ID会记录事务id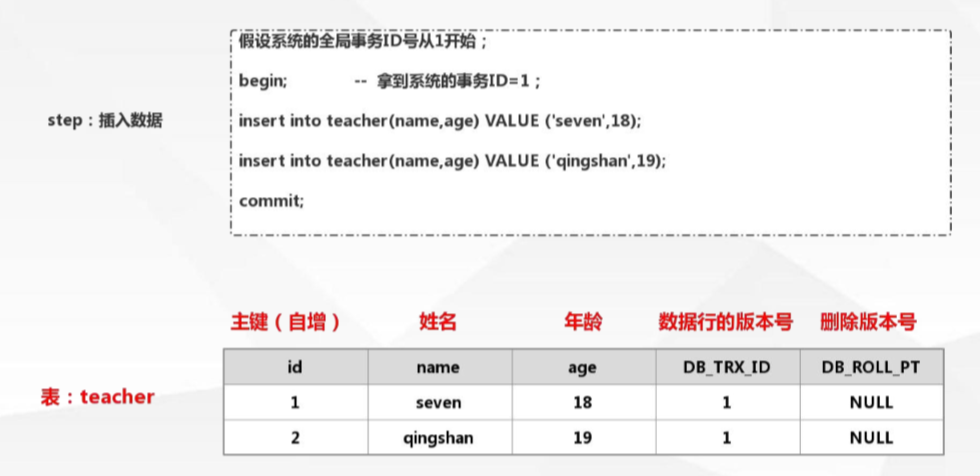
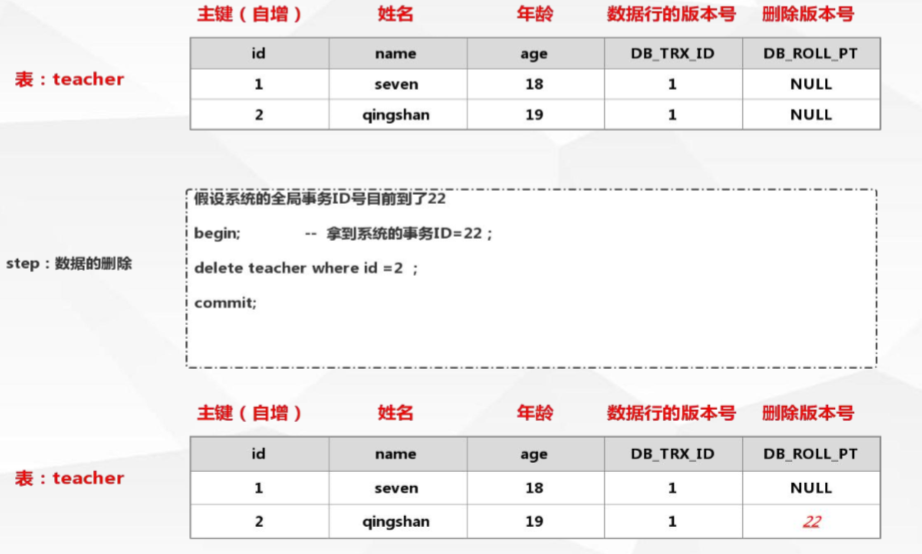
当删除数据时:DB_ROLL_PT列会记录此时的事务id
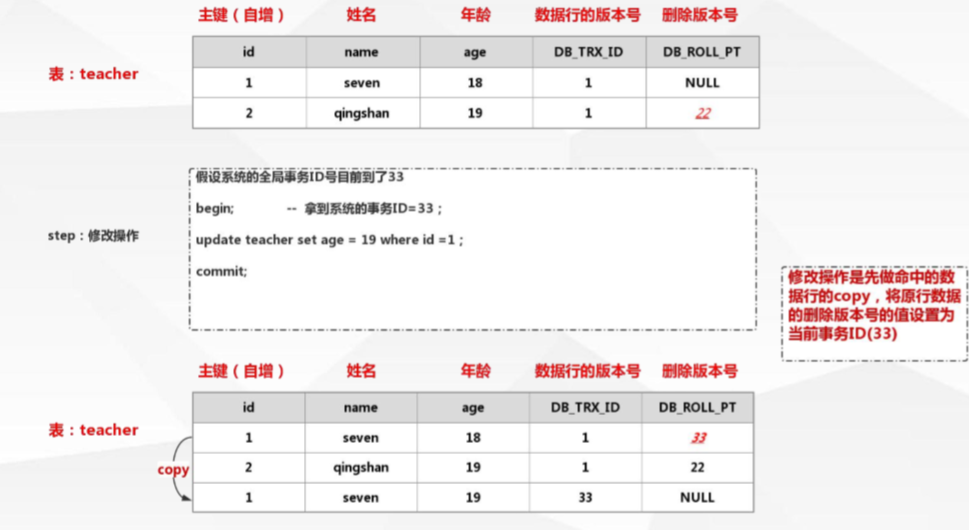
当修改数据时:copy一条数据并且把原来数据的DB_ROLL_PT列加上此时版本号
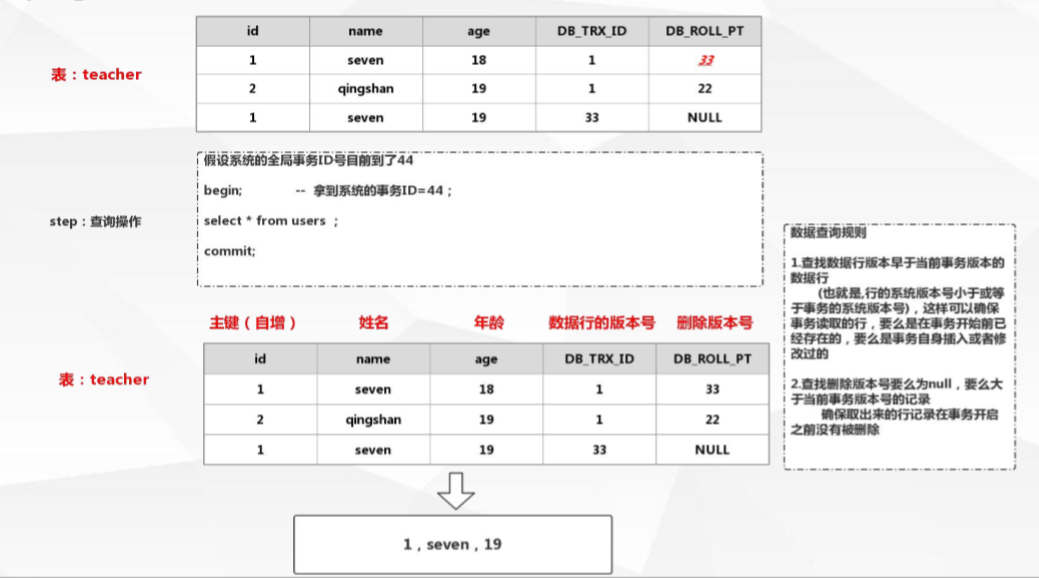
当进行查询时:根据查询规则查询出数据
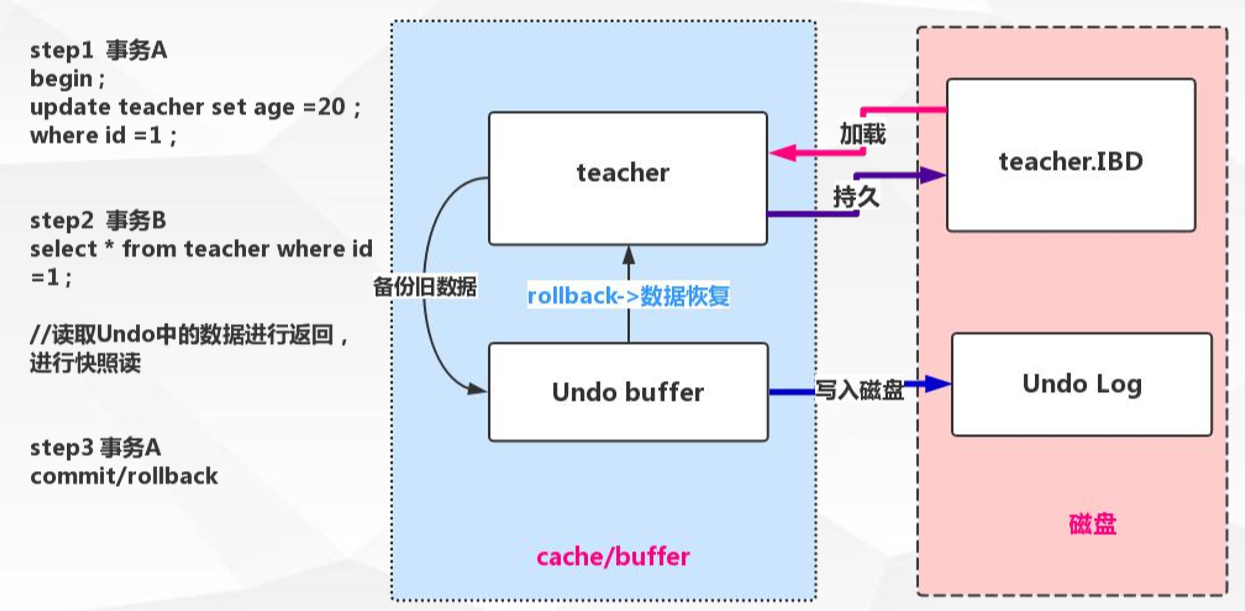
那问题又来了?开启两个事物A和B,在事物A中先进行update语句没有手动提交,事物B中进行select 查询。如果按照mvcc原则那么事物B中就会查询事物A中没有修改的数据。那么mysql会用Undo log日志文件解决这个问题,undo log有两个作用:
Undo Log实现事务原子性: 事务处理过程中如果出现了错误或者用户执行了 ROLLBACK语句,Mysql可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。
Undo log实现多版本并发控制: 事务未提交之前,Undo保存了未提交之前的版本数据,Undo中的数据可作为数据旧版本快照供其他并发事务进行快照读。
mysql的经验总结
1.索引列的数据长度能少则少。
2.索引一定不是越多越好,越全越好,一定是建合适的。
3.匹配列前缀可用到索引 like 9998%,like %999%、like %999用不到索引。
4.where条件中not in和 <> 不等于号无法用到索引。
5.匹配范围值,order by 也可用到索引。
6.多用指定列查询,只返回自己想到的数据列,少用select *。
7.联合索引中如果不是按照索引最左列开始查找,无法使用索引。
8.联合索引中精确匹配最左前列并范围匹配另外一列可以用到的索引。
9.联合索引中如果有某列的范围查询,则其右边的所有列都无法使用索引。
58同城30条军规
一、基础规范
(1)必须使用InnoDB存储引擎 解读:支持事务、行级锁、并发性能更好、CPU及内存缓存页优化使得资源利用率更高
(2)必须使用UTF8字符集 UTF-8MB4 解读:万国码,无需转码,无乱码风险,节省空间
(3)数据表、数据字段必须加入中文注释 解读:N年后谁tm知道这个r1,r2,r3字段是干嘛的
(4)禁止使用存储过程、视图、触发器、Event 解读:高并发大数据的互联网业务,架构设计思路是“解放数据库CPU,将计算转移到服务 层”,并发量大的情况下,这些功能很可能将数据库拖死,业务逻辑放到服务层具备更好的 扩展性,能够轻易实现“增机器就加性能”。数据库擅长存储与索引,CPU计算还是上移吧
(5)禁止存储大文件或者大照片 解读:为何要让数据库做它不擅长的事情?大文件和照片存储在文件系统,数据库里存URI 多好
二、命名规范
(6)只允许使用内网域名,而不是ip连接数据库
(7)线上环境、开发环境、测试环境数据库内网域名遵循命名规范 业务名称:xxx 线上环境:dj.xxx.db 开发环境:dj.xxx.rdb 测试环境:dj.xxx.tdb 从库在名称后加-s标识,备库在名称后加-ss标识 线上从库:dj.xxx-s.db 线上备库:dj.xxx-sss.db
(8)库名、表名、字段名:小写,下划线风格,不超过32个字符,必须见名知意,禁止 拼音英文混用
(9)表名t_xxx,非唯一索引名idx_xxx,唯一索引名uniq_xxx
三、表设计规范
(10)单实例表数目必须小于500
(11)单表列数目必须小于30
(12)表必须有主键,例如自增主键 解读: a)主键递增,数据行写入可以提高插入性能,可以避免page分裂,减少表碎片提升空间和 内存的使用 b)主键要选择较短的数据类型, Innodb引擎普通索引都会保存主键的值,较短的数据类 型可以有效的减少索引的磁盘空间,提高索引的缓存效率 c) 无主键的表删除,在row模式的主从架构,会导致备库夯住
(13)禁止使用外键,如果有外键完整性约束,需要应用程序控制 解读:外键会导致表与表之间耦合,update与delete操作都会涉及相关联的表,十分影响 sql 的性能,甚至会造成死锁。高并发情况下容易造成数据库性能,大数据高并发业务场景 数据库使用以性能优先
四、字段设计规范
(14)必须把字段定义为NOT NULL并且提供默认值 解读: a)null的列使索引/索引统计/值比较都更加复杂,对MySQL来说更难优化 b)null 这种类型MySQL内部需要进行特殊处理,增加数据库处理记录的复杂性;同等条 件下,表中有较多空字段的时候,数据库的处理性能会降低很多 c)null值需要更多的存储空,无论是表还是索引中每行中的null的列都需要额外的空间来标 识 d)对null 的处理时候,只能采用is null或is not null,而不能采用=、in、<、<>、!=、 not in这些操作符号。如:where name!=’shenjian’,如果存在name为null值的记 录,查询结果就不会包含name为null值的记录
(15)禁止使用TEXT、BLOB类型 解读:会浪费更多的磁盘和内存空间,非必要的大量的大字段查询会淘汰掉热数据,导致内
存命中率急剧降低,影响数据库性能
(16)禁止使用小数存储货币 解读:使用整数吧,小数容易导致钱对不上
(17)必须使用varchar(20)存储手机号 解读: a)涉及到区号或者国家代号,可能出现+-() b)手机号会去做数学运算么? c)varchar可以支持模糊查询,例如:like“138%”
(18)禁止使用ENUM,可使用TINYINT代替 解读: a)增加新的ENUM值要做DDL操作 b)ENUM的内部实际存储就是整数,你以为自己定义的是字符串?
五、索引设计规范
(19)单表索引建议控制在5个以内
(20)单索引字段数不允许超过5个 解读:字段超过5个时,实际已经起不到有效过滤数据的作用了
(21)禁止在更新十分频繁、区分度不高的属性上建立索引 解读: a)更新会变更B+树,更新频繁的字段建立索引会大大降低数据库性能 b)“性别”这种区分度不大的属性,建立索引是没有什么意义的,不能有效过滤数据,性 能与全表扫描类似
(22)建立组合索引,必须把区分度高的字段放在前面 解读:能够更加有效的过滤数据
六、SQL使用规范
(23)禁止使用SELECT *,只获取必要的字段,需要显示说明列属性 解读: a)读取不需要的列会增加CPU、IO、NET消耗 b)不能有效的利用覆盖索引
(24)禁止使用INSERT INTO t_xxx VALUES(xxx),必须显示指定插入的列属性 解读:容易在增加或者删除字段后出现程序BUG
(25)禁止使用属性隐式转换 解读:SELECT uid FROM t_user WHERE phone=13812345678 会导致全表扫描,而不 能命中phone索引
(26)禁止在WHERE条件的属性上使用函数或者表达式 解读:SELECT uid FROM t_user WHERE from_unixtime(day)>='2017-02-15' 会导致全 表扫描 正确的写法是:SELECT uid FROM t_user WHERE day>= unix_timestamp('2017-02-15 00:00:00')
(27)禁止负向查询,以及%开头的模糊查询 解读: a)负向查询条件:NOT、!=、<>、!<、!>、NOT IN、NOT LIKE等,会导致全表扫描 b)%开头的模糊查询,会导致全表扫描
(28)禁止大表使用JOIN查询,禁止大表使用子查询 解读:会产生临时表,消耗较多内存与CPU,极大影响数据库性能
(29)禁止使用OR条件,必须改为IN查询 解读:旧版本Mysql的OR查询是不能命中索引的,即使能命中索引,为何要让数据库耗费 更多的CPU帮助实施查询优化呢?
(30)应用程序必须捕获SQL异常,并有相应处理
此内容参考咕泡学院老师讲解的内容,感谢学院分享!















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









