







从这个图像中提取字符,首次查看发现色差很小,不好处理,但是分析了例子处理方式,感觉很巧妙
- 是提取字符的方式,segment_character,这个算子参数很多,但是有很好的处理结果
- 提取出字符之后去除杂点的方式,通过字符在一条水平线上把不在这一水平线上的给去除了。
* This example demonstrates how to segment the expiration date of
* a yoghurt cap. After the segmentation, the characters are classified
* by the mlp ocr classifier using the dotprint font.
*
*
* Display initializations
dev_update_off ()
dev_close_window ()
read_image (Image, 'ocr/yogurt_lid_01')
dev_open_window_fit_image (Image, 0, 0, -1, -1, WindowHandle)
set_display_font (WindowHandle, 16, 'mono', 'true', 'false')
dev_set_draw ('margin')
dev_set_colored (12)
dev_set_line_width (2)
*
read_ocr_class_mlp ('DotPrint_NoRej', OCRHandle)
* Approximate the character's dot size
DotDiameter := 6
* Rough character size
CharHeight := 60
CharWidth := 50
* Number of candidates returned by the classifier
NCandidates := 3
for I := 1 to 4 by 1
read_image (Image, 'ocr/yogurt_lid_' + I$'02')
*
* Segmentation of characters on yoghurt cover
* 提取三个通道
decompose3 (Image, ImageR, ImageG, ImageB)
* diff_of_gauss() emphasizes structures having a characteristic dimension of size
* DotDiameter (line thickness, maximum diameter, ...)
diff_of_gauss (ImageR, DiffOfGauss, DotDiameter / 2, 2)
*规一化
scale_image_max (DiffOfGauss, ImageScaleMax)
* Merge dots
gray_dilation_shape (ImageScaleMax, ImageMax, 3, 3, 'octagon')
* Segment_characters expects black on white characters
*反变一下,把字符变成黑色的
invert_image (ImageMax, ImageInvert)
*从一个给定的区域里面分割字符
*使用这个算子有一个假设,就是字符要比背景黑,否则需要使用invert_image进行一下反色
segment_characters (ImageInvert, ImageInvert, ImageForeground, RegionForeground, 'local_contrast_best', 'false', 'true', 'medium', CharWidth, CharHeight, 20, 40, UsedThreshold)
*连接上小断点
closing_circle (RegionForeground, RegionClosing, 3)
connection (RegionClosing, ConnectedRegions)
select_shape (ConnectedRegions, SelectedRegions, 'height', 'and', 39, 65)
*
* We assume that characters are aligned along a line and
* the regions over or below this line are distractors
*假定字符水平对齐的,比这线上高的或者低的都是错误的选择
* 这个方式可以学习一下
area_center (SelectedRegions, Area, Row, Column)
get_image_size (Image, Width, Height)
*计算数组分布情况
tuple_histo_range (Row, 0, Height, 2 * Height / CharHeight, Histo, BinSize)
*找到数量最多的
tuple_find (Histo, max(Histo), IndMax)
CharRow := BinSize * (IndMax[0] + 0.5)
*选择row在cahrRow 附近的,这样就把左下角的去掉了
select_shape (SelectedRegions, Characters, 'row', 'and', CharRow - CharHeight / 2, CharRow + CharHeight / 2)
*
*上面识别出来位置了,然后下面就是排序一下,然后就是使用mlp识别了
* Read out the characters on the yoghurt cover
sort_region (Characters, SortedRegions, 'character', 'true', 'row')
do_ocr_word_mlp (SortedRegions, ImageForeground, OCRHandle, '\\d{4}[A-Z]', NCandidates, 2, Class, Confidence, Word, Score)
*
DateString := Word{0} + Word{1} + '.' + Word{2} + Word{3} + '.'
BatchID := Word{4}
*
dev_display (Image)
dev_display (SortedRegions)
disp_message (WindowHandle, 'Best before: ' + DateString + '\nBatch ID : ' + BatchID, 'window', 12, 12, 'black', 'true')
if (I < 4)
disp_continue_message (WindowHandle, 'black', 'true')
stop ()
endif
endfor
clear_ocr_class_mlp (OCRHandle)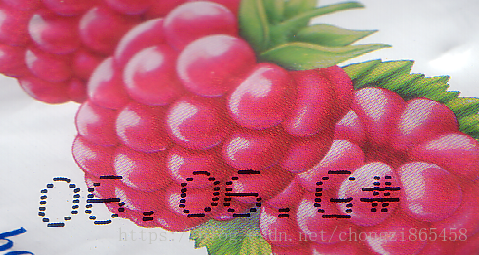














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









