






一、环境搭建
1、准备三台机器、配置mongo.conf文件
Master节点的配置文件添加以下信息
ogpath=/data/logs/mongo/master.log
logappend=true
fork=true
port=9084
dbpath=/data/mongodb_data
pidfilepath=/data/logs/mongo/master.pid
nojournal=true
storageEngine=wiredTiger
#replSet=nubia_stat
oplogSize=50
bind_ip=10.206.19.188slave节点添加以下信息
logpath=/data/logs/mongo/slave.log
logappend=true
fork=true
port=9084
dbpath=/data/mongodb_data
pidfilepath=/data/logs/mongo/slave.pid
nojournal=true
storageEngine=wiredTiger
#replSet=nubia_stat
oplogSize=50
bind_ip=10.206.19.187
仲裁节点添加一下信息:
logpath=/data/logs/mongo/arbiter.log
logappend=true
fork=true
port=9084
dbpath=/data/mongodb_data
pidfilepath=/data/logs/mongo/arbiter.pid
nojournal=true
storageEngine=wiredTiger
#replSet=nubia_stat
oplogSize=50
bind_ip=10.206.19.189
2、三台机器上分别启动mongo,指定副本集名称nubia_stat
./mongod --replSet nubia_stat -f ../etc/mongo.conf --fork
停止mongo不能使用kill -9,使用以下命令:
./mongod --shutdown --dbpath /data/mongodb_data/
3、进入其中一台机器的mongo客户端,这里是进入188,配置副本集,把三台机器互通
./mongo 10.206.19.188:27017
>use admin
>cfg={_id:"nubia_stat",members:[{_id:0,host:'10.206.19.188:27017'},{_id:1,host:'10.206.19.187:27017'},{_id:2,host:'10.206.19.189:27017',arbiterOnly:true}]};
/**
"_id": 副本集的名称
"members": 副本集的服务器列表
"_id": 服务器的唯一ID
"host": 服务器主机
"priority": 是优先级,默认为1,优先级0为被动节点,不能成为活跃节点。优先级不为0则按照有大到小选出活跃节点。
"arbiterOnly": 仲裁节点,只参与投票,不接收数据,也不能成为活跃节点。
**/
#初始化副本集信息
>rs.initiate(cfg)
#查看集群节点的状态
>rs.status();
集群搭建完毕。
二、集群副本集验证:
10.206.19.188:27017(主节点)、10.206.19.187:27017(复制节点)、0.206.19.189:27017(仲裁节点)
1、验证故障转移功能
第一步、查看哪台机器是master:
188:是master节点
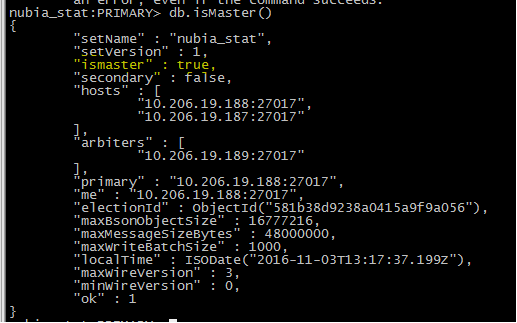
187:不是master节点

189:不是master节点

第二步:主节点宕机,将会选举187切换成主节点

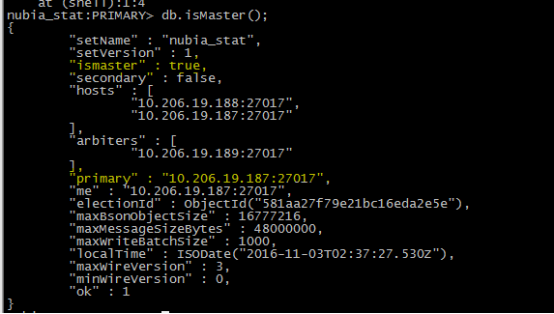
第三步:188重启,将作为复制节点
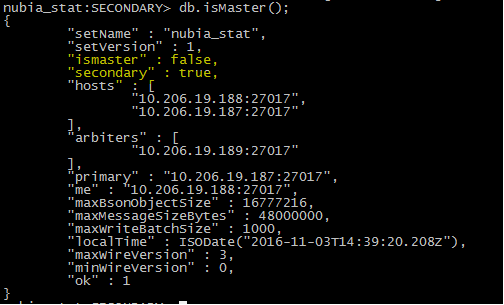
故障转移验证通过。
2、验证数据复制
目前由于188重启后已经变成secondary节点,也就是从节点
187是primary节点,也就是master节点,用于数据写入。
(1)在187上新建数据库nubia_stat_db,新建表people,把表里面的内容置空。

查看此时188上的内容:存在这张表,且内容为空
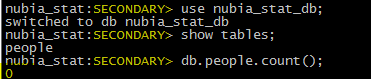
2)在187上给people插入数据2条

(3)在188上看这两条数是否同步:出现2,表示已经同步
![]()
数据复制验证通过。
———————————————————————————————————————
副本集中数据同步过程:Primary节点写入数据,Secondary通过读取Primary的oplog得到复制信息,开始复制数据并且将复制信息写入到自己的oplog。如果某个操作失败,则备份节点停止从当前数据源复制数据。如果某个备份节点由于某些原因挂掉了,当重新启动后,就会自动从oplog的最后一个操作开始同步,同步完成后,将信息写入自己的oplog,由于复制操作是先复制数据,复制完成后再写入oplog,有可能相同的操作会同步两份,不过MongoDB在设计之初就考虑到这个问题,将oplog的同一个操作执行多次,与执行一次的效果是一样的。简单的说就是:
当Primary节点完成数据操作后,Secondary会做出一系列的动作保证数据的同步:
1:检查自己local库的oplog.rs集合找出最近的时间戳。
2:检查Primary节点local库oplog.rs集合,找出大于此时间戳的记录。
3:将找到的记录插入到自己的oplog.rs集合中,并执行这些操作。
副本集的同步和主从同步一样,都是异步同步的过程,不同的是副本集有个自动故障转移的功能。其原理是:slave端从primary端获取日志,然后在自己身上完全顺序的执行日志所记录的各种操作(该日志是不记录查询操作的),这个日志就是local数据 库中的oplog.rs表,默认在64位机器上这个表是比较大的,占磁盘大小的5%,oplog.rs的大小可以在启动参数中设 定:--oplogSize 1000,单位是M。
注意:在副本集的环境中,要是所有的Secondary都宕机了,只剩下Primary。最后Primary会变成Secondary,不能提供服务。
默认情况下,Secondary是不提供服务的,即不能读和写。会提示:
error: { "$err" : "not master and slaveOk=false", "code" : 13435 }
在特殊情况下需要读的话则需要:
输入:rs.slaveOk() #只对当前连接有效
链接:http://www.cnblogs.com/zhoujinyi/p/3554010.html
http://m.blog.csdn.net/article/details?id=51749739
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









