






##JDK
也可参考 http://my.oschina.net/topeagle/blog/484363
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u101-b13/jdk-8u101-linux-x64.tar.gz
tar -xvzf jdk-8u101-linux-x64.tar.gz
mv jdk-8u101-linux-x64 /usr/local/jdk
vi ~/.bashrc
//最后追加
export JAVA_HOME=/usr/local/jdk
export JAVA_BIN=$JAVA_HOME/bin
export JAVA_LIB=$JAVA_HOME/lib
export CLASSPATH=.:$JAVA_LIB/tools.jar:$JAVA_LIB/dt.jar
export PATH=$JAVA_BIN:$PATH
//环境变量生效
source ~/.bashrc
java -version (如果还是不行,上述再来一次)
Elastic 2.3.5
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.3.5/elasticsearch-2.3.5.tar.gz
tar -zxvf elasticsearch-2.3.5.tar.gz
mv elasticsearch-2.3.5 /usr/local/elasticsearch
groupadd elasticgroup
useradd elastic -g elasticgroup -p /usr/local/elasticsearch
chown -R elastic:elasticgroup /usr/local/elasticsearch
配置文件
vi /usr/local/elasticsearch/conf/elasticsearch.yml
//修改对应配置
vi /usr/local/elasticsearch/bin/elasticsearch.in.sh
//修改内存为合适状态,不要超过32G,不要超过系统内存的一半
##plugin
bin/plugin install mobz/elasticsearch-head
Liunx 优化
内存分配不要大于32G,预留一半内存。
vi ~/elasticsearch.yml
bootstrap.memory_lock: true
分片多的话,可以提升建立索引的能力,5-20个比较合适。 如果分片数过少或过多,都会导致检索比较慢。 分片数过多会导致检索时打开比较多的文件,另外也会导致多台服务器之间通讯。 而分片数过少会导至单个分片索引过大,所以检索速度也会慢。 建议单个分片最多存储20G左右的索引数据,所以,分片数量=数据总量/20G
shards 最好不要超过3个,建议添加节点(也可参考这个值来适当加节点数)
定时优化、合并、删除已经打了删除标记的文档
项目开始导入数据,副本设置为 0,加快导入数据,刷新时间设置为 -1,大大加快导入时间。导入完毕后记得还原
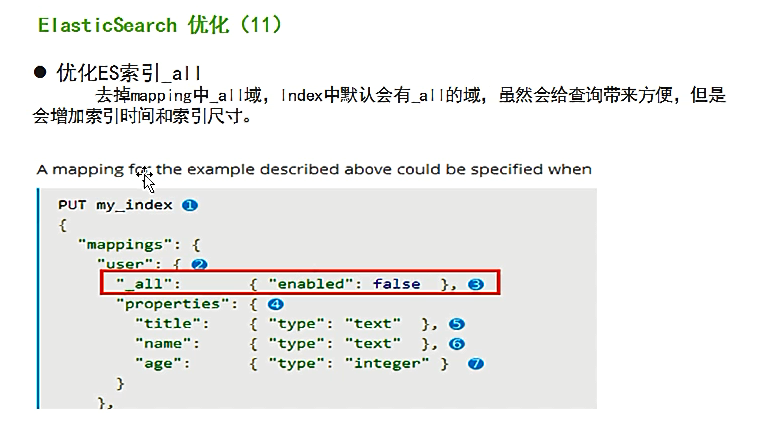
禁用_all字段 查看设置代码
消灭警告(前台运行可见 或 日志)
关闭SELINUX
// 查看 SELIUNX 状态
# sestatus -v
// 如果是 disabled 标示已经关闭
方式1
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
方式2
# vi /etc/sysconfig/selinux
// 设置 SELINUX=disabled
修改最大文件打开数
ulimit -a
ulimit -n 32000(设置,也可设置64000)
# 最后追加
vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
:wq
ulimit -a
//重启一下















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}