






代码下载地址:https://github.com/tazhigang/big-data-github.git
一、概述
- 自定义一个InputFormat
- 改写RecordReader,实现一次读取一个完整文件封装为KV
- 在输出时使用SequenceFileOutPutFormat输出合并文件
二、案例需求
- 需求: 无论hdfs还是mapreduce,对于小文件都有损效率,实践中,又难免面临处理大量小文件的场景,此时,就需要有相应解决方案。将多个小文件合并成一个文件SequenceFile,SequenceFile里面存储着多个文件,存储的形式为文件路径+名称为key,文件内容为value。
- 输入数据
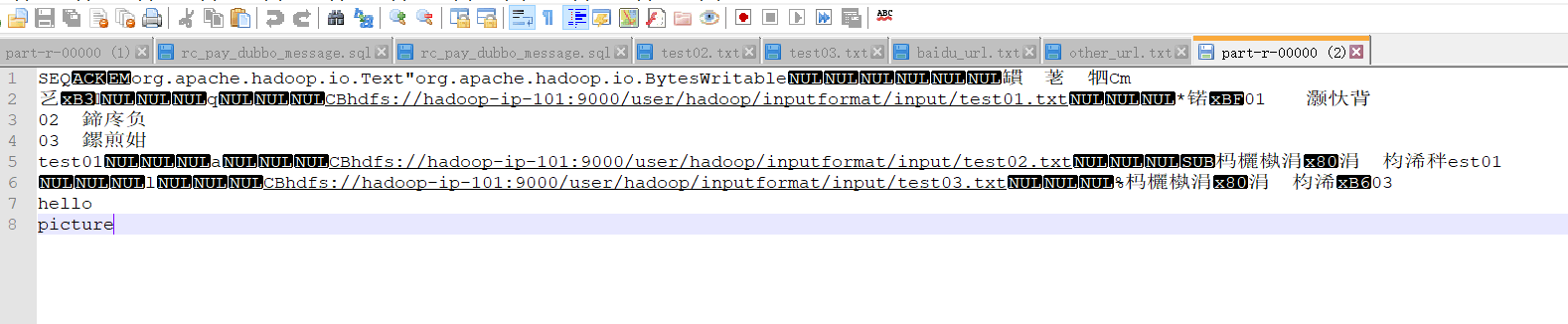
=====================================test01.txt================================= 01 小米 02 华为 03 格力 test01 =====================================test02.txt================================= 这是一个文件test02 =====================================test03.txt================================= 这是一个文件03 hello picture - 最终输出文件格式(由于是二进制文件所以只能大概看出:改文件是有以上三个文件合并而成,并且文件内从是文件路径及文件内容组成)
SEQorg.apache.hadoop.io.Text"org.apache.hadoop.io.BytesWritable 罆 荖牭Cm
乥? q CBhdfs://hadoop-ip-101:9000/user/hadoop/inputformat/input/test01.txt *锘?1 灏忕背
02 鍗庝负
03 鏍煎姏
test01 a CBhdfs://hadoop-ip-101:9000/user/hadoop/inputformat/input/test02.txt 杩欐槸涓€涓枃浠秚est01
l CBhdfs://hadoop-ip-101:9000/user/hadoop/inputformat/input/test03.txt %杩欐槸涓€涓枃浠?3
hello
picture
- 分析:小文件的优化无非以下几种方式:
- (1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS
- (2)在业务处理之前,在HDFS上使用mapreduce程序对小文件进行合并
- (3)在mapreduce处理时,可采用CombineTextInputFormat提高效率
- 具体实现:本节采用自定义InputFormat的方式,处理输入小文件的问题。
- (1)自定义一个InputFormat
- (2)改写RecordReader,实现一次读取一个完整文件封装为KV
- (3)在输出时使用SequenceFileOutPutFormat输出合并文件
三、创建maven项目
- 项目结构
- 代码 :
- HDFSUtil.java
package com.ittzg.hadoop.inputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.net.URI; /** * @email: tazhigang095@163.com * @author: ittzg * @date: 2019/7/6 20:44 */ public class HDFSUtil { Configuration configuration = new Configuration(); FileSystem fileSystem = null; /** * 每次执行添加有@Test注解的方法之前调用 */ @Before public void init(){ configuration.set("fs.defaultFs","hadoop-ip-101:9000"); try { fileSystem = FileSystem.get(new URI("hdfs://hadoop-ip-101:9000"),configuration,"hadoop"); } catch (Exception e) { throw new RuntimeException("获取hdfs客户端连接异常"); } } /** * 每次执行添加有@Test注解的方法之后调用 */ @After public void closeRes(){ if(fileSystem!=null){ try { fileSystem.close(); } catch (IOException e) { throw new RuntimeException("关闭hdfs客户端连接异常"); } } } /** * 上传文件 */ @Test public void putFileToHDFS(){ try { fileSystem.copyFromLocalFile(new Path("F:\\big-data-github\\hadoop-parent\\hadoop-inputformat\\src\\main\\resources\\file\\test01.txt"),new Path("/user/hadoop/inputformat/input/test01.txt")); fileSystem.copyFromLocalFile(new Path("F:\\big-data-github\\hadoop-parent\\hadoop-inputformat\\src\\main\\resources\\file\\test02.txt"),new Path("/user/hadoop/inputformat/input/test02.txt")); fileSystem.copyFromLocalFile(new Path("F:\\big-data-github\\hadoop-parent\\hadoop-inputformat\\src\\main\\resources\\file\\test03.txt"),new Path("/user/hadoop/inputformat/input/test03.txt")); } catch (IOException e) { e.printStackTrace(); System.out.println(e.getMessage()); } } /** * 创建hdfs的目录 * 支持多级目录 */ @Test public void mkdirAtHDFS(){ try { boolean mkdirs = fileSystem.mkdirs(new Path("/user/hadoop/inputformat/input")); System.out.println(mkdirs); } catch (IOException e) { e.printStackTrace(); } } } - MyRecordReader.java
package com.ittzg.hadoop.inputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; /** * @email: tazhigang095@163.com * @author: ittzg * @date: 2019/7/7 21:44 */ public class MyRecordReader extends RecordReader<NullWritable, BytesWritable> { private FileSplit fileSplit; private Configuration configuration; private BytesWritable value = new BytesWritable(); private boolean isProcess = false; //表示是否读取完成文件内容 public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { this.fileSplit = (FileSplit) split; this.configuration = context.getConfiguration(); } public boolean nextKeyValue() throws IOException, InterruptedException { if(!isProcess){ // 获取文件在Hdfs上的路径,并读取文件内容 FileSystem fileSystem = null; FSDataInputStream inputStream = null; try { Path path = fileSplit.getPath(); fileSystem = path.getFileSystem(configuration); inputStream = fileSystem.open(path); byte[] buf = new byte[(int) fileSplit.getLength()]; IOUtils.readFully(inputStream,buf,0,buf.length); value.set(buf,0,buf.length); } finally { IOUtils.closeStream(fileSystem); } isProcess = true; return true; } return false; } public NullWritable getCurrentKey() throws IOException, InterruptedException { return NullWritable.get(); } public BytesWritable getCurrentValue() throws IOException, InterruptedException { return value; } public float getProgress() throws IOException, InterruptedException { return 0; } public void close() throws IOException { } } - MyFileInputFormat.java
package com.ittzg.hadoop.inputformat; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.ByteWritable; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import java.io.IOException; /** * @email: tazhigang095@163.com * @author: ittzg * @date: 2019/7/7 21:40 */ public class MyFileInputFormat extends FileInputFormat<NullWritable,BytesWritable> { @Override protected boolean isSplitable(JobContext context, Path filename) { return false; } @Override public RecordReader<NullWritable, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { MyRecordReader myRecordReader = new MyRecordReader(); myRecordReader.initialize(split,context); return myRecordReader; } } - MyInputFormatDriver.java
package com.ittzg.hadoop.inputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; import java.io.IOException; import java.net.URI; /** * @email: tazhigang095@163.com * @author: ittzg * @date: 2019/7/7 21:45 */ public class MyInputFormatDriver { static class MyMapper extends Mapper<NullWritable,BytesWritable,Text,BytesWritable>{ Text filePath = new Text(); @Override protected void setup(Context context) throws IOException, InterruptedException { FileSplit inputSplit = (FileSplit) context.getInputSplit(); Path path = inputSplit.getPath(); filePath.set(path.toString()); } @Override protected void map(NullWritable key, BytesWritable value, Context context) throws IOException, InterruptedException { System.out.println(value); context.write(filePath,value); } } public static void main(String[] args) throws Exception { String input = "hdfs://hadoop-ip-101:9000/user/hadoop/inputformat/input"; String output = "hdfs://hadoop-ip-101:9000/user/hadoop/inputformat/output"; Configuration conf = new Configuration(); conf.set("mapreduce.app-submission.cross-platform","true"); Job job = Job.getInstance(conf); job.setJarByClass(MyInputFormatDriver.class); job.setInputFormatClass(MyFileInputFormat.class); job.setOutputFormatClass(SequenceFileOutputFormat.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(BytesWritable.class); job.setMapperClass(MyMapper.class); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop-ip-101:9000"),conf,"hadoop"); Path outPath = new Path(output); if(fs.exists(outPath)){ fs.delete(outPath,true); } FileInputFormat.setInputPaths(job, new Path(input)); FileOutputFormat.setOutputPath(job, outPath); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
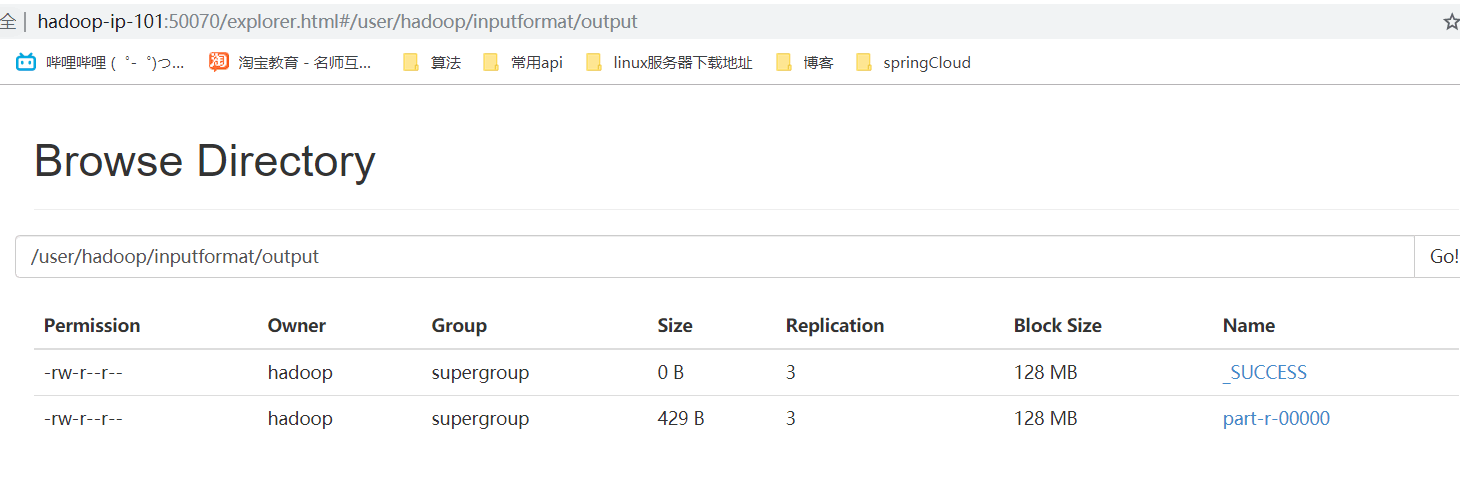
四、运行结果
- 网页浏览
- 文件内容下载浏览















 203
203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









