






1、requests。抓取单张图片:F12打开网页源码,下载网上某张图片:(视频同理)
(1)import requests
#请求头
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.7.0.16013'}
#图片地址
url='https://ss1.baidu.com/70cFfyinKgQFm2e88IuM_a/forum/pic/item/3b87e950352ac65ca58df926faf2b21192138adf.jpg'
response=requests.get(url,headers=headers)
#写进文件
with open("d:\\1.jpg",'wb') as f:
f.write(response.content) #图片返回response.content的二进制文件
(2)#认证设置,当进入网站时先输入用户名和密码
import requests
from requests.auth import HTTPBasicAuth
r=requests.get(url,auth=HTTPBasicAuth('username','password'))
2、使用urllib
格式最好写成request和response格式
import urllib.request
#先请求
request=urllib.request.Request(url)
#获得相应
response=urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
(1)请求头:headers={'User-Agent':' '}, headers放在Request中
(2)爬取需要登录验证的网站用到cookie
有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了。http://cuiqingcai.com/968.html
3、BeautifulSoup库
from bs4 import BeautifulSoup
soup=BeautifulSoup(html,'html.paser')
(1)soup.title.string 选择title标签的文本内容
(2)某(p)标签的子节点,不输出孙节点
soup.p.contents 返回类型是一个列表
soup.p.children for child in enumerate(soup.p.children) 遍历子节点 返回类型是一个迭代器
(3)获取所有的子孙节点
soup.p.descendants
(4)父节点和祖先节点
soup.p.parent 父节点
soup.p.parents 祖先节点
(5)兄弟节点
soup.p.next_siblings 后面的兄弟节点
soup.p.previous_siblings 前面的兄弟节点
(6)find_all(name,attrs,recursive,text,) 根据标签、属性、内容查找文档
for ul in soup.find_all('ul'):
ul.find_all('li') 输出ul标签下li标签组成的列表

根据属性查找

find_all(attrs={'id':'list-1'})属性以列表的字典的形式写入,为了简化,可以用find_all(id='list-1')代替,两者是等效的。
若用find_all(class_='element')查找,因为class是python关键词,需要加下划线_
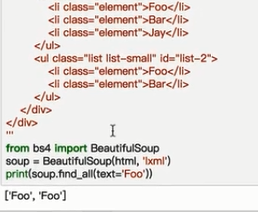
以文本内容查找时,返回的只是匹配的文本内容,并不返回相应的标签
(7)find(name,attrs,recursive,text,) 返回的是单个元素,find_all返回所有的匹配结果
find_parents() 返回所有的祖先节点 find_parent()返回直接父节点
find_next_siblings() 返回后面所有兄弟节点 find_next_sibling() 返回后面第一个兄弟节点
find_previous_siblings()返回前面所有的兄弟节点 find_previous_sibling() 返回前面第一个兄弟节点
find_all_next() 返回节点后所有符合条件的节点 find_next() 返回第一个符合条件的节点
find_all_previous() 返回节点前所有符合条件的节点 find_previous() 返回节点前第一个符合条件的节点
(8)CSS选择器
通过select()直接传入css选择器即可完成选择

选择class标签的属性,在属性前面加点. ,选择id标签的属性,才属性前面加#,选择标签时直接写标签名。
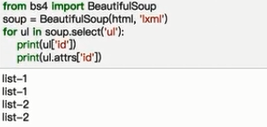
获取属性,直接把需要获取属性的标签用中括号[ ]括起来
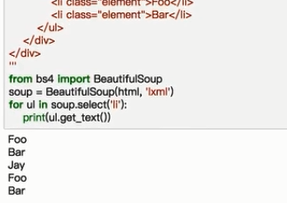
get_text()获取文本内容
4、pyquery
from pyquery import PyQuery as pq
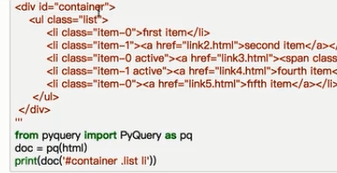
pyquery初始化直接pq(网页、链接或文件路径)。
(1)查找子元素

find查找所有符合匹配的子元素,items.children()查找直接子元素(可以传入参数可以不传)


获取兄弟元素,'.list .item-0.active' list与item属于不同层次,所以中间有空格,active与item并列,不加空格
(2)遍历
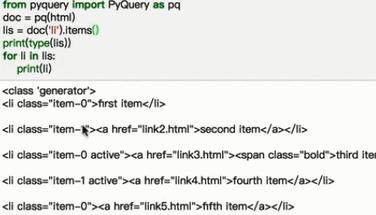
用.item()方法遍历
(3)获取属性

active与a之间有空格,表示a是包含的部分
(4)获取文本

(5)获取html

(6)DOM操作
移除和添加节点

修改添加属性

remove方法
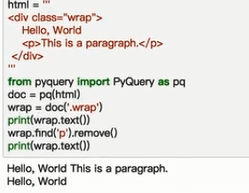
text()得到的是全部的文本,若只想得到helloworld,用remove()方法移除
(7)伪类选择器

first-child获取第一个标签,last-child获取最后一个,nth-child(2)第2个标签,gt(2)比2大的标签,















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









