






http://blog.csdn.net/pipisorry/article/details/44999703
机器学习Machine Learning - Andrew NG courses学习笔记
Application Example Photo OCR应用实例照片
OCR(Optical Character Recognition)光学文字辨识
Problem Description and Pipeline问题描述和管道
three reasons to centered around an application called Photo OCR:first to show you an example of how a complex machine learning system can be put together.Second, once told the concepts of a machine learning a pipeline and how to allocate resources when you're trying to decide what to do next.Finally, the Photo OCR problem also tell you about a couple more interesting ideas for machine learning.One is how to apply machine learning to computer vision, and second is the idea of artificial data synthesis.
Photo OCR pipeline
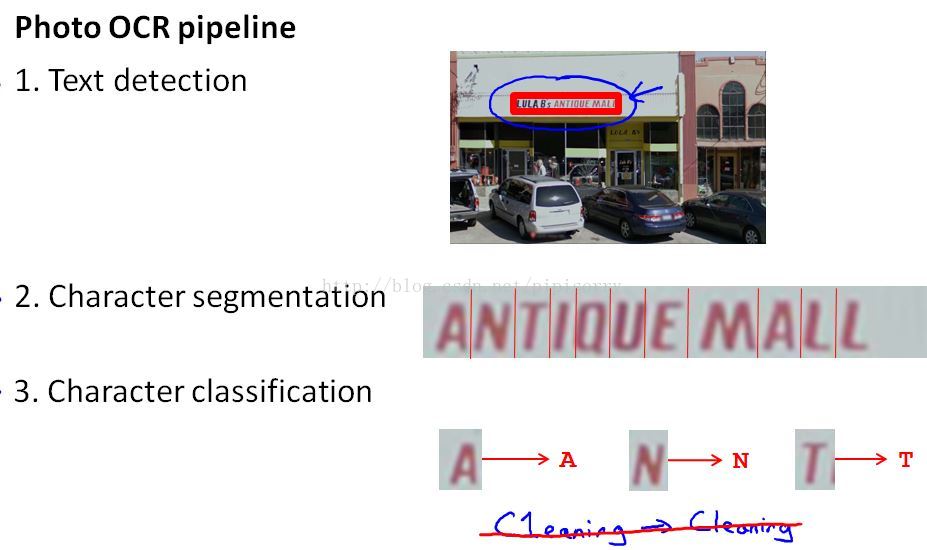
Note:some photo OCR systems do more complex things,likespelling correction at the end.For example character segmentation and character classification system tells you that it sees word c 1 e a n i n g. Then,spelling correction system might tell you that this is probably the word 'cleaning', and your character classification algorithm had just mistaken the l for a 1.
Note:
1. A system like this is called a machine learning pipeline.In particular, here's a picture showing the photo OCR pipeline.
2. pipelines are common, where you can have multiple modules,each of which may be machine learning component,or sometimes it may not be a machine learning component but to have a set of modules that act one after another on some piece of data in order to produce the output you want.
3. designing a machine learning system one of the most important decisions will often bewhat exactly is the pipeline that you want to put together.In other words, given the photo OCR problem, how do you break this problem down into a sequence of different modules.And each the performance of each of the modules in your pipeline.will often have a big impact on the final performance of your algorithm.
Sliding Windows滑窗
行人检测
{start with a simpler example of pedestrian detection and we'll then later go back to Ideas that were developed in pedestrian detection and apply them to text detection}

Note:
1. pedestrians detection is slightly simpler than text detection just for the reason that theaspect ratio(the ratio between the height and the width of these rectangles) of most pedestrians are pretty similar.Just using a fixed aspect ratio for these rectangles that we're trying to find.
2. Although for pedestrian detection, the height of these rectangles can be differentdepending on how far away they are, but the aspect ratio is the same.
Supervised learning for pedestriandetection行人检测的监督学习

Note:
1. standardize on this aspect ratio of 82 by 36 and we could have chosen some rounded number like 80 by 40 or something, but 82 by 36 seems alright.
2. collect large training sets of positive and negative examples.Then train in your network or some other to take this input, an MS patch of dimension 82 by 36, and to classify 'y' and to classify that image patch as either containing a pedestrian or not.
Sliding window detection滑窗检测



Note:
1. start by taking a rectangular patch of this image.that's maybe a 82 X 36 patch of this image,and run that image patch through our classifier to determine whether or not there is a pedestrian in that image patch,and hopefully our classifier will return y equals 0 for that patch, since there is no pedestrian.
2. Next we slide that green rectangle over a bit and then run that new image patch through our classifier to decide if there's a pedestrian there.
3. The amount by which you shift the rectangle over each time is a parameter, that's sometimes called thestep size of the parameter, sometimes also called the slide parameter. If you step this one pixel at a time that usually performs best, that is more computation expensive, and so using a step size of4 pixels or 8 pixels at a timeor some large number of pixels might be more common.
4. continue stepping the rectangle over to the right a bit at a time and running each of these patches through a classifier.until eventually, run all of these different image patches at some step size or some stride through your classifier.
5. next start to look at larger image patches.So now let's take larger images patches, like those shown here and run those through the crossfire as well.
6. take a larger image patch means taking that larger image patch, and resizing it down to 82 X 36.
7. Finally you can do this at an even larger scales and run that side of Windows to the end And after this whole process hopefully your algorithm will detect whether theres pedestrian appears in the image.
8. 总结:That's how you train a the classifier, and then use a sliding windows classifier,or use a sliding windows detector in order to find pedestrians in the image.
Text detection文本检测
训练模型

Note:
1. positive examples are going to be patches of images where there is text.
2. Having trained this we can now apply it to a new image, into a test set image.
滑窗检测
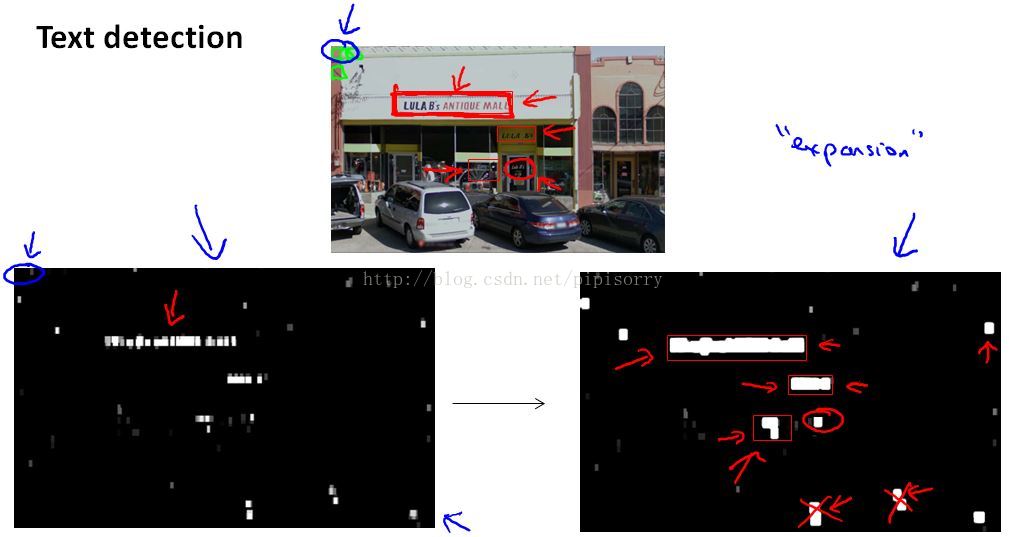
Note:
1. 图2中the white region show where my text detection system has found text and so the axis' of these two figures(图1+图2) are the same.
2. And different shades of grey correspond to the probability that was output by the classifier.
3. 图3 - expansion operator: take the output of the classifier and apply to it, takes each of thewhite regions and expands that.Mathematically, the way you implement that is,for every pixel we are going to ask, is it withing some distance of a white pixel in the left image.If a specific pixel is within, say, five pixels or ten pixels of a white pixel in the leftmost image, then also color that pixel white in the rightmost image.
4. Finally,look at right most image and just look at the connecting components and look at the as white regions anddraw bounding boxes(图3中的红色框框) around them.if we use a simple heuristic(启发式教育法) to rule out rectangles whose aspect ratios look funny because we know that boxes around text should be much wider than they are tall.And so if we ignore the thin, tall blobs like these red cross.we then draw a the rectangles around the ones whose aspect ratio thats a height to what ratio looks like for text regions, then we can draw the bounding boxes around this text region.
5. now just cut out these image regions and then use later stages of pipeline to try to meet the texts.
character segmentation字符分割
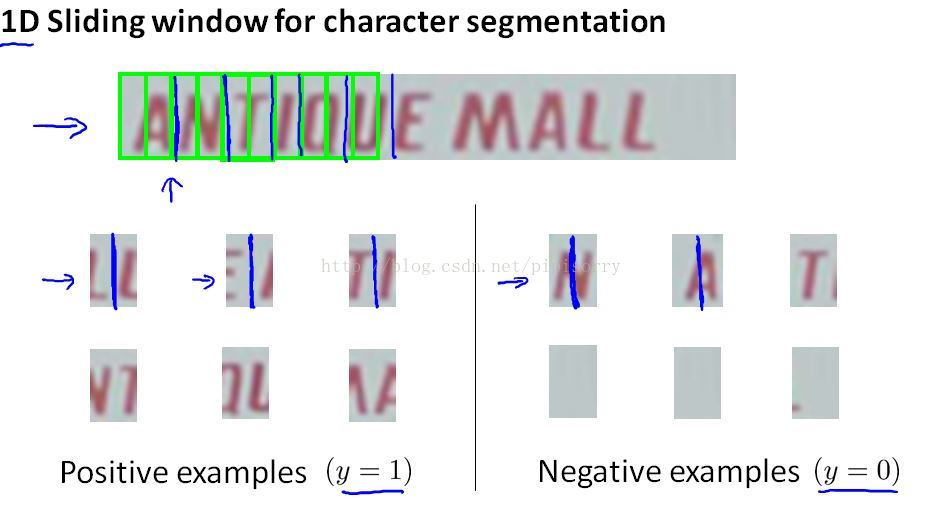



Note:
1. again use a supervised learning algorithm with some set of positive and some set of negative examples, what were going to do is look in the image patch and try to decide if there is split between two characters right in the middle of that image match.
2. Having trained such a classifier,we can then run this on this sort of text that our text detection system has pulled out.As we start by looking at that rectangle, and ask,"Gee, does it look like the middle of that green rectangle, does it look like the midpoint between two characters?".
Character classification文字分类
Note:apply a standard supervised learning within maybe on your network to take it's input, an image like that and classify which alphabet or which 26 characters A to Z, or maybe we should have 36 characters if you have the numerical digits as well, the multi class classification problem where you take it's input and image contained a character and decide what is the character that appears in that image.
Getting Lots of Data and Artificial Data获取大量数据和人工数据
{the most reliable ways to get a high performance machine learning system is to take a low bias learning algorithm and to train it on a massive training set}
where did you get so much training data from?
artificial data synthesis, this doesn't apply to every single problem, and to apply to a specific problem, often takes some thought and innovation and insight.But if this idea applies to your machine, only problem, it can sometimes be a an easy way to get a huge training set to give to your learning algorithm.
The idea of artificial data synthesis comprises of two variations, main the first is if we are essentially creating data from [xx], creating new data from scratch.And the second is if we already have it's small label training set and we somehow have amplify(扩大) that training set or use a small training set to turn that into a larger training set.
Character recognition文字识别中如何生成人工数据
idea1: generating data from scratch using random fonts

Note:
1. For this particular example, I've chosen a square aspect ratio.So we're takingsquare image patches.And the goal is to take an image patch and recognize the character in the middle of that image patch.
2. For simplicity,treat these images as grey scale images, rather than color images.using color doesn't seem to help that much for this particular problem.
3. 获取人工合成数据集get a synthetic training set,take characters from different fonts,and paste these characters against different random backgrounds.And then apply maybe a little blurring(模糊) operators -- just the sharing and scaling and little rotation operations.
idea2: take an existing example and and introducing distortions通过引入扭曲合成数据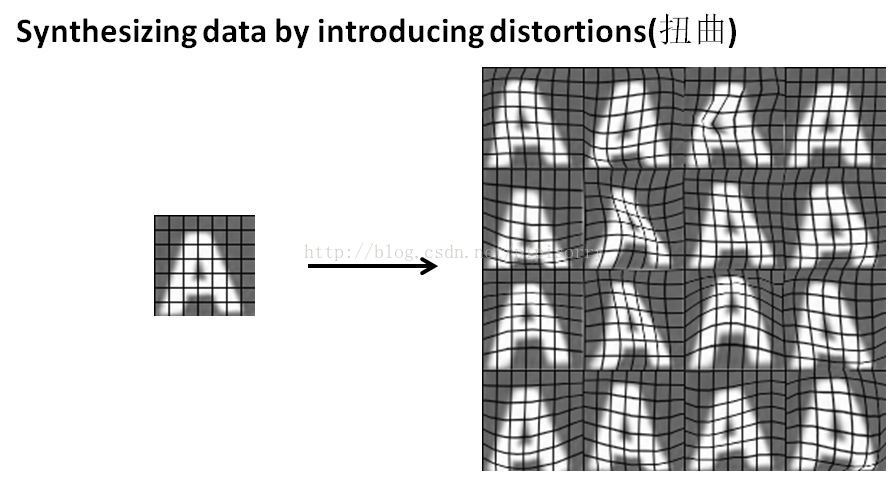
Note:the grid lines overlayed the image just for the purpose of illustration.
Note:collect just one labelled example fall of the 01205, and by synthesizing additional distortions,byintroducing different background sounds,we've now multiplied this one example into many more examples.
warns about synthesizing data by introducing distortions
Note:
1. 合成的数据可能在测试集中可见,否则useless.the working things begin introduced are actually kind of reasonable,could be an image that we could actually see in a test set.
2. just add some Gaussian random noise to each pixel is just a totally meaningless noise.unless you're expecting to see these sorts of pixel wise noise in your test set.
Note:before creating artificial training examples,make sure that you really have a low biased classifier, and having a lot more training data will be of help.
总结:
if you are facing a machine learning problem, it is often worth doing two things:
One just a sanity(头脑清楚) check,with learning curves, that having more data would help.
And second, assuming that that's the case,ask: what would it take to get ten times as much creative data,but sometimes, you may be surprised by how easy that turns out to be, maybe a few days, a few weeks at work, and that can be a great way to give your learning algorithm a huge boost in performance.
Ceiling Analysis:What Part of the Pipeline to Work on Next 上限分析-接下来工作重心应放在pipeline哪个部分
{Which of these boxes is most worth your efforts, trying to improve the performance of}
the idea of ceiling analysis: by going through this sort of analysis you're trying to figure out what is the upside potential, of improving each of these components or how much could you possibly gain if one of these components became absolutely perfect and just really places an upper bound on the performance of that system.
文字识别
Note:
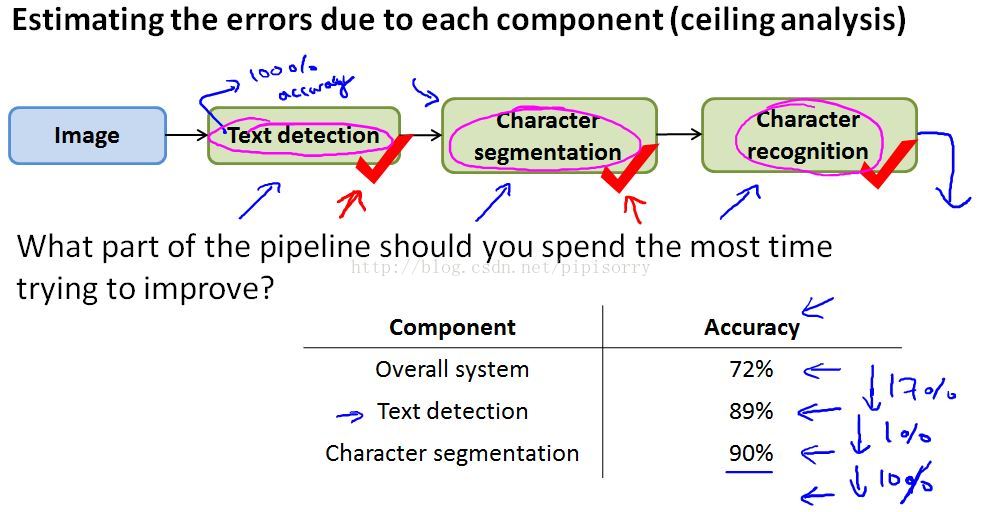
1. find that on our test set, the overall accuracy of the entire system was 72% on one of the metric you chose.(e.g. single world number evaluation metric)
2. if we get perfect text detection.Our performance went up from 72 to 89 percent, so that's' a 17 percent performance gain.So this means that you spend a lot of time improving text detection, we could potentially improve our system's performance by 17 percent.
3. Whereas in contrast, when gave it perfect character segmentation, performance went up only by one percent.maybe the upside potential is going to be pretty small.
4. What is the ceiling, or what's an upper bound on how much you can improve the performance of your system by working on one of these components?
5. Performing the ceiling analysis shown here requires that we have ground-truth labels for the text detection, character segmentation and the character recognition systems.
Another more complex ceiling analysis example人脸识别
face recognition pipeline
Note:
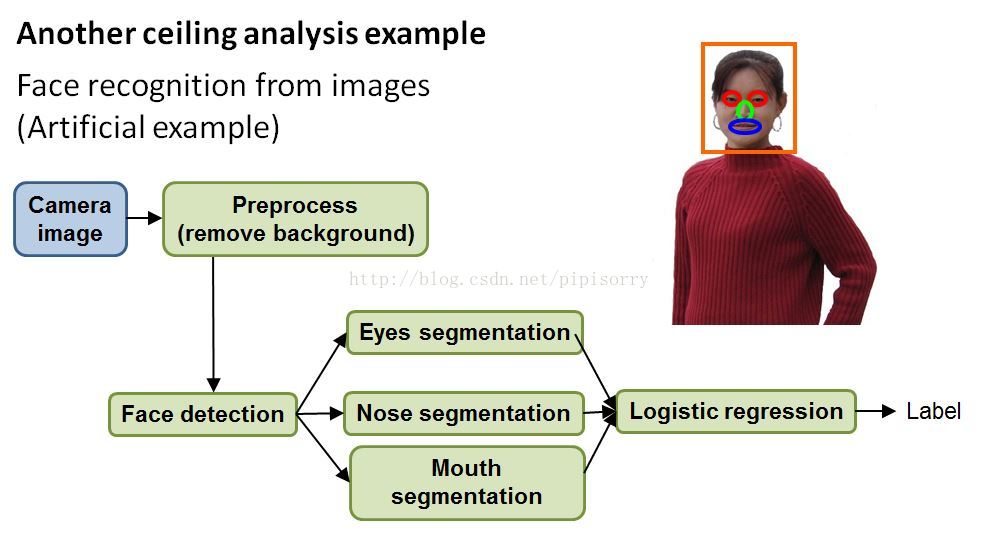
1. detected the face: run a sliding windows crossfire to draw a box around the person's face.
2. to recognize people the eyes is a highly useful cue.So, segment out the eyes,and then otherparts of the face of physical interest.
ceiling analysis for face recognition pipeline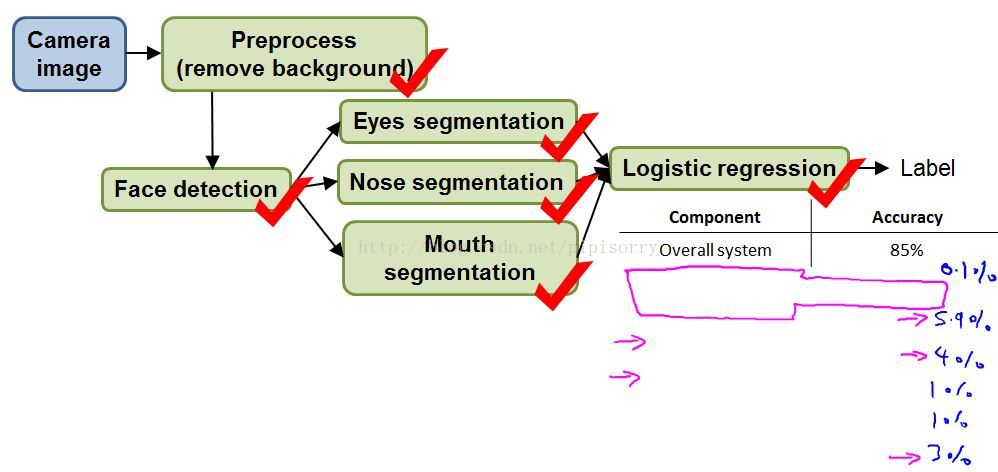
Note:
1. first go to my test set and manually give it a ground foreground, background,segmentations,use Photoshop or something, to just tell it where's the background, and just manually remove the background,and see how much the accuracy changes.
2. there was a research team spend a year and a half,working on better background removal.Actually they worked out really complicated algorithms, so ended up publishing one research paper.But after all that work, it just did not make a huge difference to the overall performance of the actual application.
Reviews
from:http://blog.csdn.net/pipisorry/article/details/44999703
ref:
[Reading Text in the Wild with Convolutional Neural Networks,Jaderberg论文、数据和代码 这篇期刊文章融合了之前两篇会议(ECCV14,NIPS14ws),定位和识别图片中的文本(叫text spotting)。 端到端系统: 检测Region + 识别CNN。
论文+代码(c++):面向自然场景文字提取的Object Proposals GitHub]
加州大学研究出新算法:让智能汽车更精准检测行人 原文:New algorithm improves speed and accuracy of pedestrian detection
Detecting cats in images with OpenCV
CNN目标检测: 文章分享的是Azoft R&D team在使用CNN解决目标检测问题的经验。包括 1. 车牌关键点检测(回归网络)2.(尺寸比较固定的)交通标志的关键点检测 3. 交通标志检测(看起来像分割网络)。1和2的效果好,3看起来效果不好。文章给了比较具体的方法
药片图像识别竞赛 《Pill Image Recognition Challenge》
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









