






- 【代码】Pre-trained word vectors of 30+ languages
简介:
This project has two purposes. First of all, I'd like to share some of my experience in nlp tasks such as segmentation or word vectors. The other, which is more important, is that probably some people are searching for pre-trained word vector models for non-English languages. Alas! English has gained much more attention than any other languages has done. Check this to see how easily you can get a variety of pre-trained English word vectors without efforts. I think it's time to turn our eyes to a multi language version of this.
2.【博客 & 代码】RNNs in Tensorflow, a Practical Guide and Undocumented Features
简介:
In a previous tutorial series I went over some of the theory behind Recurrent Neural Networks (RNNs) and the implementation of a simple RNN from scratch. That’s a useful exercise, but in practice we use libraries like Tensorflow with high-level primitives for dealing with RNNs.
With that using an RNN should be as easy as calling a function, right? Unfortunately that’s not quite the case. In this post I want to go over some of the best practices for working with RNNs in Tensorflow, especially the functionality that isn’t well documented on the official site.
3.【书】A Course in Machine Learning
简介:
Machine learning is the study of algorithms that learn from data and experience. It is applied in a vast variety of application areas, from medicine to advertising, from military to pedestrian. Any area in which you need to make sense of data is a potential consumer of machine learning.
CIML is a set of introductory materials that covers most major aspects of modern machine learning (supervised learning, unsupervised learning, large margin methods, probabilistic modeling, learning theory, etc.). It's focus is on broad applications with a rigorous backbone. A subset can be used for an undergraduate course; a graduate course could probably cover the entire material and then some.
原文链接:http://ciml.info/#chapters
4.【论文 & 代码】Phased LSTM: Accelerating Recurrent Network Training for Long or Event-based Sequences
简介:
Recurrent Neural Networks (RNNs) have become the state-of-the-art choice for extracting patterns from temporal sequences. However, current RNN models are ill-suited to process irregularly sampled data triggered by events generated in continuous time by sensors or other neurons. Such data can occur, for example, when the input comes from novel event-driven artificial sensors that generate sparse, asynchronous streams of events or from multiple conventional sensors with different update intervals. In this work, we introduce the Phased LSTM model, which extends the LSTM unit by adding a new time gate. This gate is controlled by a parametrized oscillation with a frequency range that produces updates of the memory cell only during a small percentage of the cycle. Even with the sparse updates imposed by the oscillation, the Phased LSTM network achieves faster convergence than regular LSTMs on tasks which require learning of long sequences. The model naturally integrates inputs from sensors of arbitrary sampling rates, thereby opening new areas of investigation for processing asynchronous sensory events that carry timing information. It also greatly improves the performance of LSTMs in standard RNN applications, and does so with an order-of-magnitude fewer computes at runtime.
原文链接:https://arxiv.org/pdf/1610.09513v1.pdf
代码链接:https://github.com/Enny1991/PLSTM
5.【论文 & 代码】WaveNet: A Generative Model for Raw Audio
简介:
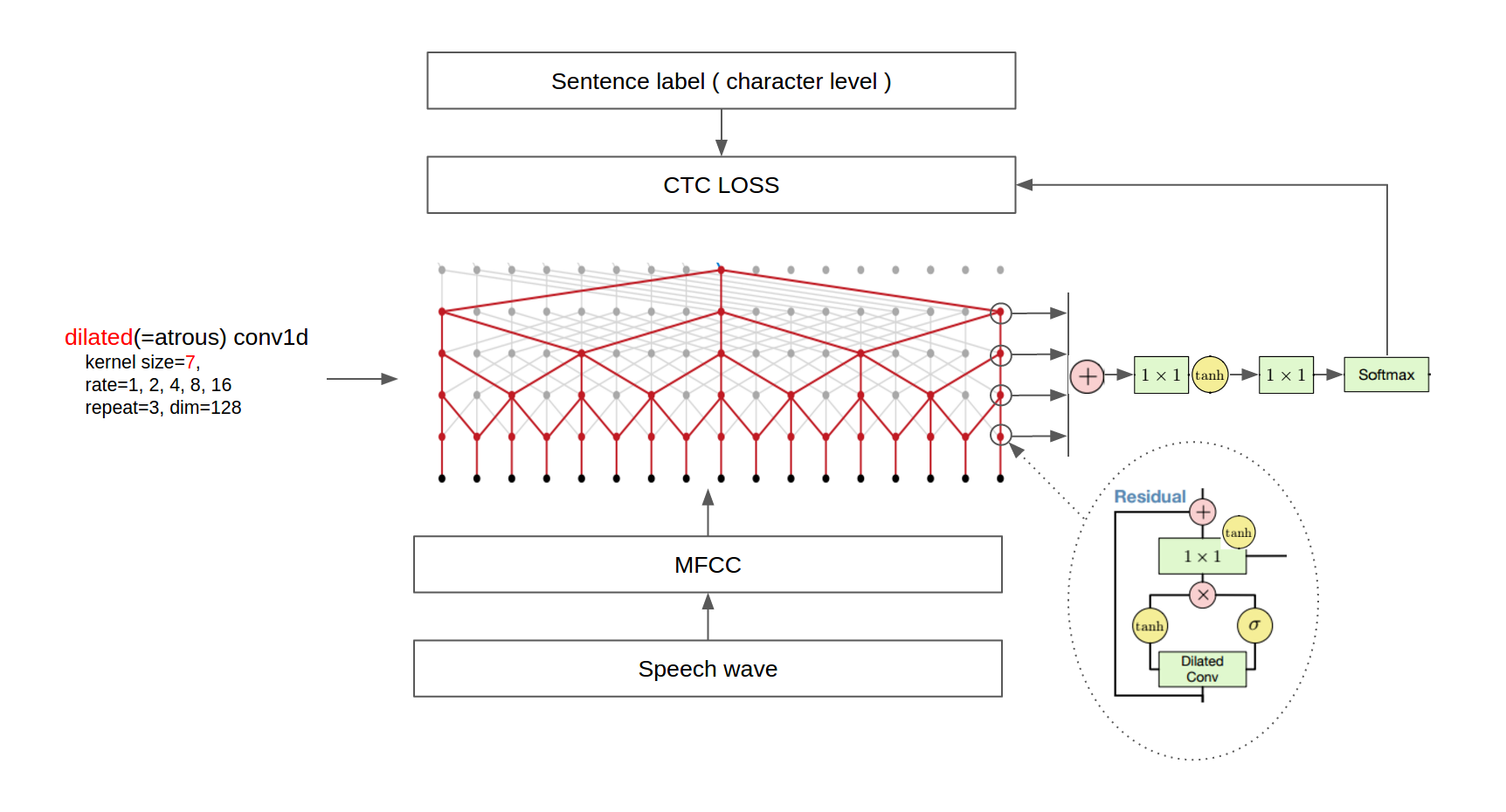
This paper introduces WaveNet, a deep neural network for generating raw audio waveforms. The model is fully probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones; nonetheless we show that it can be efficiently trained on data with tens of thousands of samples per second of audio. When applied to text-to-speech, it yields state-ofthe-art performance, with human listeners rating it as significantly more natural sounding than the best parametric and concatenative systems for both English and Mandarin. A single WaveNet can capture the characteristics of many different speakers with equal fidelity, and can switch between them by conditioning on the speaker identity. When trained to model music, we find that it generates novel and often highly realistic musical fragments. We also show that it can be employed as a discriminative model, returning promising results for phoneme recognition.
原文链接:https://arxiv.org/pdf/1609.03499v2.pdf
代码链接:https://github.com/buriburisuri/speech-to-text-wavenet
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









