







 本文详细介绍了三元语言模型的基础定义,通过最大似然估计来估计模型参数,并讨论了困惑度作为评估语言模型好坏的指标。此外,还分析了三元语言模型的优缺点,指出高阶n-gram对上下文敏感但易受数据稀疏性影响,而低阶n-gram则具有更好的鲁棒性。
本文详细介绍了三元语言模型的基础定义,通过最大似然估计来估计模型参数,并讨论了困惑度作为评估语言模型好坏的指标。此外,还分析了三元语言模型的优缺点,指出高阶n-gram对上下文敏感但易受数据稀疏性影响,而低阶n-gram则具有更好的鲁棒性。
该系列将描述一些自然语言处理方面的技术,完整目录请点击这里。
有很多种定义语言模型的方式,在这里我们将重点介绍一种特别重要的方式,即三元语言模型(Trigram language model)。这将是根据上一节中关于马尔科夫模型的最直接的一个应用。在这一部分中,我们将给出三元语言模型的最基本定义,并且讨论三元模型的最大似然参数估计,并且讨论了三元模型的优势和劣势。
1.1 基础定义
在马尔科夫模型中,我们将每个句子构建成 n 个随机变量的序列 X1, X2,...,Xn。其中,长度 n 是可变的。并且,我们定义 Xn = STOP。在二阶马尔科夫模型下,任何序列 x1, x2, ..., xn 的概率可以被表示为:
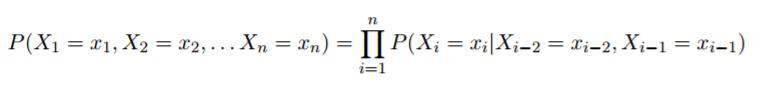
其中,正如我们之前假设的 x(0) = x(-1)=*。
我们假设对于任何的 i,和任何的 x(i-2),x(i-1),x(i)。
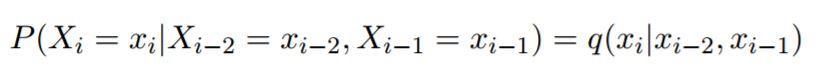
其中,q(w | u,v) 是任何参数 (u, v, w) 的一个参数模型。接下来,我们很快就会学习到如何从语料库中学习中模型 q(w | u,v) 的参数估计,我们模型采用的具体形式是:
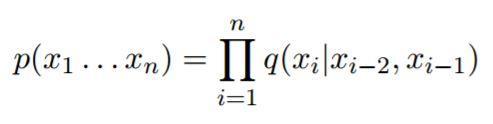
该等式对于任何的序列 x1, x2, ..., xn 对成立。
那么,接下来我们就可以推出如下定义:
定义 2(Trigram Language Model):一个三元语言模型包括一个有限集合 V,和一个参数 q(w | u, v) 。对于任何的三元 u, v, w,其中 w ∈ V ∪ {STOP}, 和 u, v ∈ V ∪ {*}。q(w | u,v) 的值可以理解为,在看到二元组 (u, v) 之后,看到单词 w 的概率是多少。对于任何的序列 x1, x2, ..., xn,其中 xi ∈ V for i = 1 . . .(n − 1),并且 xn = STOP。那么,根据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









