






一、基本概念
索引是一种与表相关的数据结构,用于加速数据的存取。在适合的场景对表的某些字段建立索引,可以很大程度的减少查询时的硬盘I/O。
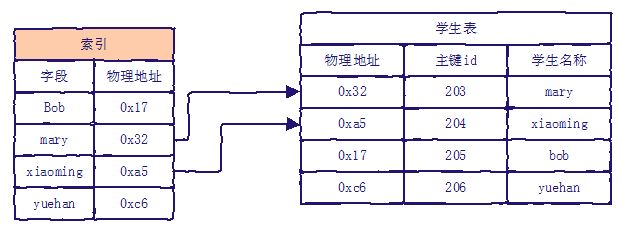
如果把表看作一本书,索引就相当于一本书的目录。没有目录的情况下,要查找指定内容需要翻阅整个书本。
- 索引是数据存储的一种机制,机制里边可以简单理解有索引字段、字段对应记录的物理地址。
- 索引字段按照一定的规律、规则组织在一起(数据结构与算法),可以加快信息的查找。
- 信息在索引内部被查找出来后,直接对应记录的"物理地址",根据物理地址就可以快速定位需要的记录信息。

二、创建索引
数据表的全部字段都可以创建索引,但具体得根据实际情况变更。
索引类型:
① 主键索引:primary key [名称](字段)
② 唯一索引:unique key [名称] (字段)
③ 普通索引:key [名称](字段) 或者 index [名称](字段)
④ 全文索引:fulltext key [名称] (字段)
⑤ 复合索引:多个字段组成索引
索引名称可以不设置,默认与当前索引字段名称一致。
mysql5.6.4之前只有Myisam支持全文索引,之后 Myisam和Innodb都支持全文索引。
索引创建:
a)创建数据表同时设置索引
CREATE TABLE `student`(
`id` int(11) not null auto_increment comment '逻辑主键',
`name` varchar(32) not null comment '名字',
`height` decimal(6,2) not null default '0.00' comment '身高',
`introduce` text comment '个人简介',
primary key (`id`), --主键索引
unique key `name`(`name`), --唯一索引
key `height`(`height`), --普通索引
fulltext key `introduce`(`introduce`) --全文索引
)ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='学生表';b) 给存在的数据表增加索引
CREATE TABLE `student`(
`id` int(11) not null comment '逻辑主键',
`name` varchar(32) not null comment '名字',
`height` decimal(6,2) not null default '0.00' comment '身高',
`introduce` text comment '个人简介',
)ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='学生表';
alter table `student` add primary key (`id`);
alter table `student` add unique key `name`(`name`);
alter table `student` add key `height`(`height`);
-- alter table `student` add index `height`(`height`);
alter table `student` add fulltext key `introduce`(`introduce`);
alter table `student` modify id int not null auto_increment commont '主键';c)设置复合索引
--表创建好之后
alter table `student` add key `nh`(`name`,`height`);
--建表时
key `bh`(`name`,`height`)三、删除索引
删除主键索引,必须先去除auto_inrement属性。
alter table 表名 modify 主键字段名 字段属性; --去掉auto_increment
alter table 表名 drop primary key;
alter table 表名 drop key 索引名;四、索引结构
主要学习下MyISAM和InnoDB引擎的索引的数据结构。
MySQL的数据结构都是B+Tree树结构。
1.MyISAM索引结构
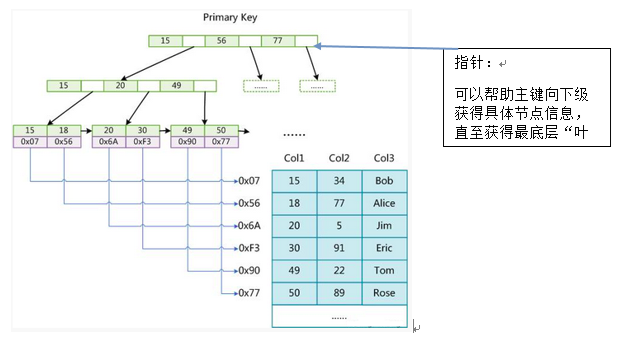
图中的Myisam索引结构称为"非聚合型"。
主键内容在该索引里边通过Mysql底层算法开始被查询、获得,并借助"指针"向下级寻找,直到找到对应的叶子节点,叶子节点里边有该关键字对应的记录的物理地址,从而获得对应的记录信息。
运行原理:快速定位主键id值,获得对应记录物理地址,获得记录信息。
- 每个主键id值都是一个节点,节点本身有指针
- 叶子节点与记录的物理地址直接联系
- 节点从上到下的层次数是索引结构的高度
- 每层节点的数目称为结构的宽度
- 结构的宽度、高度的数目由mysql底层算法计算获得(过高、过宽都不利于数据的快速获取)
Myisam其他索引结构与主键索引结构一致。
因为该索引结构的特性,所以Myisam引擎的数据文件与索引文件是分开存储的。

2.InnoDB索引结构
Innodb聚合型索引结构:
"索引"和"数据"是合并在一个后缀为[.ibd]文件里边的。
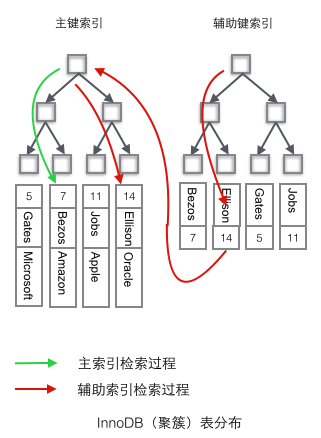
InnoDB主键索引结构:
① 通过索引结构快速定位主键id值对应的叶子节点
② 该叶子节点里边直接与整条记录信息进行对应(而在Myisam里边,叶子节点与物理地址对应)
InnoDB唯一、普通索引结构:
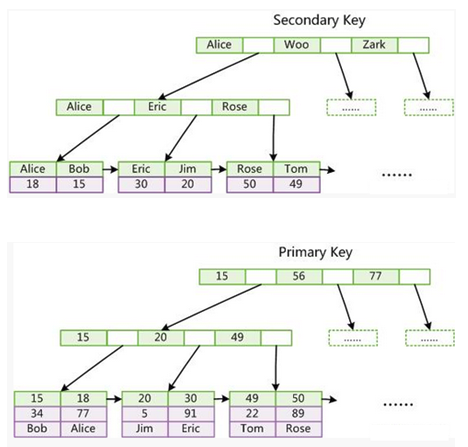
① 通过索引结构内部的算法快速定位该名字对应的叶子节点
② 叶子节点里边对应的是关键字的记录主键id值
③ 通过记录主键id值走主键索引即可
普通索引关键字----->记录的主键id值------>记录的整条信息
五、explain
一条sql语句在没有执行之前,先把需要的资源都计划好,例如cpu、内存等资源的分配预计,该行为就称为执行计划。
explain select语句
一般来说,
① 使用到索引,耗费资源少,查询速度快
② 没有使用到索引,耗费资源多,查询速度慢
explain各列的含义:
| id | SELECT识别符。这是SELECT的查询序列号 |
| select_type | SELECT类型,可以为以下任何一种:
|
| table | 输出的行所引用的表 |
| type | 联接类型。下面给出各种联接类型,按照从最佳类型到最坏类型进行排序:
|
| possible_keys | 指出MySQL能使用哪个索引在该表中找到行 |
| key | 显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。 |
| key_len | 显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。 |
| ref | 显示使用哪个列或常数与key一起从表中选择行。 |
| rows | 显示MySQL认为它执行查询时必须检查的行数。多行之间的数据相乘可以估算要处理的行数。 |
| filtered | 显示了通过条件过滤出的行数的百分比估计值。 |
| Extra | 该列包含MySQL解决查询的详细信息
|
六、使用场合
有的字段重复内容很多(例如性别字段),则不要设置索引,因为它不会起作用。
① where条件后边的字段都可以设置索引
② 排序字段适合做索引
③ 索引覆盖
数据查询时查询的字段就是索引的内容,这样索引本身就支持数据的提供。数据查询只通过索引内容就获得需要的信息,就称为索引覆盖。
-- 假设ename和deptno已经是索引,就形成索引覆盖
explain select ename,deptno from emp limit 10,10;我们需要的信息(ename/deptno),单纯从索引内部就提供好了,不会再去记录中获取其他不相关的信息,因此索引本身就满足我们对数据的获取,这样的索引和查询结合起来运行速度是最快的,称为是"黄金索引"。
④ 连接查询
select 字段列表 from 表1 join 表2 on 表1.字段=表2.字段(表1.字段 也称为"外键字段")。
外键字段也适合做索引。
七、索引原则
① 字段独立原则
-- 字段独立,可以使用索引
select * from emp where empno=1345629;
-- 字段不独立(不能使用索引)
select * from emp where empno+2=1345629;② 最左前缀原则
-- 能用索引
select * from emp where ename like "内容%";
-- 不能用索引
select * from emp where ename like "%内容%";
-- 能用索引
select * from emp where ename like "内容__";
-- 不能用索引
select * from emp where ename like "_内容__";③ 复合索引
假设ename和deptno建立了复合索引。
复合索引的第一个字段,单独作为条件可以使用到该索引。
explain select * from emp where ename like 'abc%';复合索引的第二个字段,单独作为条件不可以使用到该索引。
explain select * from emp where deptno = 123;复合索引的两个字段都作为条件,则可以使用该索引。
explain select * from emp where ename like 'abc%' and deptno = 123;④ or原则
两边都有索引,则会全部都分别使用。
一个有索引,另一个没有索引(与顺序无关),导致结果一个索引都没有被使用。
八、设计依据
① 被频繁使用的字段设置索引
字段被频繁用在where和order等条件里边。数据表创建完毕,要预估哪些字段被经常使用,就给其创建索引。
② 执行时间长的sql语句考虑设计索引
可以利用"慢查询日志"收集这样的sql语句并优化设计索引
③ 逻辑非常重要的sql语句考虑设计索引
例如商城系统里边,会员给自己账户充值就比较重要。还有会员下订单购物,进行付款的时候也比较重要。
④ 字段内容足够花样化,可以考虑设计索引
反面教材,性别不能设计索引(内容的取值非常少)。
九、前缀索引
索引是给sql语句做优化,前缀索引,是给索引做优化。
如果一个字段的内容的前边的n位信息已经足够可以标识当前的字段内容,就可以把字段的前n位获得出来并创建索引,通过字段内容前n位创建的索引就称为前缀索引。
例如:abc dec bfg haha
前缀索引占据的物理空间要比较小,这样的索引运行速度快、效率高,对mysql整体性能提升有很大帮助。
alter table 表名 add key (字段(位数))
获得字段的前n位:substring(字段,开始位置,长度n),该系统函数可以获取。
十、in条件索引
假设empno做略索引,in条件也可以使用索引。
select * from emp where empno in (1,2,3);十一、全文索引
其他索引是把字段的内容作为一个整体进行索引设计。全文索引,类似我们有一篇作文,把作文中的一些关键字给获取出来当成是索引内容。
具体理解就是做like模糊查询,类似baidu搜索一些关键字效果。
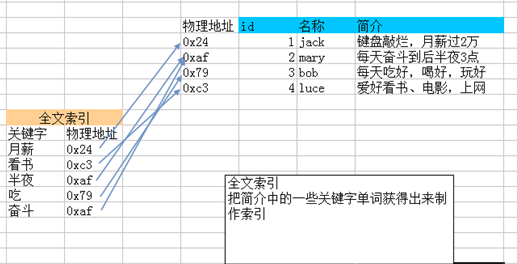
- 字段类型必须为varchar/char/text类型
- mysql 5.6.4之前只有Myisam支持,5.6.4之后则Myisam和innodb都支持。
- mysql中的全文索引目前只支持英文(不支持中文),如果需要支持中文可以使用sphinx
- 现实生产中mysql的全文索引不经常使用,sphinx常使用
-- 假设文章表有个body字段,我们建立全文索引
alter table articles add fulltext index `index_body` (body);
-- 使用
select * from articles where match(全文索引字段) against(内容);复合全文索引:
alter table articles add fulltext index `index_full`(`title`,`body`);
select * from articles where match(title,body) against('haha');
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









