






1 eclipse中hadoop环境部署概览
eclipse中部署hadoop包括两大部分:hdfs环境部署和mapreduce任务执行环境部署。一般hdfs环境部署比较简单,部署后就 可以在eclipse中像操作windows目录一样操作hdfs文件。而mapreduce任务执行环境的部署就比较复杂一点,不同版本对环境的要求度 高低不同就导致部署的复杂度大相径庭。例如hadoop1包括以前的版本部署就比较简单,可在windows和Linux执行部署运行,而hadoop2 及以上版本对环境要求就比较严格,一般只能在Linux中部署,如果需要在windows中部署需要使用cygwin等软件模拟Linux环境,该篇介绍在Linux环境中部署hadoop环境。该篇假设hadoop2.3.0集群已经部署完成,集群访问权限为hadoop用户。这种在eclipse上操作hdfs和提交mapreduce任务的方式为hadoop客户端操作,故无须在该机器上配置hadoop集群文件,也无须在该机器上启动hadoop相关进程。
2 部署环境机器相关配置
Centos6,32位
Hadoop2.3.0
Eclipse4.3.2_jee Linux版
JDK1.7 Linux版
3 eclipse中hdfs及mapreduce环境部署
3.1 Linux中eclipse安装
3.1.1 在Linux中选择一个eclipse安装目录如/home目录,将eclipse压缩包eclipse-standard-kepler-SR2-linux-gtk.tar.gz在该目录下解压即可,解压命令如下:
tar -zxvf eclipse-standard-kepler-SR2-linux-gtk.tar.gz
3.1.2 解压后的eclipse目录需要赋予hadoop用户权限chown -R hadoop:hadoop /home/eclipse,解压后eclipse目录如下图所示:

3.1.3 将自己打包或者下载的hadoop和eclipse直接的插件导入eclipse的 plugins目录(复制进去即可),该篇使用直接下载的插件hadoop-eclipse-plugin-2.2.0.jar,然后启动eclipse。
3.2 eclipse环境部署
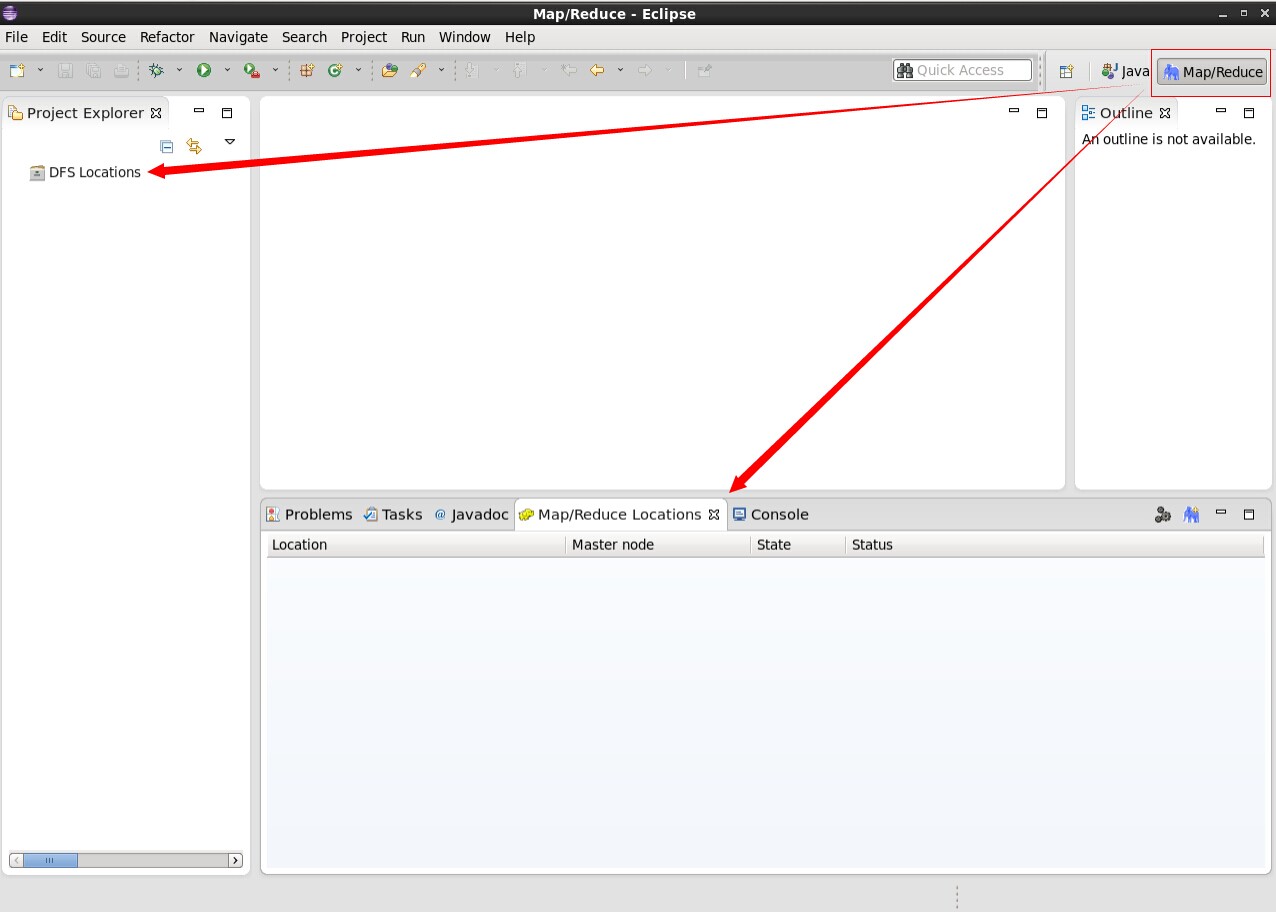
3.2.1 打开eclipse后切换到mapreduce界面会出现mapreduce插件图标,一个是DFS显示的位置,一个是mapreduce显示的位置,具体如下图所示:
3.2.2 在MapReduce Locations出处点击右键新建mapreduce配置环境,具体图示如下:

3.2.3 进入mapreduce配置环境,具体如下图所示。其中,Location name可任意填写,Mapreduce Master中Host为resourcemanager机器ip,Port为resourcemanager接受任务的端口号,即yarn-site.xml文件中yarn.resourcemanager.scheduler.address配置项中端口号。DFS Master中的Host为namenode机器ip,Port为core-site.xml文件中fs.defaultFS配置项中端口号。

3.2.4 上一步骤配置完成后,我们看到的界面如下图所示。左侧栏中即为hdfs目录,在每个目录上课点击右键操作。

4 eclipse中直接提交mapreduce任务(此处以wordcount为例,同时注意hadoop集群防火墙需对该机器开放相应端口)
如果我们将hadoop自带的wordcount在eclipse中执行是不可以的,调整后具体操作如下。
4.1 首先新建Map/Reduce工程(无须手动导入hadoop jar包),或者新建java工程(需要手动导入hadoop相应jar包)。
4.1.1 新建Map/Reduce工程(无须手动导入hadoop jar包),具体图示如下图所示:

4.1.1.1 点击next输入hadoop工程名即可,具体如下图所示:

4.1.1.2 新建的hadoop工程如下图所示:

4.1.2 新建java工程(需要手动导入hadoop相应jar包),具体如下图所示:

4.1.2.1 新建java工程完成后,下面添加hadoop相应jar包,hadoop2.3.0相应jar包在/hadoop-2.3.0/share/hadoop目录中。

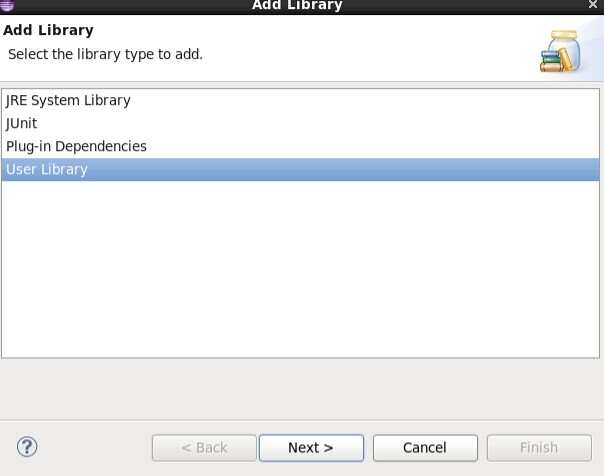
4.1.2.2 进入Libraries,点击Add Library添加hadoop相应jar包。

4.1.2.3 新建hadoop相应library成功后添加hadoop相应jar包到该library下面即可。

4.1.2.4 需要添加的hadoop相应jar包有:
/hadoop-2.3.0/share/hadoop/common下所有jar包,及里面的lib目录下所有jar包
/hadoop-2.3.0/share/hadoop/hdfs下所有jar包,不包括里面lib下的jar包
/hadoop-2.3.0/share/hadoop/mapreduce下所有jar包,不包括里面lib下的jar包
/hadoop-2.3.0/share/hadoop/yarn下所有jar包,不包括里面lib下的jar包
4.2 eclipse直接提交mapreduce任务所需环境配置代码如下所示:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URL;
import java.net.URLClassLoader;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.jar.JarEntry;
import java.util.jar.JarOutputStream;
import java.util.jar.Manifest;
public class EJob {
// To declare global field
private static List<URL> classPath = new ArrayList<URL>();
// To declare method
public static File createTempJar(String root) throws IOException {
if (!new File(root).exists()) {
return null;
}
Manifest manifest = new Manifest();
manifest.getMainAttributes().putValue("Manifest-Version", "1.0");
final File jarFile = File.createTempFile("EJob-", ".jar", new File(System.getProperty("java.io.tmpdir")));
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
jarFile.delete();
}
});
JarOutputStream out = new JarOutputStream(new FileOutputStream(jarFile), manifest);
createTempJarInner(out, new File(root), "");
out.flush();
out.close();
return jarFile;
}
private static void createTempJarInner(JarOutputStream out, File f,
String base) throws IOException {
if (f.isDirectory()) {
File[] fl = f.listFiles();
if (base.length() > 0) {
base = base + "/";
}
for (int i = 0; i < fl.length; i++) {
createTempJarInner(out, fl[i], base + fl[i].getName());
}
} else {
out.putNextEntry(new JarEntry(base));
FileInputStream in = new FileInputStream(f);
byte[] buffer = new byte[1024];
int n = in.read(buffer);
while (n != -1) {
out.write(buffer, 0, n);
n = in.read(buffer);
}
in.close();
}
}
public static ClassLoader getClassLoader() {
ClassLoader parent = Thread.currentThread().getContextClassLoader();
if (parent == null) {
parent = EJob.class.getClassLoader();
}
if (parent == null) {
parent = ClassLoader.getSystemClassLoader();
}
return new URLClassLoader(classPath.toArray(new URL[0]), parent);
}
public static void addClasspath(String component) {
if ((component != null) && (component.length() > 0)) {
try {
File f = new File(component);
if (f.exists()) {
URL key = f.getCanonicalFile().toURL();
if (!classPath.contains(key)) {
classPath.add(key);
}
}
} catch (IOException e) {
}
}
}
}4.3 修改后的wordcount代码如下
import java.io.File;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.permission.FsPermission;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/*
* 用户自定义map函数,对以<key, value>为输入的结果文件进行处理
* Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法。
* 通过在map方法中添加两句把key值和value值输出到控制台的代码
* ,可以发现map方法中value值存储的是文本文件中的一行(以回车符为行结束标记),而key值为该行的首字母相对于文本文件的首地址的偏移量。
* 然后StringTokenizer类将每一行拆分成为一个个的单词
* ,并将<word,1>作为map方法的结果输出,其余的工作都交有MapReduce框架处理。 每行数据调用一次 Tokenizer:单词分词器
*/
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/*
* 重写Mapper类中的map方法
*/
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
//System.out.println(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());// 获取下个字段的值并写入文件
context.write(word, one);
}
}
}
/*
* 用户自定义reduce函数,如果有多个热度测,则每个reduce处理自己对应的map结果数据
* Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。
* Map过程输出<key,values>中key为单个单词,而values是对应单词的计数值所组成的列表,Map的输出就是Reduce的输入,
* 所以reduce方法只要遍历values并求和,即可得到某个单词的总次数。
*/
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
/**
* 环境变量配置
*/
File jarFile = EJob.createTempJar("bin");
ClassLoader classLoader = EJob.getClassLoader();
Thread.currentThread().setContextClassLoader(classLoader);
/**
* 连接hadoop集群配置
*/
Configuration conf = new Configuration(true);
conf.set("fs.default.name", "hdfs://192.168.1.111:9000");
conf.set("hadoop.job.user", "hadoop");
conf.set("mapreduce.framework.name", "yarn");
conf.set("mapreduce.jobtracker.address", "192.168.1.100:9001");
conf.set("yarn.resourcemanager.hostname", "192.168.1.100");
conf.set("yarn.resourcemanager.admin.address", "192.168.1.100:8033");
conf.set("yarn.resourcemanager.address", "192.168.1.100:8032");
conf.set("yarn.resourcemanager.resource-tracker.address", "192.168.1.100:8036");
conf.set("yarn.resourcemanager.scheduler.address", "192.168.1.100:8030");
String[] otherArgs = new String[2];
otherArgs[0] = "hdfs://192.168.1.111:9000/test_in";//计算原文件目录,需提前在里面存入文件
String time = new SimpleDateFormat("yyyyMMddHHmmss").format(new Date());
otherArgs[1] = "hdfs://192.168.1.111:9000/test_out/" + time;//计算后的计算结果存储目录,每次程序执行的结果目录不能相同,所以添加时间标签
/*
* setJobName()方法命名这个Job。对Job进行合理的命名有助于更快地找到Job,
* 以便在JobTracker和Tasktracker的页面中对其进行监视
*/
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
((JobConf) job.getConfiguration()).setJar(jarFile.toString());//环境变量调用,添加此句则可在eclipse中直接提交mapreduce任务,如果将该java文件打成jar包,需要将该句注释掉,否则在执行时反而找不到环境变量
// job.setMaxMapAttempts(100);//设置最大试图产生底map数量,该命令不一定会设置该任务运行过车中的map数量
// job.setNumReduceTasks(5);//设置reduce数量,即最后生成文件的数量
/*
* Job处理的Map(拆分)、Combiner(中间结果合并)以及Reduce(合并)的相关处理类。
* 这里用Reduce类来进行Map产生的中间结果合并,避免给网络数据传输产生压力。
*/
job.setMapperClass(TokenizerMapper.class);// 执行用户自定义map函数
job.setCombinerClass(IntSumReducer.class);// 对用户自定义map函数的数据处理结果进行合并,可以减少带宽消耗
job.setReducerClass(IntSumReducer.class);// 执行用户自定义reduce函数
/*
* 接着设置Job输出结果<key,value>的中key和value数据类型,因为结果是<单词,个数>,
* 所以key设置为"Text"类型,相当于Java中String类型
* 。Value设置为"IntWritable",相当于Java中的int类型。
*/
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
/*
* 加载输入文件夹或文件路径,即输入数据的路径
* 将输入的文件数据分割成一个个的split,并将这些split分拆成<key,value>对作为后面用户自定义map函数的输入
* 其中,每个split文件的大小尽量小于hdfs的文件块大小
* (默认64M),否则该split会从其它机器获取超过hdfs块大小的剩余部分数据,这样就会产生网络带宽造成计算速度影响
* 默认使用TextInputFormat类型,即输入数据形式为文本类型数据文件
*/
System.out.println("Job start!");
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
/*
* 设置输出文件路径 默认使用TextOutputFormat类型,即输出数据形式为文本类型文件,字段间默认以制表符隔开
*/
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
/*
* 开始运行上面的设置和算法
*/
if (job.waitForCompletion(true)) {
System.out.println("ok!");
} else {
System.out.println("error!");
System.exit(0);
}
}
}4.4 在eclipse中代码区点击右键,点击里面的run on hadoop即可运行该程序。
原创文章欢迎转载,转载请注明出处
作者推荐文章:















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









