






组件介绍:
- carbon:Carbon实际上是一系列守护进程,组成一个Graphite安装的存储后端。这些守护进程用一个名为Twisted的事件驱动网络引擎监听时间序列数据。Twisted框架让Carbon守护进程能够以很低的开销处理大量的客户端和流量。
- whisper:whisper是一个用于存储时间序列数据的数据库,之后应用程序可以用create,update和fetch操作获取并操作这些数据。
- graphite-web:用于从whisper查询数据,并展示在图表上,并且维护了一个数据库SQLite用于存储图表信息。重要的是,其提供了一系列接口用于查询数据,这样的话很容易和grafana集成(grafana调用graphite-web的接口来进行查询)
软件版本:(不要按照官网进行安装,有很多坑,尤其是版本的坑)
- Red Hat 4.4.7-11(cat /proc/version)(mac上不好装)
- Python 2.6.6(python -V)
- carbon-0.9.14.tar.gz(下载地址:https://pypi.python.org/pypi/carbon/)
- whisper-0.9.14.tar.gz(下载地址:https://pypi.python.org/pypi/whisper)
- graphite-web-0.9.14.zip(下载地址:https://pypi.python.org/pypi/graphite-web/)
- 0.9.14居然是zip包,与前两者风格不统一
- statsd: 0.8.0 (下载地址:https://github.com/etsy/statsd.git)
- grafana-3.1.1
一、安装
1、安装基本依赖
-
yum install -y epel-release
-
yum install -y gcc Django14 cairo python-pip python-django-tagging pycairo python-gunicorn python-devel supervisor nodejs pytz bitmap-fonts-compat
-
pip install twisted==15.4.0
2、安装3个组件
- 下载上述的三个包
2.1、安装carbon
-
tar zxvf carbon-0.9.14.tar.gz
-
cd carbon-0.9.14
-
python setup.py install
2.2、安装whisper
-
tar zxvf whisper-0.9.14.tar.gz
-
cd whisper-0.9.14
-
python setup.py install
2.3、安装graphite-web
-
yum install unzip(可选)
-
unzip graphite-web-0.9.14.zip
-
cd graphite-web-0.9.14
-
python setup.py install
三、创建配置文件
- cd /opt/graphite/conf
- cp carbon.conf.example carbon.conf
- cp storage-aggregation.conf.example storage-aggregation.conf
- cp storage-schemas.conf.example storage-schemas.conf
四、初始化数据库
-
cd /opt/graphite/webapp/
-
chmod 755 graphite/*.py
-
chmod 755 graphite/*.pyc
-
graphite/manage.py syncdb(在此期间可以选择是否创建用户名、密码、邮箱)
五、启动carbon
- cd /opt/graphite/bin
-
./carbon-cache.py start
六、启动graphite-web
- cd /opt/graphite/webapp
- /usr/bin/gunicorn_django -b0.0.0.0:8000 -w2 graphite/settings.py
- 浏览器输入ip:8000
所有软件安装并启动成功!!!
七、测试
-
yum install nc
-
echo "1001.carbon.zjg.metrics1 10112 `date +%s`" | nc localhost 2003
- 查看/opt/graphite/storage/whisper下的数据以及/opt/graphite/storage/log/carbon-cache/carbon-cache-a下的日志
- 查看graphite-web
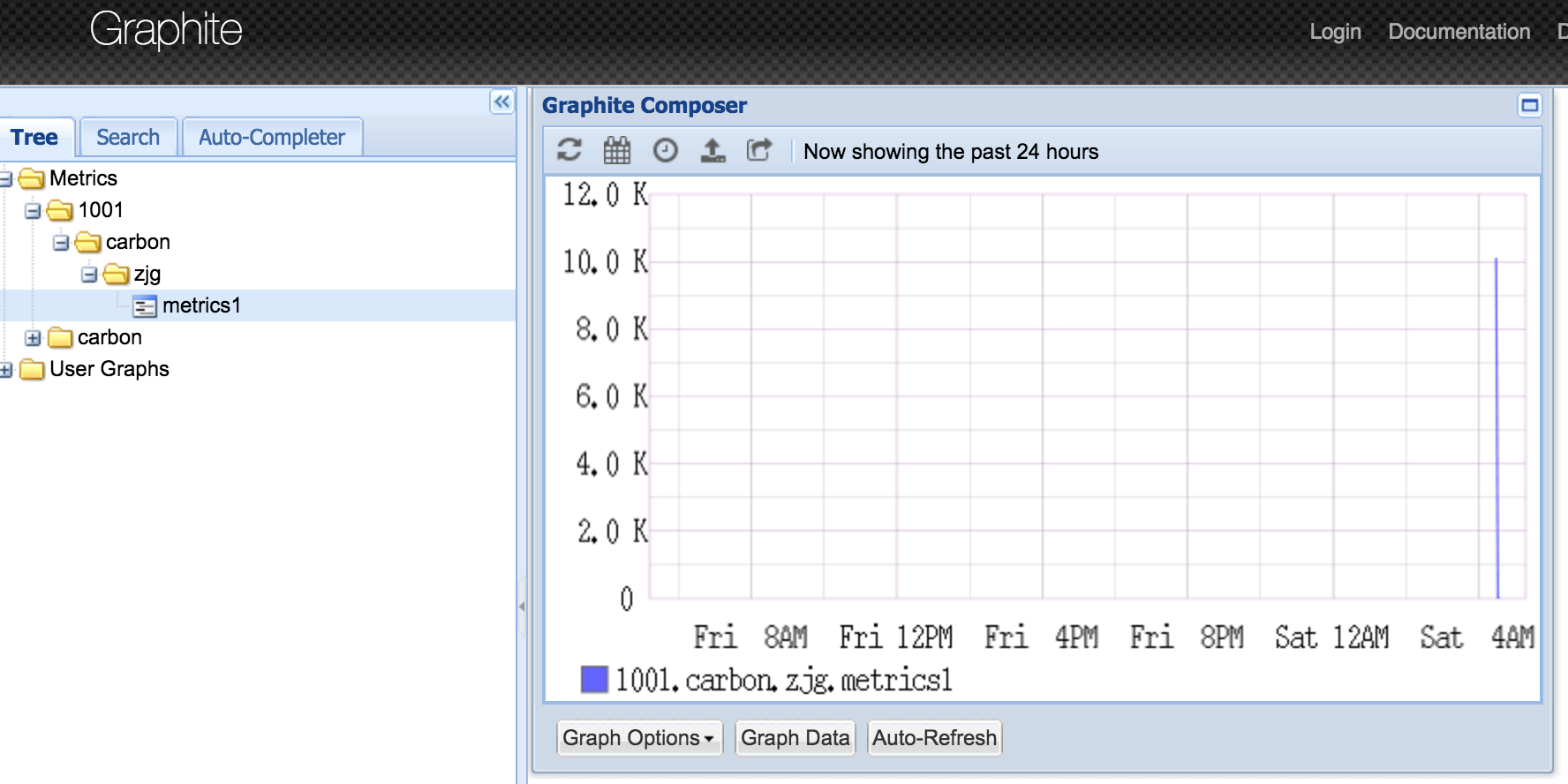
至此,graphite-web安装成功!!!
八、部分API使用
在执行如上测试之后,会生成一个metrics.wsp文件,可以通过如下命令来查看该wsp文件的元数据信息。
- whisper-info.py /opt/graphite/storage/whisper/1001/carbon/zjg/metrics1.wsp


1 maxRetention: 86400
2 xFilesFactor: 0.5
3 aggregationMethod: average
4 fileSize: 17308
5
6 Archive 0
7 retention: 86400
8 secondsPerPoint: 60
9 points: 1440
10 size: 17280
11 offset: 28- whisper-dump.py /opt/graphite/storage/whisper/1001/carbon/zjg/metrics1.wsp(更加详细)
1 Meta data:
2 aggregation method: average
3 max retention: 86400
4 xFilesFactor: 0.5
5
6 Archive 0 info:
7 offset: 28
8 seconds per point: 60
9 points: 1440
10 retention: 86400
11 size: 17280
12
13 Archive 0 data:
14 0: 1475296140, 10112
15 1: 1475296200, 10
16 2: 0, 0
17 3: 0, 0
18 ...
19 1439: 0, 0再执行一遍,echo "1001.carbon.zjg.metrics1 101011 `date +%s`" | nc localhost 2003
会看到,除了第一个数据点有数据之外,还有 1353: 1475377320, 101010
九、whisper存储模式
1、存储模式
当Whisper文件被创建时,将拥有一个固定的文件尺寸,这个尺寸永远不会再改变。在Whisper文件中可能会包含多个用于不同分辨率的数据点的“存储区(bucket)”,这些存储区是在配置文件storage-schemas.conf中定义的,
例如:
- 存储器A:拥有10秒分辨率的数据点(即每10s发布一次metrics)
- 存储区B:拥有60秒分辨率的数据点
- 存储区C:拥有10分钟分辨率的数据点
每个存储区还拥有一个保留期(retention)属性用于标识该存储区中的数据点应该保留的时间长度。例如:
- 存储区A:分辨率为10秒,保留时间6小时的数据点
- 存储区B:分辨率为60秒,保留时间1天的数据点
- 存储区C:分辨率为10分钟,保留时间7天的数据点
根据上述两种信息,Whisper可以进行一些简单的数学计算,计算出在每个存储区中实际需要保存多少数据点。
- 存储区A:6小时 x 60分钟/小时 x 6数据点/分钟 = 2160点
- 存储区B:1天 x 24小时/天 x 60分钟/小时 x 1数据点/分钟 = 1440点
- 存储区C:7天 x 24小时/天 x 6数据点/小时 = 1008点
如果根据这个存储模式配置创建Whisper文件,该文件大小是56KB。如果在这个文件上执行whisper-dump.py脚本,会有如下输出。需要注意的是,一个archive对应一个存储区,每点秒数(seconds per point )和点数(points )属性则与我们之前的计算相匹配。
2、默认存储模式
包含carbon和default_1min_for_1day两个section。storage-schemas.conf:
1 # Schema definitions for Whisper files. Entries are scanned in order,
2 # and first match wins. This file is scanned for changes every 60 seconds.
3 #
4 # [name]
5 # pattern = regex
6 # retentions = timePerPoint:timeToStore, timePerPoint:timeToStore, ...
7
8 # Carbon's internal metrics. This entry should match what is specified in
9 # CARBON_METRIC_PREFIX and CARBON_METRIC_INTERVAL settings
10 [carbon]
11 pattern = ^carbon\.
12 retentions = 60:90d
13
14 [default_1min_for_1day]
15 pattern = .*
16 retentions = 60s:1d说明:
- 以carbon开头的(carbon内部的metrics,在实际使用中,根据需要可能会去掉该section,该section去掉后,这些内部metrics会被记录到default_1min_for_1day的section下去),每60s发布一次,存储90天。
- 在生产中,default_1min_for_1day下会存储一些并不重要的数据,设置为60s:1d就足够了。
- 剩下所有的metrics,每60s记录一次,保留1天,那么,默认条件下:
- seconds per point=60(每60s记录一个点)
- points=1*24*60*1=1440
- retention=1*24*60*60=86400s
- max retention=max(retentions)=86400s(几个存储区存储时间最长的)
注意:
- 匹配由上到下,上边的已经匹配了,就不会再去匹配下边的了
- storage-schemas.conf文件每隔60s会被扫描一次,所以修改了该文件不必重启服务器,60s后自动生效(老的文件不变--即使是再写入新的metrics,原因是"当Whisper文件被创建时,将拥有一个固定的文件尺寸,这个尺寸永远不会再改变",新的文件采用新的规则)。
3、修改存储模式
1 [default_1min_for_1day]
2 pattern = .*
3 retentions = 10s:6h,60s:1d,10m:7d说明:存储模式与1中一样
whisper-info查看
1 maxRetention: 604800
2 xFilesFactor: 0.5
3 aggregationMethod: average
4 fileSize: 55348
5
6 Archive 0
7 retention: 21600
8 secondsPerPoint: 10
9 points: 2160
10 size: 25920
11 offset: 52
12
13 Archive 1
14 retention: 86400
15 secondsPerPoint: 60
16 points: 1440
17 size: 17280
18 offset: 25972
19
20 Archive 2
21 retention: 604800
22 secondsPerPoint: 600
23 points: 1008
24 size: 12096
25 offset: 43252说明:每个Archive对应一个存储区。
十、聚合方式
1、聚合
当数据从一个较高精度的存储区移动到一个较低精度的存储区时,聚合开始发挥作用。让我们以前一个示例中的存储区A和存储区B为例:
- 存储区A:分辨率为10秒,保留时间6小时的数据点(较高精度)
- 存储区B:分辨率为60秒,保留时间1天的数据点(较低精度)
我们可能有一个每10秒钟发布一个数据点的应用程序。在存储区A中可以找到6小时之内发布的任何数据点。不过,如果我开始查询6小时之前发布的数据点,就可以在存储区B中找到它们。
注意:查询是从高精度到低精度去依次查找。
聚合方式:实际上,最开始carbon以每10秒一次的速度记录应用和业务指标项。这种10秒一次的数据会保存6小时。6小时后,这些数据将被聚合为1分钟数据并保存1天。最后,1天之后,这些数据将被聚合为10分钟数据并再保存7天。
2、数据点如何从高精度的存储区A移动到存储区B
2.1、获取聚合点数
用高精度值除以低精度值,以确定需要聚合的数据点的数量。
60秒(存储区B)/10秒(存储区A)= 6个数据点需要聚合
注:Whisper需要较高精度的值能够整除较低精度的值(也就是说,相除的结果必须是整数)。否则聚合的结果可能会不准确。
2.2、聚合函数选择
聚合数据时,Whisper从存储区A中读取6个10秒数据点,然后将函数应用于这些数据点上,得出一个将被存储在存储区B中的60秒数据点。有5个聚合函数选项:average,sum,max,min和last。聚合函数的选择取决于需要处理的数据点。例如,第95百分位的值可能应该用max函数聚合。另一方面,对于计数器来说,sum函数可能更合适。
2.3、xFilesFactor
在聚合数据点时,Whisper还处理了xFilesFactor的概念。xFilesFactor表示为了保证聚合准确,一个存储区必须包含的数据点比率。在我们之前的示例中,Whisper确定了它需要聚合6个10秒数据点。由于网络问题,应用重启等原因,可能只有4个数据点有数据而其他2个数据点是空值。
如果我们的Whisper文件的xFilesFactor是0.5,这意味着只有存在至少50%的数据点时,Whisper才会聚合数据。如果超过50%的数据点为空时,Whisper会创建一个空值聚合。在我们的例子中,即6个数据点中的4个——也就是66%。聚合函数会被应用在非空数据点上,创建聚合值。
你可以将xFilesFactor设置为0到1之间的任意值。值0表示即使只有一个有效数据点,就会执行聚合。值1则表示只有全部的数据点都有效,才会执行聚合。
3、默认聚合规则配置(storage-aggregation.conf)
1 # Aggregation methods for whisper files. Entries are scanned in order,
2 # and first match wins. This file is scanned for changes every 60 seconds
3 #
4 # [name]
5 # pattern = <regex>
6 # xFilesFactor = <float between 0 and 1>
7 # aggregationMethod = <average|sum|last|max|min>
8 #
9 # name: Arbitrary unique name for the rule
10 # pattern: Regex pattern to match against the metric name
11 # xFilesFactor: Ratio of valid data points required for aggregation to the next retention to occur
12 # aggregationMethod: function to apply to data points for aggregation
13 #
14 [min]
15 pattern = \.min$
16 xFilesFactor = 0.1
17 aggregationMethod = min
18
19 [max]
20 pattern = \.max$
21 xFilesFactor = 0.1
22 aggregationMethod = max
23
24 [sum]
25 pattern = \.count$
26 xFilesFactor = 0
27 aggregationMethod = sum
28
29 [default_average]
30 pattern = .*
31 xFilesFactor = 0.5
32 aggregationMethod = average说明:4个条目
- 以.min结尾的指标项
- 使用min聚合函数
- 至少有10%数据点才可以聚合
- 以.max结尾的指标项
- 使用max聚合函数
- 至少有10%数据点才可以聚合
- 以.count结尾的指标项
- 使用sum聚合函数
- 聚合的前提是至少要有一个数据点
- 其他指标项
- 使用average聚合函数
- 至少有50%数据点才可以聚合
注意:
- 匹配由上到下,上边的已经匹配了,就不会再去匹配下边的了
- storage-aggregation.conf文件每隔60s会被扫描一次,所以修改了该文件不必重启服务器,60s后自动生效(老的文件不变--即使是再写入新的metrics,原因是"当Whisper文件被创建时,将拥有一个固定的文件尺寸,这个尺寸永远不会再改变",新的文件采用新的规则)。
- 很重要的一点,storage-aggregation.conf中的pattern匹配的是metric的name。例如gc.ps_scavenge.count: 2353,测试一下,执行
echo "1002.carbon.zjg.metrics4.count 101014 `date +%s`" | nc localhost 2003(metric name是1002.carbon.zjg.metrics4.count)之后,执行
whisper-info.py /opt/graphite/storage/whisper/1002/carbon/zjg/metrics4/count.wsp
1 maxRetention: 604800
2 xFilesFactor: 0.0
3 aggregationMethod: sum
4 fileSize: 55348
5
6 Archive 0
7 retention: 21600
8 secondsPerPoint: 10
9 points: 2160
10 size: 25920
11 offset: 52
12
13 Archive 1
14 retention: 86400
15 secondsPerPoint: 60
16 points: 1440
17 size: 17280
18 offset: 25972
19
20 Archive 2
21 retention: 604800
22 secondsPerPoint: 600
23 points: 1008
24 size: 12096
25 offset: 43252aggregationMethod是sum,xFilesFactor是0。
- 每一个metric name就是一个wsp文件
十一、graphite-web
配置文件读取
graphite-web启动的时候会读取local_settings.py和settings.py(注意,local_settings.py的配置会覆盖settings.py的)
十二、安装并集成StatsD
1、下载
- git clone https://github.com/etsy/statsd.git
2、移动
- mv statsd /opt(将下载好的statsd文件夹移动到/opt下)
3、编写配置文件
-
cd /opt/statsd
-
cp exampleConfig.js config.js
-
vi config.js
1 {
2 port: 8125,
3
4 graphitePort: 2003,
5 graphiteHost: "127.0.0.1",
6 flushInterval: 10000,
7
8 backends: [ "./backends/graphite" ],
9 graphite: {
10 legacyNamespace: false
11 }
12 }4、启动
- node /opt/statsd/stats.js /opt/statsd/config.js
5、发包测试
- echo "foo:1|c" | nc -u -w0 127.0.0.1 8125
- 查看whisper下数据、log下文件以及graphite-web的图
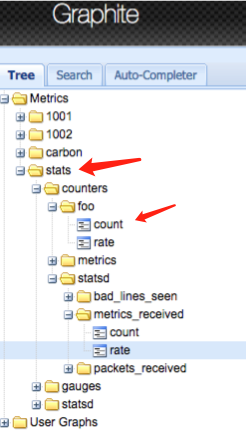
十三、安装并集成grafana
1、安装
yum install https://grafanarel.s3.amazonaws.com/builds/grafana-3.1.1-1470047149.x86_64.rpm
安装后的路径:
- Installs binary to
/usr/sbin/grafana-server - Copies init.d script to
/etc/init.d/grafana-server - Installs default file (environment vars) to
/etc/sysconfig/grafana-server - Copies configuration file to
/etc/grafana/grafana.ini - Installs systemd service (if systemd is available) name
grafana-server.service - The default configuration uses a log file at
/var/log/grafana/grafana.log - The default configuration specifies an sqlite3 database at
/var/lib/grafana/grafana.db
2、修改配置文件
- vi /etc/grafana/grafana.ini
- 修改grafana最高权限管理员:admin_user,admin_password(因为这两个值只能在grafana第一次启动之前设置一次,以后不能在设置了)
3、启动
- service /usr/sbin/grafana-server start
4、浏览器访问ip:3000并登陆
5、配置graphite
5.1、添加数据源datasource
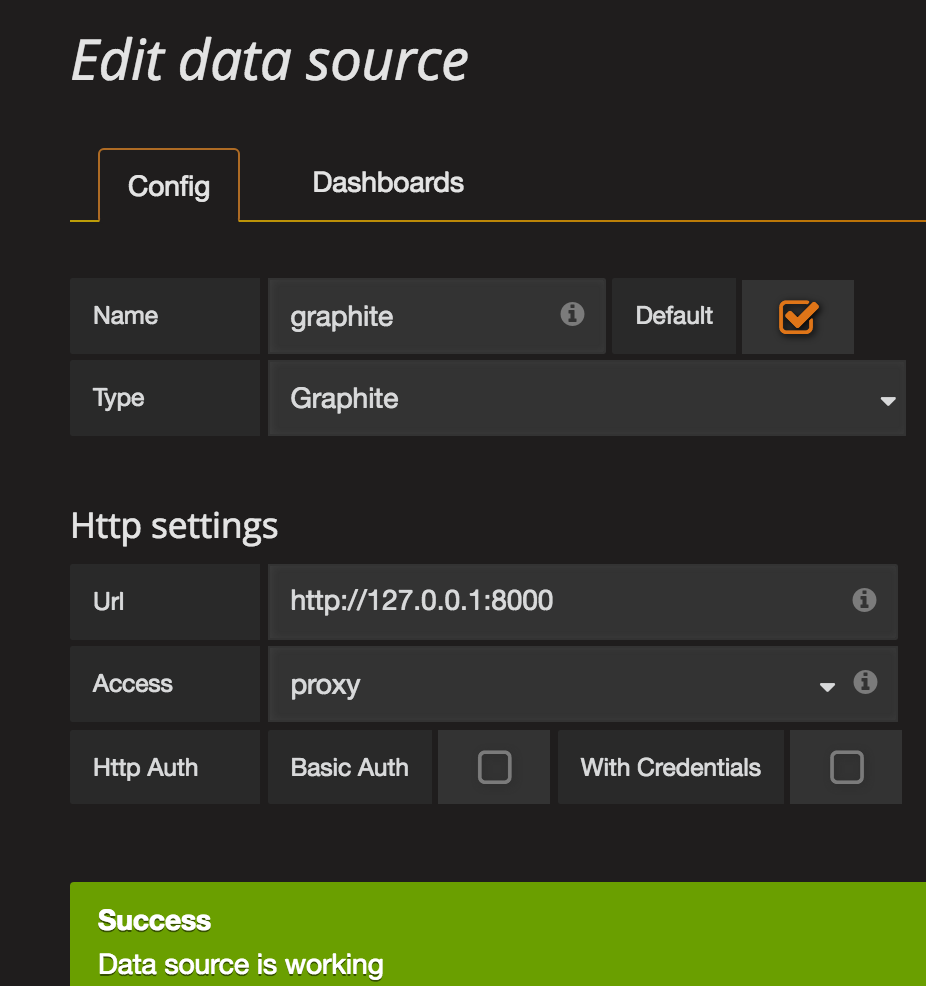
5.2、创建一个dashboard(这里直接引入,可以自己创建)
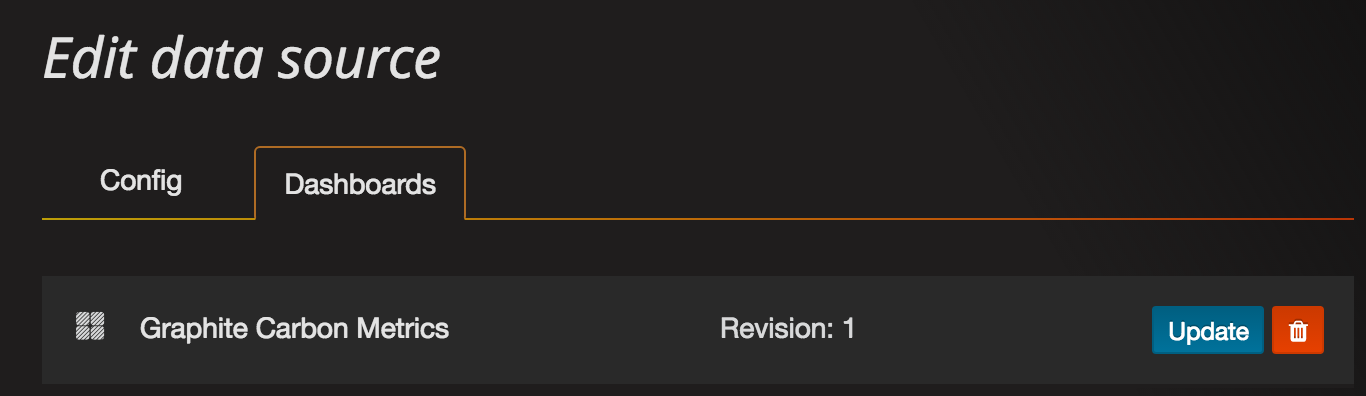
5.3、点击该dashboard查看数据
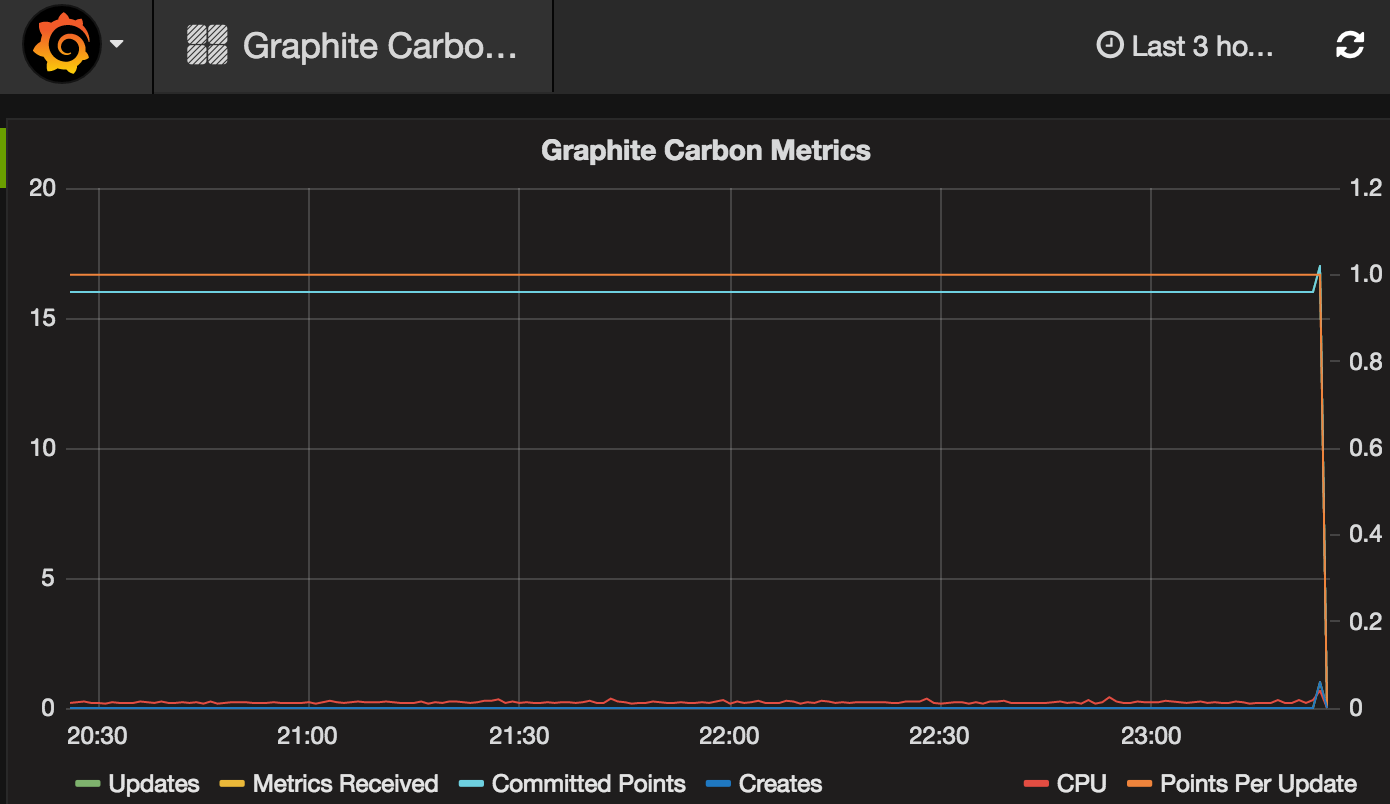
至此,statsd+graphite+grafana集成完毕!!!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









