






1.Date的after和before方法,比较日期大小
2.年月的加减(可指定年月):
YearMonth.now().minusMonths(12);--------当前月份的相加减
YearMonth.of(2017, 9).minusMonths(12);------指定年月的相加减
LocalDate localDate = lastYearMonth.atDay(1);----获取具体的年月日
localDate.atStartOfDay();----获取年月日时分
3.金融方面数据的千位分隔符处理:
sql层面处理:
Format(X,D)--------X表示要处理的字段,D表示保留的小数位
java代码处理:
public static String formatToSeparate(String data) {
if ("0".equals(data) || "0.00".equals(data)) {
return data;
}
//有小数位
if (data.indexOf(".") == -1) {
DecimalFormat df = new DecimalFormat("#,###");
return df.format(Integer.valueOf(data));
}
//整数位
DecimalFormat df = new DecimalFormat("#,###.00");
return df.format(Double.valueOf(data));
}4.链式编程:
java中的链式编程例如stringbuffer和stringbuilder这种。
StringBuilder sb=new StringBuilder();
sb.append("1").append("2").append("3");查看源码可知,stringbuffer和stringbuilder在append返回对象时都是return this
stringbuffer 适用于多线程,线程安全;stringbuilder适用于单线程,非线程安全,效率高。
链式编程:编程性强,可读性强,代码简介,业务要求高,不太利于代码调试
普通编程:维护性强,对返回值无要求,业务要求适中
5.单表行数超过五百万或者单表数据量超过2GB,才考虑分库分表,如果三年后的数据量达不到这个,就没必要分库分表。
6.sql优化的目标:至少达到range级别,要求是ref级别,如果可以是consts最好,consts单表中最多只有一行匹配行(主键或唯一索引),在优化阶段即可读取到数据,ref指的是使用了普通索引(normal index),range对索引进行范围检索。explain表的结果,type=index,表示速度非常慢,级别比range还低,与全表扫描是小巫见大巫。
7.使用ISNULL来判断是否为NULL值。
说明:NULL与任何值的比较都是NULL
a.NULL<>NULL的返回结果是NULL,而不是false
b.NULL=NULL的返回结果是NULL,而不是true
c.NULL<>1的返回结果是NULL,而不是true
8.mybatis中,xml文件中写sql时用#{ },不要使用${ },防止sql注入。
9.@Transactional 事务不要滥用,事务会影响数据库的QPS,另外使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚,搜索引擎回滚,消息补偿,统计修正等。
10.分层领域模型规约:
DO(Data Object):与数据库表结构一一对应,通过dao层向上传输数据源对象。
DTO(Data Transfer Object):数据传输对象,Service或Manager向外传输对象。
BO(Business Object):业务对象,由Service层输出的封装业务逻辑的对象。
AO(Application Object):应用对象,在Web层与service层之间抽象的复用对象模型,极为贴近展示层,复用度不高。
VO(View Object):显示层对象,通常是Web向模板渲染引擎层传输对象。
Query:数据查询对象,各层接收上层的查询请求,注意超过两个参数的查询封装,禁止Map类的传输。
11.高并发服务器建议调小TCP协议的time_wait超时时间
说明:操作系统默认240秒后,才会关闭处于time-wait状态的连接,在高并发访问下,服务器端会因为处于time_wait的连接数太多,可能无法建立新的连接,所以需要服务器调小此等待值。
在linux上请求变更/etc/sysctl.conf文件修改该缺省值。
net.ipv4.tcp_fin_timeout=30
12.调大服务器所支持的最大文件句柄数(File Descriptor,简写fd)。
主流操作系统的设计是将TCP/UDP连接采用与文件一样的方式去管理,即一个连接对应于一个fd。主流的linux服务器默认所支持的最大fd数量是1024,当并发连接数很大时很容易因为fd不足而出现open too many files错误,导致新的链接无法建立,建议将linux服务器所支持的最大句柄数调高倍数(与服务器的内存数量相关)。
13.给jvm设置-xx:+HeapDumpOnOutOfMemoryError 参数,让jvm碰到OOM场景时输出dump信息。
说明:OOM的发生是有概率的,甚至是有规律的相隔数月才出现一例,出现时的现场信息对查错非常有价值。
14.在线上生产环境,JVM的Xms和Xmx设置一样大小的内存容量,避免在GC后调整堆大小带来的压力。
15.服务器内部重定向使用forward;外部重定向地址使用URL拼装工具类来生成,否则会带来URL维护不一致的问题和潜在的安全风险。
16.mysql区分大小写(mysql默认是不区分大小写的)
区分大小写:方法一:建表时指定字段binary,例如:
CREATE TABLE NAME(
name VARCHAR(10) BINARY
);
方法二:在做查询的时候在字段前面添加BINARY即可区分大小写,BINARY不是函数,是类型转换运算符,用来强制将后面的字符串转换成二进制字符串(ASII值),起到区分大小写的作用。
方法三:当然也可以改现有库的字段:
ALTER TABLE 表名 MODIFY COLUMN 字段名 VARCHAR(20) BINARY DEFAULT NULL;也能达到区分大小写作用。
17.幂等性设计:
应用服务调用失败后,会将调用的请求重写发送到其他的服务器上,但是这个失败可能是个虚假的失败,比如是服务器的响应时间过慢,导致没收到响应,这时应用重新调用请求就会导致服务的重新调用,如果是个转账操作,那后果很严重。因此必须再服务层保证服务层的重复调用结果和单次调用结果相同,即服务具有幂等性。有些天然具有幂等性,比如用户性别,不管设置多少次,都是设置成某个属性,但如果是转账这样的操作,问题就比较复杂,需要通过交易编号等信息进行服务调用的有效性校验,只有有效的操作才可以继续执行。
18.清理dns缓存:清理方法:chrome://net-internals/#dns 然后点击里面的clear host cache。
19.git安装添加ssh key:
a.下载git bash,然后进入目录获取ssh key的值,命令: ssh-keygen -t rsa -C "dongdongyin@test.com"
git bash生成的密匙在 cd ~/.ssh
看有无文件,会生成 id_rsa, id_rsa.pub两个文件,其中 id_rsa.pub文件即为密匙,贴到ssh key中即可
b.将生成的key添加到git 的ssh key中去,title是git账号的邮箱,添加成功
20.本地测试接口时,可用注解@RunWith(SpringRunner.class),@SpringBootTest和@Test即可,不用启动项目。
21.SEM对接百度推广API:
http://dev2.baidu.com/newdev2/dist/index.html#/content/?pageType=3&productlineId=3
http://dev2.baidu.com/ueditor/jsp/upload/file/20170928/1506579076245087977.pdf
demo:http://dev2.baidu.com/newdev2/dist/index.html#/content/?pageType=1&productlineId=2&nodeId=186&pageId=105&url=
22.日志级别:
log4j建议只使用四个级别,优先级从高到低分别是ERROR,WARN,INFO,DEBUG四种,通过这里定义的日志级别,可以控制到应用程序中相应级别的日志开关,比如这里定义了info的日志级别,则日志程序中所有的debug级别的日志信息将不被打印出来,也就算说必须大于等于设置的日志级别才会被打印出来。日志级别也具有继承性,子类会记录父类的所有的日志级别。
一般在项目的logback.xml文件中可配置日志的级别:
<root level="debug">
<appender-ref ref="console" />
<appender-ref ref="rollingFile" />
</root>log4j的日志设置:
导包:log4j-1.2.16.jar 一般还会加入 commons-logging-1.1.1.jar
配置:在classpath下配置log4j.properties如下(可配置日志级别等信息):
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %5p %c{1}:%L - %m%n
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.file.File=${catalina.home}/logs/ddoMsg.log
#log4j.appender.file.File=D:/SmgpAppService/logs/smgpApp.log
log4j.appender.file.MaxFileSize=1024KB
log4j.appender.file.MaxBackupIndex=100
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern= %d{yyyy-MM-dd HH:mm:ss} %5p %c %t: - %m%n
#INFO WARN ERROR DEBUG
log4j.rootLogger=WARN, file, stdout
#log4j.rootLogger=INFO,stdout
org.apache.commons.logging.Log=org.apache.commons.logging.impl.SimpleLog
#org.apache.commons.logging.simplelog.log.org.apache.commons.digester.Digester=debug
#org.apache.commons.logging.simplelog.log.org.apache.commons.digester.ObjectCreateRule=debug
#org.apache.commons.logging.simplelog.log.org.apache.commons.digester.Digester.sax=info
log4j.logger.com.jason.ddoMsg=debug可配置输出的类型,控台输出(ConsoleAppender)或者文件输出(FileAppender)或者每天产生一个日志文件(DailyRollingFileAppender)或文件大小达到指定尺寸的时候生成文件(RollingFileAppender)或将日志信息以流的形式发到具体的某个位置(WriterAppender)等
23.git提交空文件夹:
在新建的空文件夹下面,新建一个.gitkeep文件,里面内容可以填写以下内容
# Ignore everything in this directory
*
# Except this file !.gitkeep ,这样就可以添加空文件夹。
24.文件路径:
开发中,如果要生成文件到项目中,路径的书写方式:
String semPath = this.getClass().getResource("/static").getPath();这里获取的是src/main/resources/static的目录,也使用于打包后的/target/classes/static目录下,获取的是相对路径,适用于开发。
也可以使用这种方式:
String tempPath = System.getProperty("user.dir") + "/temp/";获取的也是相对路径(适用于linux系统或者打包后的处理)
25.设置电脑保护色:http://jingyan.baidu.com/article/8cdccae9438422315413cde1.html
26.微信开发文档:https://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1455871652
27.鉴权处理(以及跨域的处理):
鉴权:后端配置常量,加上随机数,进行MD5加密,每次请求发送token和random进行鉴权.写在过滤器中,对于特殊不需要过滤的请求,可在字典表中进行配置处理。
跨域问题:
header设置问题:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Access-Control-Allow-Origin
在过滤器中,可设置:
response.setHeader("Access-Control-Allow-Origin", request.getHeader("Origin"));
response.setHeader("Access-Control-Allow-Credentials", "true");
response.setHeader("Access-Control-Max-Age", "3600");
response.setHeader("Access-Control-Allow-Headers", request.getHeader("Access-Control-Request-Headers"));
response.setHeader("Access-Control-Allow-Methods", request.getHeader("Access-Control-Request-Method"));其中,Access-Control-Allow-Origin表示:响应头指定了该响应的资源是否是被给定的orgin共享,
Access-Control-Allow-Credentials表示:是否可以将响应的头信息暴露给页面,
Access-Control-Max-Age表示:响应头提供的信息可以被缓存多久,
Access-Control-Allow-Headers表示:响应头信息
Access-Control-Allow-Methods表示:响应头的请求方法(get/post)。
28.java调用shell脚本:
https://github.com/Trinea/android-common/blob/master/src/cn/trinea/android/common/util/ShellUtils.java
以及http://bbs.csdn.net/topics/390895888
29.快速插入一百万条数据:
DECLARE @i int
set @i=0
WHILE @i<1000000
BEGIN
INSERT INTO t_activity_data (aid,page_id,create_d) VALUES (@i,@i,NOW())
SET @i=@i+1
END
也可使用sql:(翻倍操作)
INSERT INTO t_activity_data (aid,page_id,create_d) SELECT aid,page_id,create_d FROM t_activity_data
30.POI导出大数据量处理:详见另一博客:https://my.oschina.net/u/3110937/blog/1616236
31.跨域处理:http://www.ruanyifeng.com/blog/2016/04/cors.html
32.mysql相关:http://mysql.taobao.org/
33.在线画图软件:https://www.processon.com/
34.更改文件目录结构:
只需在pom.xml中添加标签即可:添加在<build>标签中即可---
<finalName>test-mimosa</finalName>
35.texlive + texmaker latex ----文件编辑器(跨平台)
36.区块链入门:http://www.ruanyifeng.com/blog/2017/12/blockchain-tutorial.html
37.@Async注解在使用的时候,注意方法调用的权限级别都要是public,因为这个注解使用的是代理类来的。如果设置成private,代理类没有权限执行。
38.建表时,做到能无符号数字就无符号,能数字就不字符,能时间就不字符,以后会很方便
39.Character.isDigit(char s)----判断是否为数字
Character.isLetter(char s)----判断是否为字母
40.解决idea中项目启动时出现的非法字符问题:
在settings中设置如下:-encoding UTF8
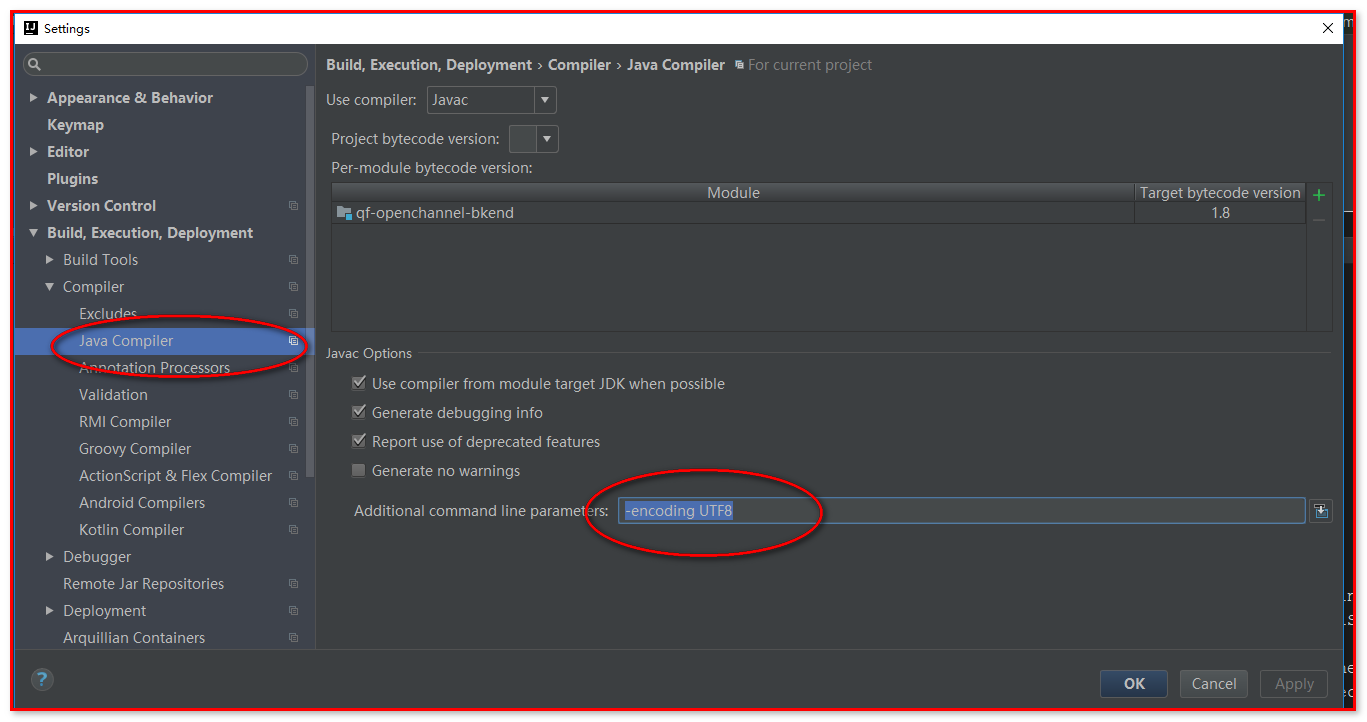
添加参数:-encoding UTF8
41.解决idea中项目启动时报的异常:
javax.management.InstanceNotFoundException: org.springframework.boot:type=Admin,name=SpringApplication
设置run->Edit Configurations
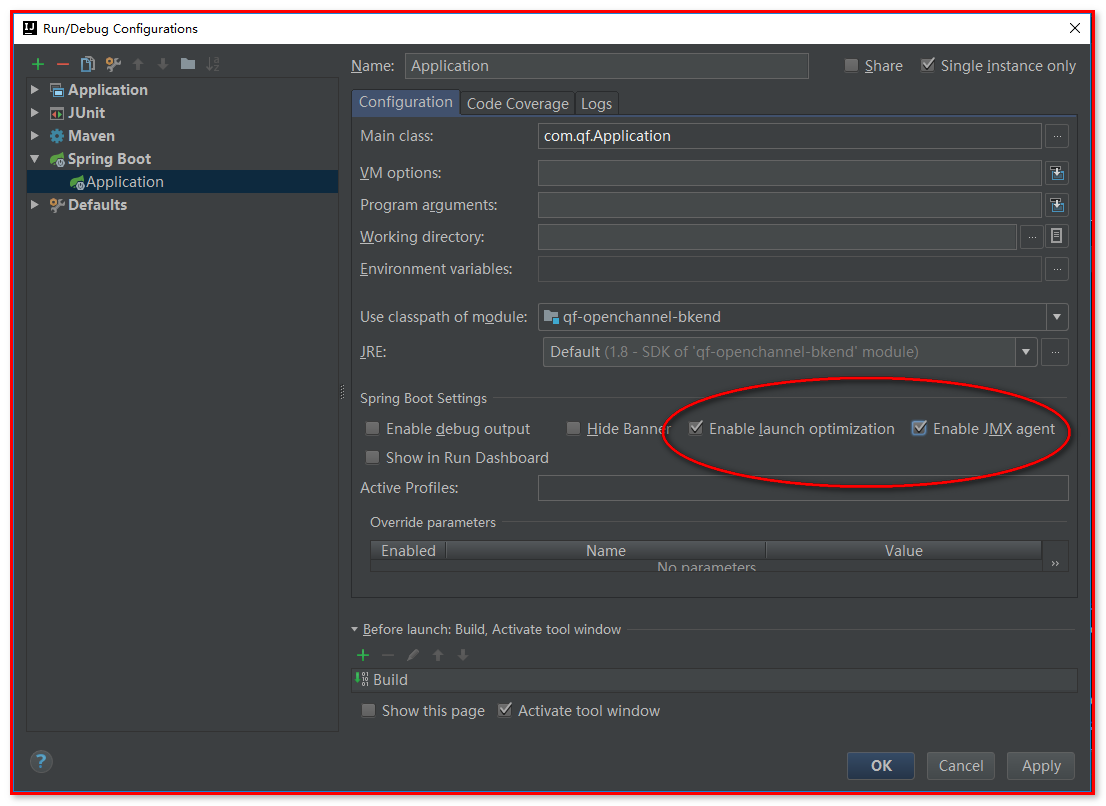
取消这两个勾选即可。
42.JVM的server模式和client模式:
两种模式,server模式可以大大提高性能,但启动比较缓慢,因为预编译的东西很大,client模式是预编译东西很少,所以启动很快,但是性能没有server模式高。
window 32位有server和client模式,64位只有server模式,其中查看jvm的启动模式可通过java -version查看:

修改启动模式可通过修改文件中-server和-client位置来修改:
文件位置:
文件内容:

修改两者配置顺序即可修改启动模式.
其中当jvm适用于GUI页面展示的时候使用client模式更佳,当jvm用于后台服务程序运行时使用server模式更佳。
client模式默认-Xms是1M,-Xmx是64M
server模式默认-Xms是128M,-Xmx是1024M
43.异步消息传递的技术(JMS,AMQP,MQTT):
消息异步处理是只要消息生产者生产了消息,不需要立即接收到响应,不会阻塞整个流程,响应可有可无,生产者不需要等待结果,可继续执行后续任务。
JMS:(java消息传递服务)---java的API
a.面向java的消息传递API
b.有Peer-2-Peer和Pub/sub两种消息传递模型,支持的消息类型有多种,有text,map,byte,object等等。
c.支持事务,不跨语言,不跨平台(这点相对于AMQP,是没有AMQP支持性好)
AMQP:(高级消息队列协议)--例如rabbitmq就是基于AMQP的
a.跨平台,跨语言
b.支持direct,fanout,topic,headers,system消息模型。消息类型支持byte
c.支持事务,支持分布式事务。
MQTT:消息队列遥测传输(Message Queueing Telemetry Transport )
a.面向流,内存占用低,适用于小型设备的消息传递。
b.不支持事务,消息时短暂的(短周期的)
44.并发问题处理:
案例:入库操作(先check是否已存在,不存在就insert,存在就退出)
解决:加入同步代码块,数据库字段添加唯一性约束unique:
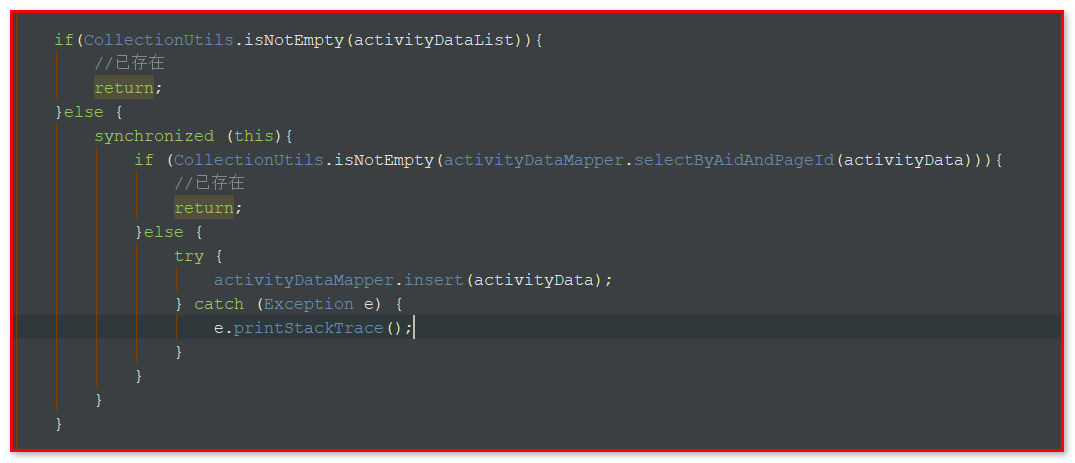
45.insert的时候同时获取主键:
方法一:

加入这两个即可,返回值在id里就能获取到,useGeneratedKeys表示主键自增长,keyProperty表示封装返回的主键值。返回的主键在User对象中,通过user.getId()来获取
方法二:
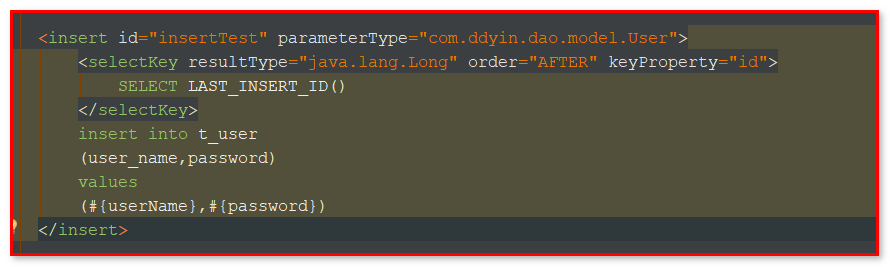
添加selectKey标签,通过keyProperty的属性值来封装返回的主键id值,order表示插入后执行selectKey,返回的主键在User对象中,通过user.getId()来获取
46.脏读,幻读和可重复读
脏读:A事务读取到B事务未提交的数据
幻读:A事务读取到其他事务的insert和delete操作(针对数据的新增或者删除)
可重复读(mysql的默认事务隔离级别):A事务读取到其他事务的更新操作(针对的是数据的更新操作)
47.未完待续。。。。。。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









