






1.elasticsearch基本概念
1.1 elasticsearch数据框架
在Elasticsearch中,文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以画一些简单的对比图来类比传统关系型数据库:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields1.2 elasticsearch索引
索引这个词在Elasticsearch中有着不同的含义,所以有必要在此做一下区分:
- 索引(名词) 如上文所述,一个索引就像是传统关系数据库中的数据库,它是相关文档存储的地方,index的复数是indices 或indexes。
- 索引(动词) 「索引一个文档」表示把一个文档存储到索引(名词)里,以便它可以被检索或者查询。这很像SQL中的
INSERT关键字,差别是,如果文档已经存在,新的文档将覆盖旧的文档。 - 倒排索引 传统数据库为特定列增加一个索引,例如B-Tree索引来加速检索。Elasticsearch和Lucene使用一种叫做倒排索引(inverted index)的数据结构来达到相同目的。默认情况下,文档中的所有字段都会被索引(拥有一个倒排索引),只有这样他们才是可被搜索的。
2.elasticsearch分布式集群
2.1elasticsearch分布式特点
Elasticsearch致力于隐藏分布式系统的复杂性。以下这些分布式操作都是在底层自动完成的:
- 将你的文档分区到不同的容器或者分片(shards)中,它们可以存在于一个或多个节点中。
- 将分片均匀的分配到各个节点,对索引和搜索做负载均衡。
- 冗余每一个分片,防止硬件故障造成的数据丢失。
- 将集群中任意一个节点上的请求路由到相应数据所在的节点。
- 无论是增加节点,还是移除节点,分片都可以做到无缝的扩展和迁移。
- 我们能够与集群中的任何节点通信,每一个节点都知道文档存在于哪个节点上,它们可以转发请求到相应的节点上。我们访问的节点负责收集各节点返回的数据,最后一起返回给客户端。
2.2 elasticsearch集群信息
2.2.1 集群健康
集群健康检查使用
GET /_cluster/health2.2.2 索引与分片
为了将数据添加到Elasticsearch,我们需要索引(index)——一个存储关联数据的地方。实际上,索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”。
分片是Elasticsearch在集群中分发数据的关键。把分片想象成数据的容器。文档存储在分片中,然后分片分配到你集群中的节点上。当你的集群扩容或缩小,Elasticsearch将会自动在你的节点间迁移分片,以使集群保持平衡。
分片可以是主分片(primary shard)或者是复制分片(replica shard)。复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的shard取回文档。当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整。
2.2.3 集群横向扩展
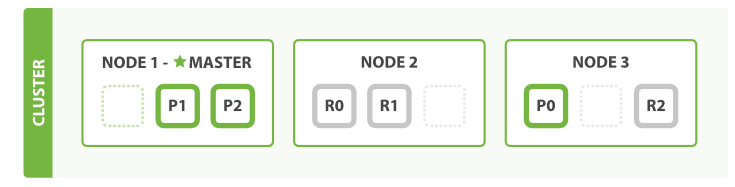
假设当前3个分片,一个分片复制集,扩展过程如下,只有一台机器:
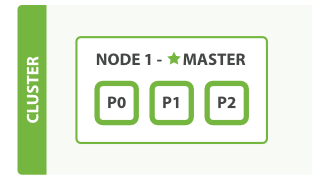
两台机器:
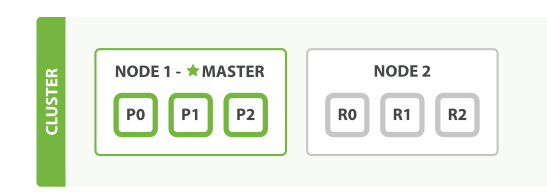
三台机器:
3. elasticsearch增删改查
3.1增加、覆盖更新相应的记录:
PUT /{index}/{type}/{id}
{
"field": "value",
...
}如果记录存在则会用新的值覆盖以前的值,如果记录不存在则插入
3.2 按照id查找相应的记录
GET /{index}/{type}/{id}
3.3 测试文档是否存在
想做的只是检查文档是否存在——你对内容完全不感兴趣——使用HEAD方法来代替GET。HEAD请求不会返回响应体,只有HTTP头:
curl -i -XHEAD http://localhost:9200/{index}/{type}/{id}Elasticsearch将会返回200 OK状态如果你的文档存在; 如果不存在返回404 Not Found
3.4 删除文档
DELETE /{index}/{type}/{id}
如果文档被找到,Elasticsearch将返回200 OK状态码
3.5 版本控制
当elasticsearch中的数据发生变化的时候,相应的数据版本也会增加;当同时存在多个请求共同修改一个文档的时候,就需要通过版本控制保证修改数据的正确性,也就是在修改数据的时候:
1.先拿到当前数据的版本version=1
2.修改数据的时候带上当前的版本作为参数,例如:
PUT /website/blog/1?version=1
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}如果在修改数据的时候,数据版本不是1,会报
{
"error" : "VersionConflictEngineException[[website][2] [blog][1]:
version conflict, current [2], provided [1]]",
"status" : 409
}3.6 局部更新
PUT /website/blog/1/_update
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}3.7 检索多个文档
使用mget将index、type、_id放入一个数组中请求,例子:
POST /_mget
{
"docs" : [
{
"_index" : "website",
"_type" : "blog",
"_id" : 2
},
{
"_index" : "website",
"_type" : "pageviews",
"_id" : 1,
"_source": "views"
}
]
}3.8 批量操作文档
示例(每一行的行末都要加入\n):
POST /_bulk
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}\n
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}\n
{ "title": "My first blog post" }\n
{ "index": { "_index": "website", "_type": "blog" }}\n
{ "title": "My second blog post" }\n
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }\n
{ "doc" : {"title" : "My updated blog post"} }\n4.elasticsearch分布式增删改查
4.1路由文档
当你索引一个文档,它被存储在单独一个主分片上。Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文档,它是如何知道是应该存储在分片1还是分片2上的呢?进程不能是随机的,因为我们将来要检索文档。事实上,它根据一个简单的算法决定:
shard = hash(routing) % number_of_primary_shardsrouting值是一个任意字符串,它默认是_id但也可以自定义。这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
5.搜索
5.1 空搜索
Get /{index}/{type}/_search
返回hits代表搜索的记录数
分页需要传递from和size,from表示跳过开始的结果数,size代表请求多少个结果,例如:
/_search?from=5&size=10代表跳过5个开头的结果,请求10个结果,但是深度分页通常效率比较低
为了理解为什么深度分页是有问题的,让我们假设在一个有5个主分片的索引中搜索。当我们请求结果的第一页(结果1到10)时,每个分片产生自己最顶端10个结果然后返回它们给请求节点(requesting node),它再排序这所有的50个结果以选出顶端的10个结果。
现在假设我们请求第1000页——结果10001到10010。工作方式都相同,不同的是每个分片都必须产生顶端的10010个结果。然后请求节点排序这50050个结果并丢弃50040个
5.2 简易搜索
将所有参数通过查询字符串定义,完全匹配的例子如下:
GET /_all/tweet/_search?q=tweet:elasticsearch上面查询语句的意思表示查询tweet字段为elasticsearch
下一个语句查找name字段中包含"john"和tweet字段包含"mary"的结果。实际的查询只需要:
q=+name:john+tweet:mary6.映射和分析
6.1映射
为了能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理成全文本(Full-text)或精确的字符串值,Elasticsearch需要知道每个字段里面都包含了什么类型。这些类型和字段的信息存储(包含)在映射(mapping)中。 索引中每个文档都有一个类型(type)。 每个类型拥有自己的映射(mapping)或者模式定义(schema definition)。
6.1.1查看映射
示例: 查看索引gb类型tweet中的映射:
GET /gb/_mapping/tweet{
"gb": {
"mappings": {
"tweet": {
"properties": {
"date": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"name": {
"type": "string"
},
"tweet": {
"type": "string"
},
"user_id": {
"type": "long"
}
}
}
}
}
}对于string类型的字段,两个最重要的映射参数是index和analyzer,index参数控制字符串以何种方式被索引。它包含以下三个值当中的一个:

string类型字段默认值是analyzed。如果我们想映射字段为确切值,我们需要设置它为not_analyzed
6.1.2 创建一个新索引
PUT /gb
{
"mappings": {
"tweet" : {
"properties" : {
"tweet" : {
"type" : "string",
"analyzer": "english"
},
"date" : {
"type" : "date"
},
"name" : {
"type" : "string"
},
"user_id" : {
"type" : "long"
}
}
}
}
}6.1.3 修改索引
PUT /gb/_mapping/tweet
{
"properties" : {
"tag" : {
"type" : "string",
"index": "not_analyzed"
}
}
}6.2 分析
一个分析器(analyzer)只是一个包装用于将三个功能放到一个包里:
6.2.1 字符过滤器
首先字符串经过字符过滤器(character filter),它们的工作是在标记化前处理字符串。字符过滤器能够去除HTML标记,或者转换"&"为"and"。
6.2.2 分词器
下一步,分词器(tokenizer)被标记化成独立的词。一个简单的分词器(tokenizer)可以根据空格或逗号将单词分开(译者注:这个在中文中不适用)。
6.2.3 标记过滤
最后,每个词都通过所有标记过滤(token filters),它可以修改词(例如将"Quick"转为小写),去掉词(例如停用词像"a"、"and"、"the"等等),或者增加词(例如同义词像"jump"和"leap")
7.结构化查询
7.1查询与过滤
7.1.1 过滤是精确匹配的过程
一条过滤语句会询问每个文档的字段值是否包含着特定值,例如:
created 的日期范围是否在 2013 到 2014 ?
status 字段中是否包含单词 "published" ?
lat_lon 字段中的地理位置与目标点相距是否不超过10km ?
7.1.2 如果索引使用分析器,查询会利用分析器查询匹配度;否则精确匹配
查询语句会询问每个文档的字段值与特定值的匹配程度如何?
查询语句的典型用法是为了找到文档:
查找与 full text search 这个词语最佳匹配的文档
查找包含单词 run ,但是也包含runs, running, jog 或 sprint的文档
同时包含着 quick, brown 和 fox --- 单词间离得越近,该文档的相关性越高
标识着 lucene, search 或 java --- 标识词越多,该文档的相关性越高
一条查询语句会计算每个文档与查询语句的相关性,会给出一个相关性评分 _score,并且 按照相关性对匹配到的文档进行排序。 这种评分方式非常适用于一个没有完全配置结果的全文本搜索。
7.2 结构化查询
7.2.1 简单的结构化查询
GET /_search
{
"query": {
"match": {
"tweet": "elasticsearch"
}
}
}7.2.2 简单合并多子句
GET /_search
{
"bool": {
"must": { "match": { "tweet": "elasticsearch" }},
"must_not": { "match": { "name": "mary" }},
"should": { "match": { "tweet": "full text" }}
}
}以下实例查询的是邮件正文中含有“business opportunity”字样的星标邮件或收件箱中正文中含有“business opportunity”字样的非垃圾邮件:
{
"bool": {
"must": { "match": { "email": "business opportunity" }},
"should": [
{ "match": { "starred": true }},
{ "bool": {
"must": { "folder": "inbox" }},
"must_not": { "spam": true }}
}}
],
"minimum_should_match": 1
}
}7.3 过滤语句
term主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed的字符串(未经分析的文本数据类型)
7.3.1 普通term语句例子
{ "term": { "age": 26 }}7.3.2 terms过滤
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配:
{
"terms": {
"tag": [ "search", "full_text", "nosql" ]
}
}7.3.3 range过滤
range过滤允许我们按照指定范围查找一批数据:
{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}7.3.4 exists 和 missing 过滤
exists 和 missing过滤可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的IS_NULL条件
{
"exists": {
"field": "title"
}
}7.3.5 bool过滤
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,它包含一下操作符:
must :: 多个查询条件的完全匹配,相当于 and。
must_not :: 多个查询条件的相反匹配,相当于 not。
should :: 至少有一个查询条件匹配, 相当于 or。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组
{
"bool": {
"must": { "term": { "folder": "inbox" }},
"must_not": { "term": { "tag": "spam" }},
"should": [
{ "term": { "starred": true }},
{ "term": { "unread": true }}
]
}
}7.4 过滤查询
查询语句和过滤语句可以放在各自的上下文中。 在 ElasticSearch API 中我们会看到许多带有 query 或 filter 的语句。 这些语句既可以包含单条 query 语句,也可以包含一条 filter 子句。 换句话说,这些语句需要首先创建一个query或filter的上下文关系。
复合查询语句可以加入其他查询子句,复合过滤语句也可以加入其他过滤子句。 通常情况下,一条查询语句需要过滤语句的辅助,全文本搜索除外。
所以说,查询语句可以包含过滤子句,反之亦然。 以便于我们切换 query 或 filter 的上下文。这就要求我们在读懂需求的同时构造正确有效的语句
7.4.1 过滤一条查询语句
比如说我们有这样一条查询语句:
{
"match": {
"email": "business opportunity"
}
}然后我们想要让这条语句加入 term 过滤,在收信箱中匹配邮件:
{
"term": {
"folder": "inbox"
}
}search API中只能包含 query 语句,所以我们需要用 filtered 来同时包含 "query" 和 "filter" 子句:
{
"filtered": {
"query": { "match": { "email": "business opportunity" }},
"filter": { "term": { "folder": "inbox" }}
}
}我们在外层再加入 query 的上下文关系:
GET /_search
{
"query": {
"filtered": {
"query": { "match": { "email": "business opportunity" }},
"filter": { "term": { "folder": "inbox" }}
}
}
}7.4.2 单条过滤语句
在 query 上下文中,如果你只需要一条过滤语句,比如在匹配全部邮件的时候,你可以 省略 query 子句:
GET /_search
{
"query": {
"filtered": {
"filter": { "term": { "folder": "inbox" }}
}
}
}7.4.3 查询语句中的过滤
有时候,你需要在 filter 的上下文中使用一个 query 子句。下面的语句就是一条带有查询功能 的过滤语句, 这条语句可以过滤掉看起来像垃圾邮件的文档:
GET /_search
{
"query": {
"filtered": {
"filter": {
"bool": {
"must": { "term": { "folder": "inbox" }},
"must_not": {
"query": {
"match": { "email": "urgent business proposal" }
}
}
}
}
}
}
}7.5 排序
7.5.1 字段值排序
下面例子中,对结果集按照时间排序,这也是最常见的情形,将最新的文档排列靠前。 我们使用 sort 参数进行排序:
GET /_search
{
"query" : {
"filtered" : {
"filter" : { "term" : { "user_id" : 1 }}
}
},
"sort": { "date": { "order": "desc" }}
}














 4203
4203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









