






什么是分区?
把大数据对象 (表, 索引)被分成小物理段,当分区表建立时,记录基于分区字段值被存储到相应分区。当分区表建立时,记录基于分区字段值被存储到相应分区,分区字段值可以修改,可以存储在不同的表空间,可以有不同的物理存储参数,支持IOT表,对象表,LOB字段,varrays等。
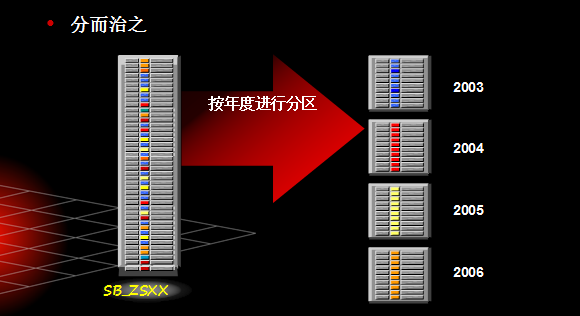
分区的好处?
查询只是查询指定分区,数据更少,速度快,好维护。
如何实施分区?
oracle分区分为四种:1.范围分区(Range partitioning);2.hash分区(Hash partitioning);3.列表分区 (List partitioning);4.组合分区(Composite partitioning)
1)范围分区(Range partitioning)
CREATE TABLE sales
(acct_no NUMBER(5),
person VARCHAR2(30),
sales_amount NUMBER(8),
week_no NUMBER(2))
PARTITION BY RANGE (week_no)
(PARTITION P1 VALUES LESS THAN (4) TABLESPACE data0,
PARTITION P2 VALUES LESS THAN (8) TABLESPACE data1,
...…
PARTITION P13 VALUES LESS THAN (53)TABLESPACE data12Range分区是最早、最经典的分区算法,Range分区通过对分区字段值的范围进行分区,特别适合于按时间周期进行数据的存储。日、周、月、年等。缺点是范围分区的数据可能不均匀,范围分区与记录值相关,实施难度和可维护性相对较差。
2)hash分区(Hash partitioning)
create table CUSTOMERS (... column definitions ...)
pctfree 0 nologging
storage ( initial 40m next 40m pctincrease 0 )
partition by hash(customer_no) partitions 8 store in (cust_data01,cust_data02)
create table CUSTOMERS (... column definitions ...)
pctfree 0 nologging
storage ( initial 40m next 40m pctincrease 0 )
partition by hash(customer_no)
(partition cust_p01 tablespace cust_data01
,partition cust_p02 tablespace cust_data02
,partition cust_p03 tablespace cust_data03
,partition cust_p04 tablespace cust_data04
,partition cust_p05 tablespace cust_data05
,partition cust_p06 tablespace cust_data06
,partition cust_p07 tablespace cust_data07
,partition cust_p08 tablespace cust_data08)基于分区字段的HASH值,自动将记录插入到指定分区。分区数一般是2的幂,易于实施,总体性能最佳,适合于静态数据。HASH分区适合于数据的均匀存储,HASH分区特别适合于PDML和partition-wise joins。支持 (hash) local indexes,9i 不支持 (hash) global indexes,10g 支持(hash) global indexes HASH分区。缺点是数据管理能力弱,HASH分区对数据值无法控制。
3)列表分区 (List partitioning)
create table addresses (... column definitions ...)
pctfree 0 nologging
storage ( initial 40m next 40m pctincrease 0 )
partition by list(city_name)
(partition addr_p01 values ('WELLINGTON') tablespace addr_data01
,partition addr_p02 values ('CHRISTCHURCH') tablespace addr_data02
,partition addr_p03 values ('DUNEDIN','INVERCARGILL') tablespace addr_data03
,partition addr_p04 values ('AUCKLAND') tablespace addr_data04
,partition addr_p05 values ('HAMILTON','ROTORUA','TAURANGA') tablespace addr_data05)ist分区通过对分区字段的离散值进行分区。List分区是不排序的,而且分区之间没有关联关系,List分区适合于对数据离散值进行控制。List分区只支持单个字段。List分区具有与范围分区相似的优缺点,数据管理能力强。List分区的数据可能不均匀,List分区与记录值相关,实施难度和可维护性相对较差
3)列表分区 (List partitioning)
create table addresses (... column definitions ...)
pctfree 0 nologging
storage ( initial 40m next 40m pctincrease 0 )
partition by list(city_name)
(partition addr_p01 values ('WELLINGTON') tablespace addr_data01
,partition addr_p02 values ('CHRISTCHURCH') tablespace addr_data02
,partition addr_p03 values ('DUNEDIN','INVERCARGILL') tablespace addr_data03
,partition addr_p04 values ('AUCKLAND') tablespace addr_data04
,partition addr_p05 values ('HAMILTON','ROTORUA','TAURANGA') tablespace addr_data05)ist分区通过对分区字段的离散值进行分区。List分区是不排序的,而且分区之间没有关联关系,List分区适合于对数据离散值进行控制。List分区只支持单个字段。List分区具有与范围分区相似的优缺点,数据管理能力强。List分区的数据可能不均匀,List分区与记录值相关,实施难度和可维护性相对较差。
4)组合分区(Composite partitioning)
create table daily_trans_data (...column definitions ...)
partition by range(trans_datetime)
subpartition by hash(customer_no) subpartitions 8 store in (dtd_data01,dtd_data02)
(partition dtd_20010620 values less than (to_date('21-jun-2001','dd-mon-yyyy'))
(subpartition dtd_20010620_s01
,subpartition dtd_20010620_s02
,subpartition dtd_20010620_s03 tablespace dtd_data03
,subpartition dtd_20010620_s04 tablespace dtd_data04
,subpartition dtd_20010620_s05 tablespace dtd_data05
,subpartition dtd_20010620_s06 tablespace dtd_data06
,subpartition dtd_20010620_s07 tablespace dtd_data07
,subpartition dtd_20010620_s08 tablespace dtd_data08
)
,partition dtd_20010621 values less than (to_date('22-jun-2001','dd-mon-yyyy'))
,partition dtd_20010622 values less than (to_date('23-jun-2001','dd-mon-yyyy')) subpartitions 4
)Oracle支持的Composite分区: Range-Hash,Range-List,既适合于历史数据,又适合于数据均匀分布,与范围分区一样提供高可用性和管理性。有更好的PDML和partition-wise joins性能,实现粒度更细的操作,支持复合 local indexes,不支持复合composite global indexes。















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









