







论文名称:Searching for MobileNetV3
作者:Googler
论文链接:https://arxiv.org/abs/1905.02244
简要概述文章精华
mobilenet-v3是Google继mobilenet-v2之后的又一力作,作为mobilenet系列的新成员,自然效果会提升,mobilenet-v3提供了两个版本,分别为mobilenet-v3 large 以及mobilenet-v3 small,分别适用于对资源不同要求的情况,论文中提到,mobilenet-v3 small在imagenet分类任务上,较mobilenet-v2,精度提高了大约3.2%,时间却减少了15%,mobilenet-v3 large在imagenet分类任务上,较mobilenet-v2,精度提高了大约4.6%,时间减少了5%,mobilenet-v3 large 与v2相比,在COCO上达到相同的精度,速度快了25%,同时在分割算法上也有一定的提高。本文还有一个亮点在于,网络的设计利用了NAS(network architecture search)算法以及NetAdapt algorithm算法。并且,本文还介绍了一些提升网络效果的trick,这些trick也提升了不少的精度以及速度。
文章介绍
近年来,随着智能应用的不断增加,轻量化网络成为近年来的一个研究热点,毕竟不是所有设备都有GPU来计算的,轻量化 网络顾名思义,就是网络的参数量比较少,速度较快,下面总结了目前常用的一些减少网络计算量的方法:
- 基于轻量化网络设计:比如mobilenet系列,shufflenet系列, Xception等,使用Group卷积、1x1卷积等技术减少网络计算量的同时,尽可能的保证网络的精度。
- 模型剪枝: 大网络往往存在一定的冗余,通过剪去冗余部分,减少网络计算量。
- 量化:利用TensorRT量化,一般在GPU上可以提速几倍。
- 知识蒸馏:利用大模型(teacher model)来帮助小模型(student model)学习,提高student model的精度。
mobilenet系列当然是典型的第一种方法。在介绍mobilenet v3前,先来回顾一下mobilenet v1和v2的创新点:
mobilenet v1
- 利用分组卷积降低网络的计算量,并且mobilenet将分组卷积应用到极致,即网络的分组数与网络的channel数量相等,使网络的计算量减到最低,但是这样channel之间的交互就没有了,所以作者又使用的point-wise conv,即使用1x1的卷积进行channel之间的融合。
- 直筒结构。
mobilenet v2:
- 引入了bottleneck结构。
- 将bottleneck结构变成了纺锤型,即resnet是先缩小为原来的1/4,再放大,他是放大到原来的6倍,再缩小。
- 并且去掉了Residual Block最后的ReLU。
那么mobilenet v3又引入了哪些黑科技呢?:
话不多说,直接上重点
- 1.引入SE结构
在bottlenet结构中加入了SE结构,并且放在了depthwise filter之后,如下图。因为SE结构会消耗一定的时间,所以作者在含有SE的结构中,将expansion layer的channel变为原来的1/4,这样作者发现,即提高了精度,同时还没有增加时间消耗。并且SE结构放在了depthwise之后。
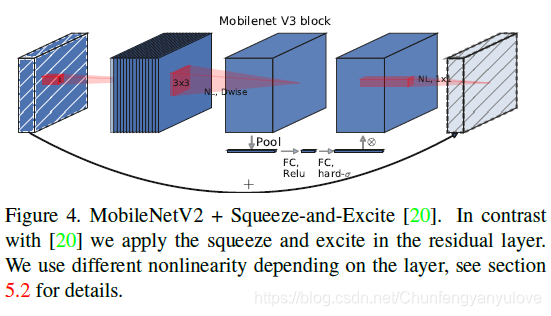
- 2.修改尾部结构:
在mobilenetv2中,在avg pooling之前,存在一个1x1的卷积层,目的是提高特征图的维度,更有利于结构的预测,但是这其实带来了一定的计算量了,所以这里作者修改了,将其放在avg pooling的后面,首先利用avg pooling将特征图大小由7x7降到了1x1,降到1x1后,然后再利用1x1提高维度,这样就减少了7x7=49倍的计算量。并且为了进一步的降低计算量,作者直接去掉了前面纺锤型卷积的3x3以及1x1卷积,进一步减少了计算量,就变成了如下图第二行所示的结构,作者将其中的3x3以及1x1去掉后,精度并没有得到损失。这里降低了大约15ms的速度。
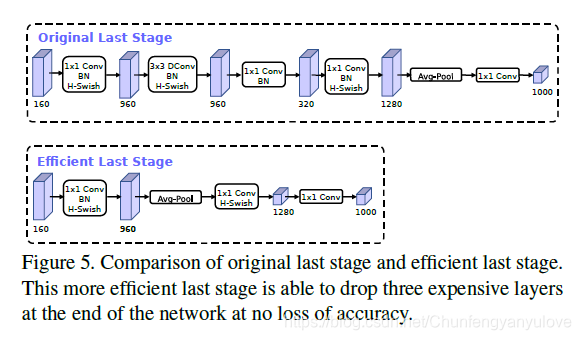
- 3.修改channel数量
修改头部卷积核channel数量,mobilenet v2中使用的是32 x 3 x 3,作者发现,其实32可以再降低一点,所以这里作者改成了16,在保证了精度的前提下,降低了3ms的速度。,这里给出了mobilenet v2以及mobilenet v3的结构对比:

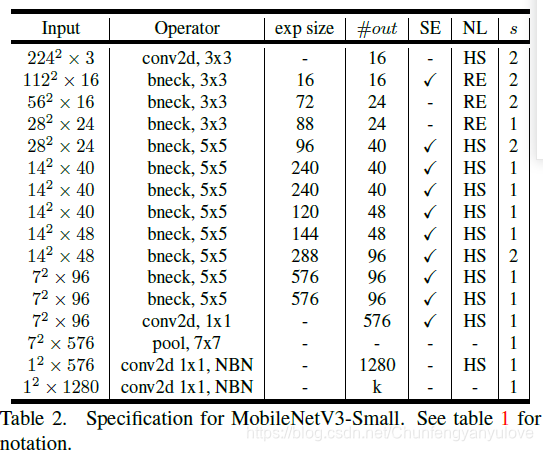
- 4.非线性变换的改变
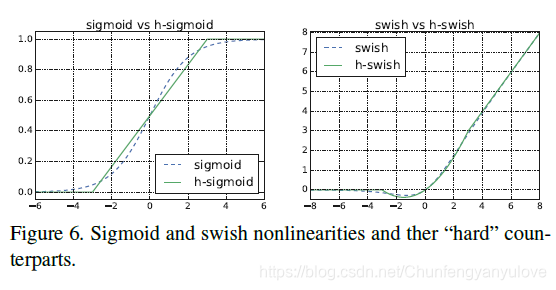
使用h-swish替换swish,swish是谷歌自家的研究成果,颇有点自卖自夸的意思,这次在其基础上,为速度进行了优化。swish与h-swish公式如下所示,由于sigmoid的计算耗时较长,特别是在移动端,这些耗时就会比较明显,所以作者使用ReLU6(x+3)/6来近似替代sigmoid,观察下图可以发现,其实相差不大的。利用ReLU有几点好处,1.可以在任何软硬件平台进行计算,2.量化的时候,它消除了潜在的精度损失,使用h-swish替换swith,在量化模式下回提高大约15%的效率,另外,h-swish在深层网络中更加明显。
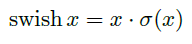

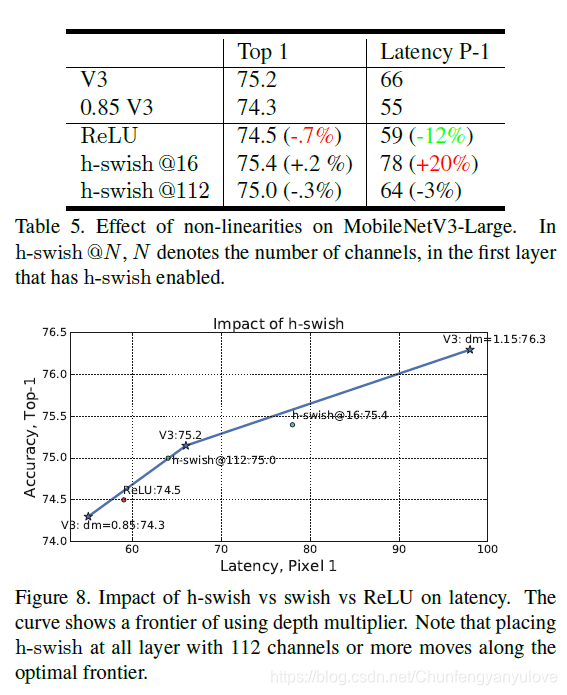
如下两张图展示的是使用h-swish对于时间以及精度的影响,可以发现,使用h-swish@16可以提高大约0.2%的精度,但是持剑延长了大约20%。
虽然mobilenet v3结构你已经知道了,但是,本文的重点,如何设计出的这个网络,即如何进行网络结构的搜索,还是有必要提一下的,这里我也没有细细研究,想深入了解的同学可以自行对应阅读论文
总体过程很简单,先通用NAS算法,优化每一个block,得到大体的网络结构,然后使用NetAdapt 算法来确定每个filter的channel的数量
这里由于small model的精度以及耗时影响相对较大,mobilenet v3 large和mobilenet v3 small是分别使用NAS设计的。
NAS之后,可以使用NetAdapt算法设计每个layer,过程如下:
-
先用NAS找到一个可用的结构A。
-
- 在A的基础上生成一系类的候选结构,并且这些候选结构消耗在一点点减少,其实就是穷举子结构。
- 对于每个候选结构,使用前一个模型进行初始化,(前一个模型没有的参数随机初始化就行),finetune T个epoch,得到一个大致的精度。
- 在这些候选结构中,找到最好的。
-
反复迭代,知道目标时间到达,找到最合适的结果。
候选是怎么选取的呢?
- 降低expansion layer的size.
- 减少botleneck
实验部分:
首先是分类部分的实验,向来比较豪的谷歌这次也不例外,作者使用16块TPU,batchsize为4096进行训练。然后作者选择在Google的Pixel Phone进行测试。
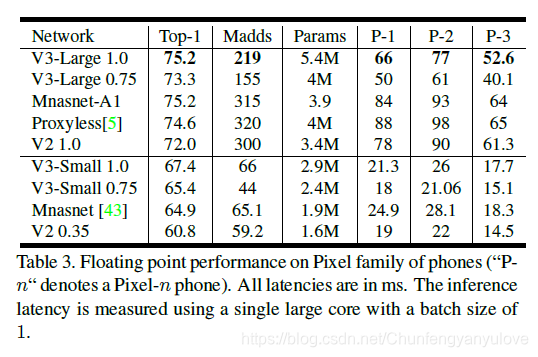
下图为作者ImageNet网络的测试结果,结果可以看出V3 large相比较与V2 1.0 精度上提高了大约3个点,但是速度却从78ms下降到66ms(Pixel-1手机),V3 small 相比较与V2 0.35,精度从60%提高到了67%,速度稍有增加,从19ms增加到21ms(Pixel-1手机).
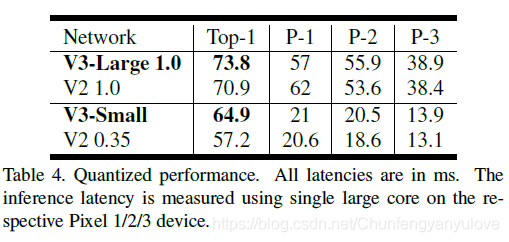
下图对比了不同的google phone上面,模型量化后(float量化,非int8量化)的耗时,其中P-1,P-2,P-3分别代表的是不同性能的手机。我这里主要分析一下V3-Large网络吧,可见量化后,TOP-1精度从上面图的75.2%下降到了73.8%,降低了大约1.5个点,符合正常情况,在P1-P3的加速效果来看P1加速了9ms(66ms),P2加速了20ms(77ms),P3加速了15ms(52.6ms)。与V2网络相比,其实速度相差不大,(为啥原本速度相差还挺大,量化之后相差不大了呢?这是个值得考虑的问题)
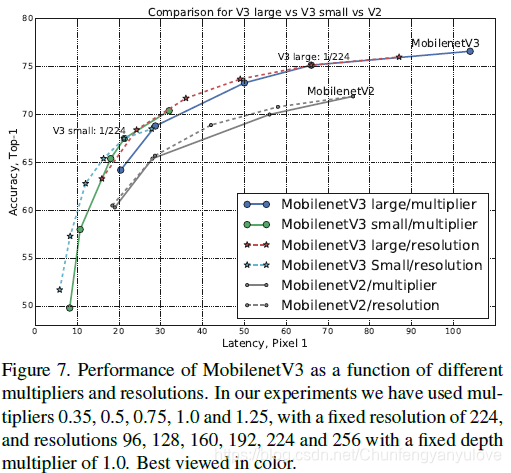
下图是作者实验了使用不同的分辨率以及不同的模型深度的精度对比,分辨率分别选择的是[96,128,160,192,224,256],深度分别选为原来的[0.35,0.5,0.75,1.0,1.25]。可见,其实resolution对于精度以及速度的平衡效果更好,可以达到更快的速度,同时精度没有改变模型深度精度低,反而更高。(但是很多时候,其实分辨率的大小是根据场景决定的,比如检测和分割就需要较大尺度的图像)。
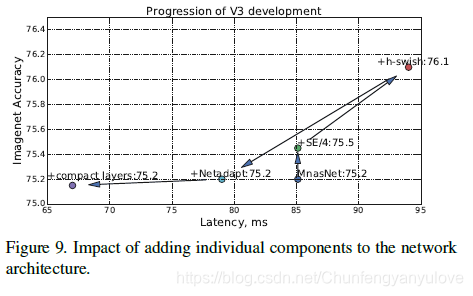
下图展示了从MnasNet经过一系列的修改,到mobileNet v3的精度与速度变化的过程。
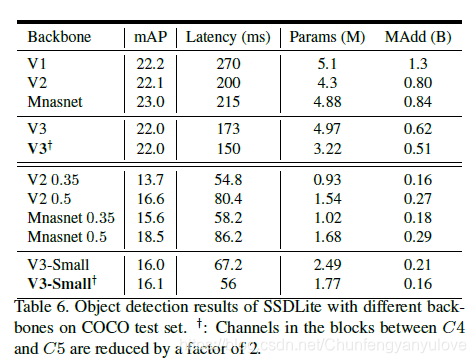
下图是将mobilenet v3应用于SSD-Lite在COCO测试集的精度结果。观察可以发现,在V3-Large上面,mAP没有特别大的提升但是速度确实降低了一些的。
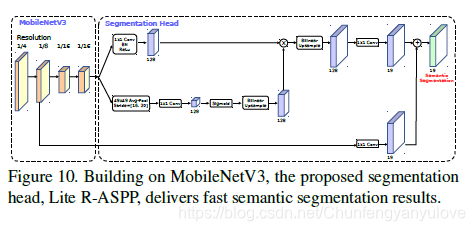
下图是分割的结构图,这里就不详细介绍了,感兴趣的读者可以自行看论文。
总结
总结来看,mobilenet V3其实并没有惊艳的结构提出,最主要的还是应用了诸如SE、H-Swish等tricks,然后利用Google前面提出的NAS以及NetAdapt算法进行结构的自动搜索,提升了一定的精度,降低了一定的速度。可能本篇论文的重点更在于进一步展示一下网络自动结构搜索的有效性,这样对应了文中的标题:Searching for,毕竟这也是发展的一个势头。
文中有不足或错误的地方,欢迎广大小伙伴批评指正。














 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









