






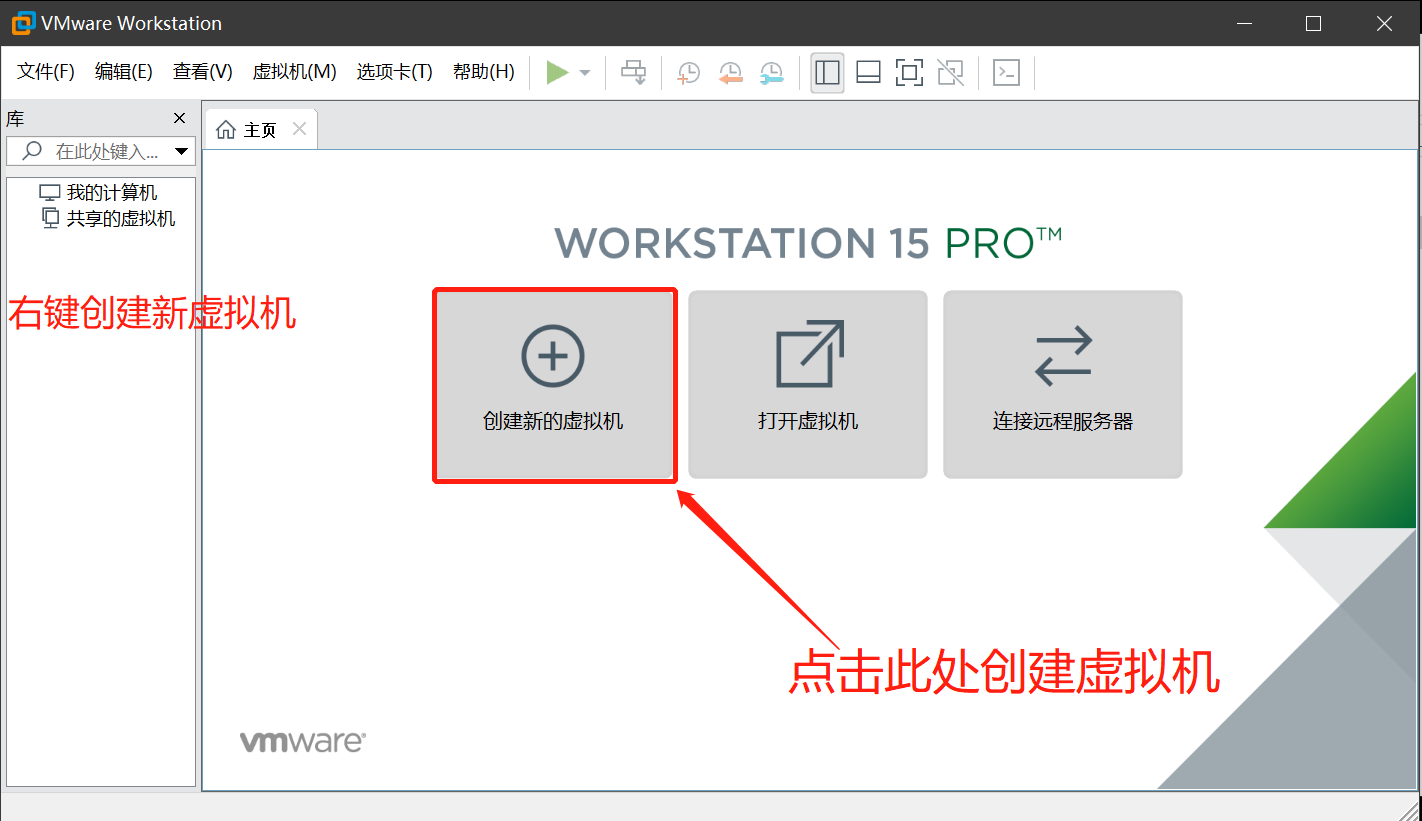
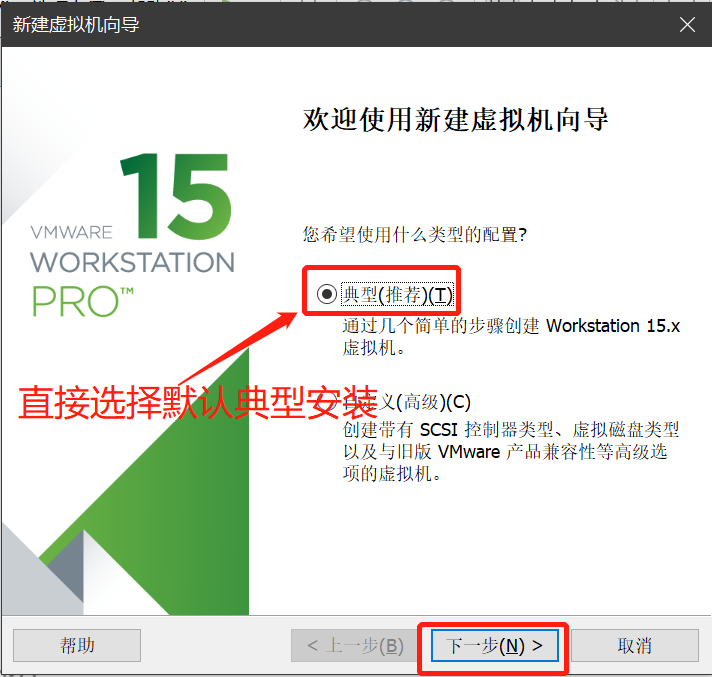
虚拟机软件VMware安装
- 安装VMware
- 在官网下载VMware安装包下载地址
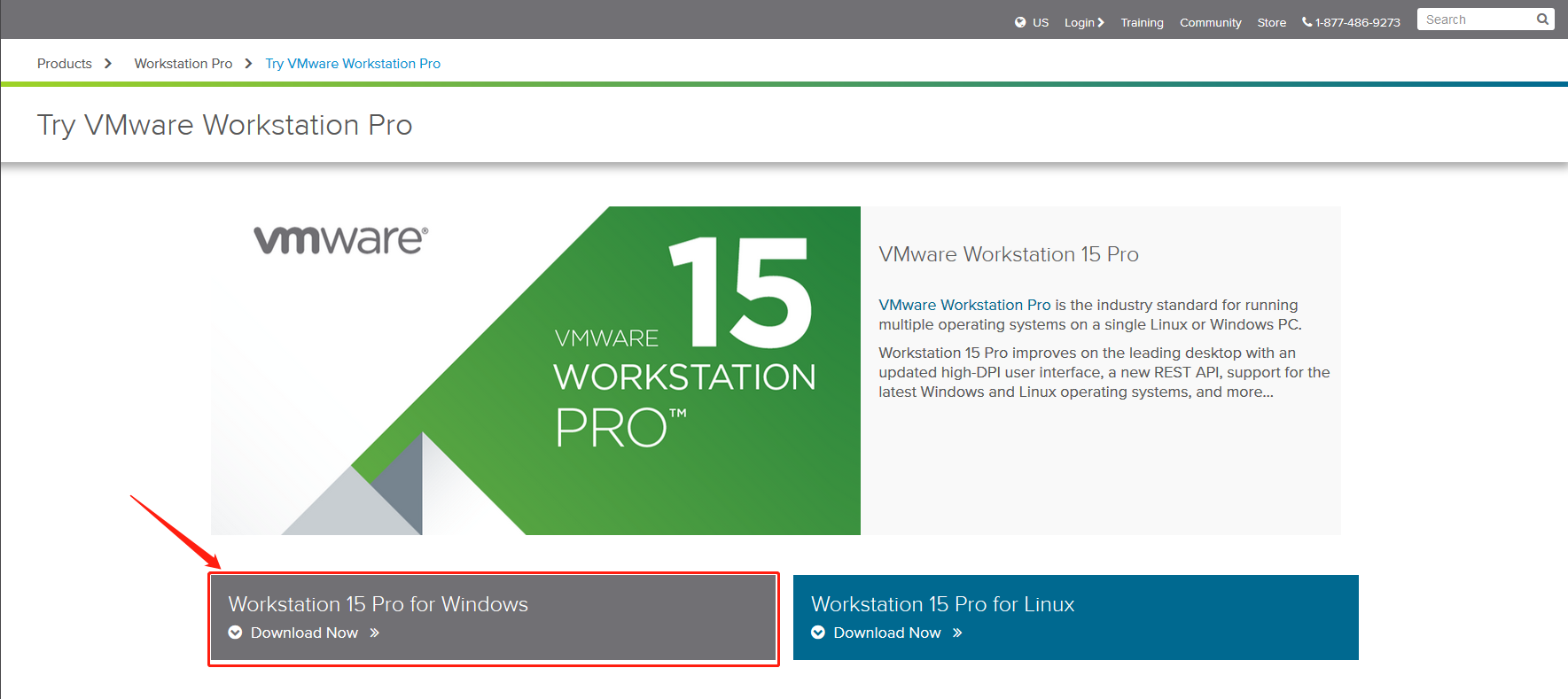
- 双击安装程序VMware-workstation-full-15.0.2-10952284.exe运行安装
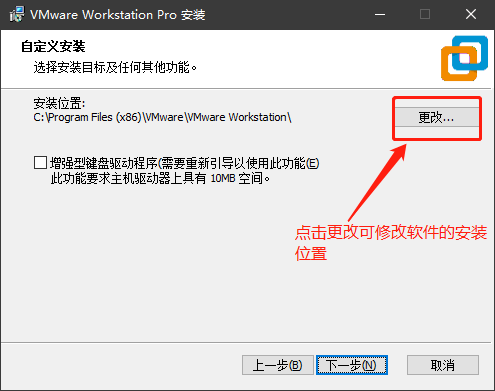
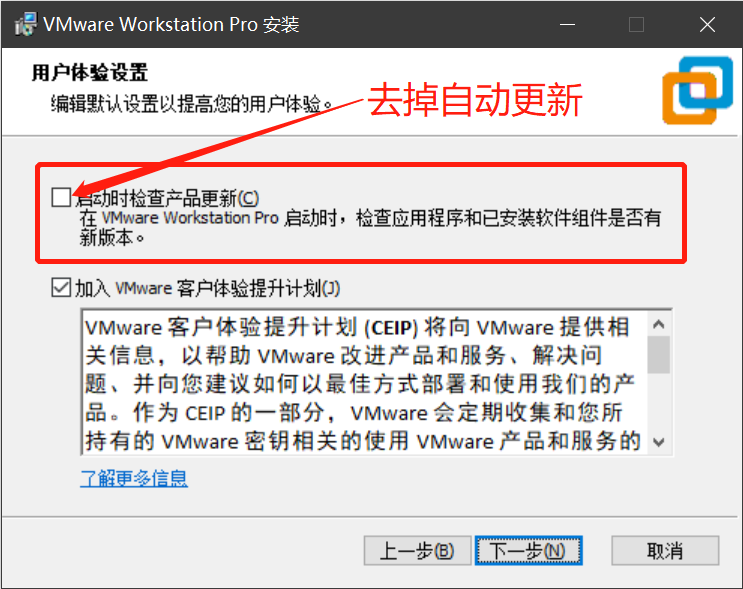
- 在官网下载VMware安装包下载地址
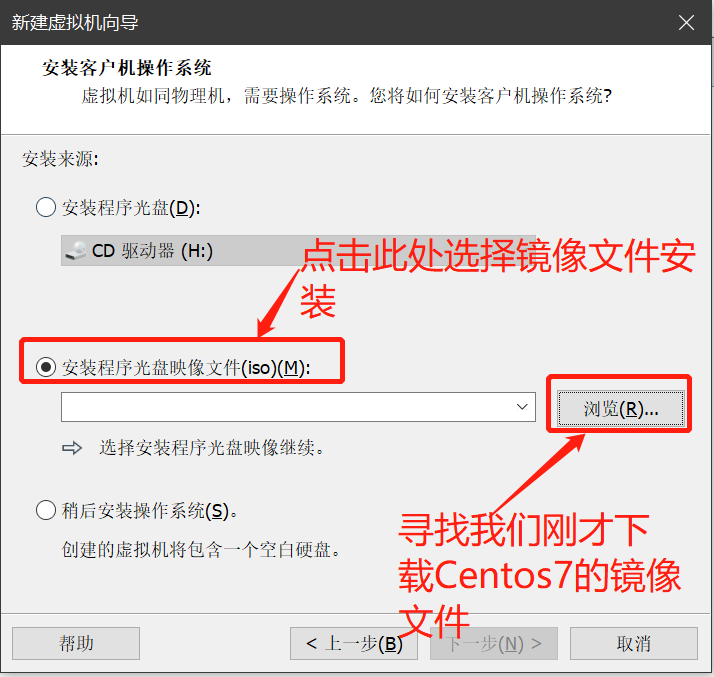
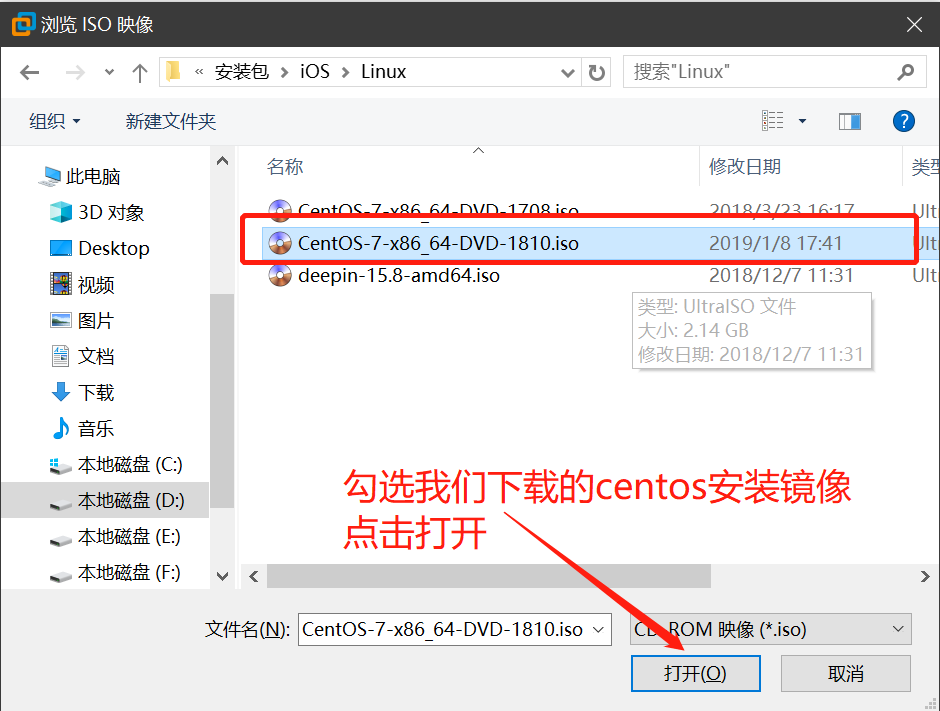
Linux服务器之VMware虚拟机安装Centos7.6
- 下载Centos系统
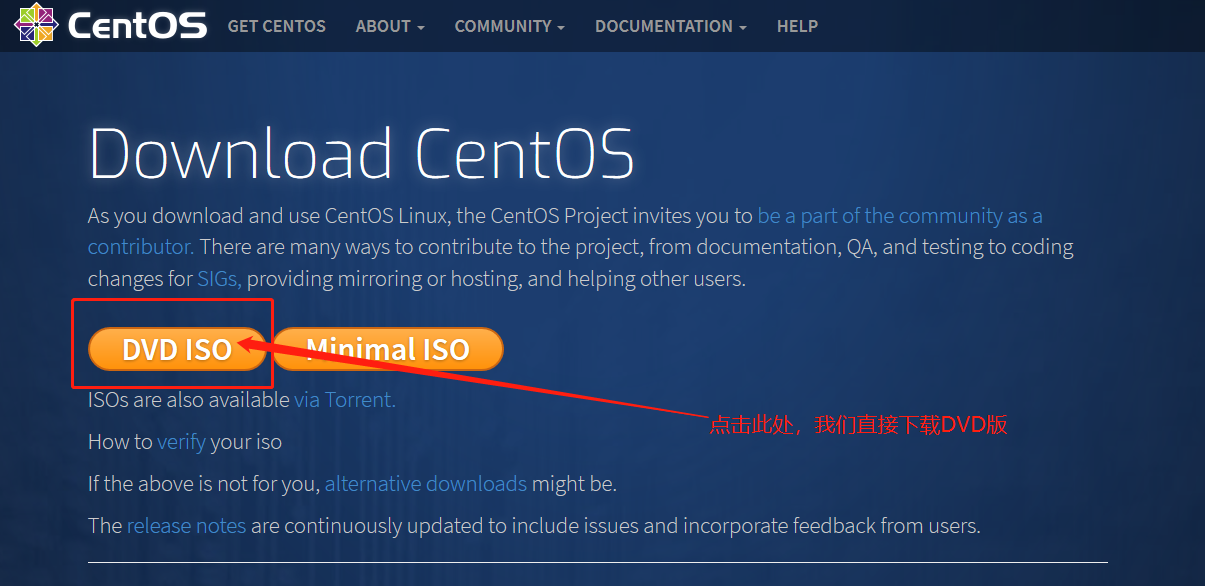
- 打开centos的官网Centos下载地址
- 打开centos的官网Centos下载地址
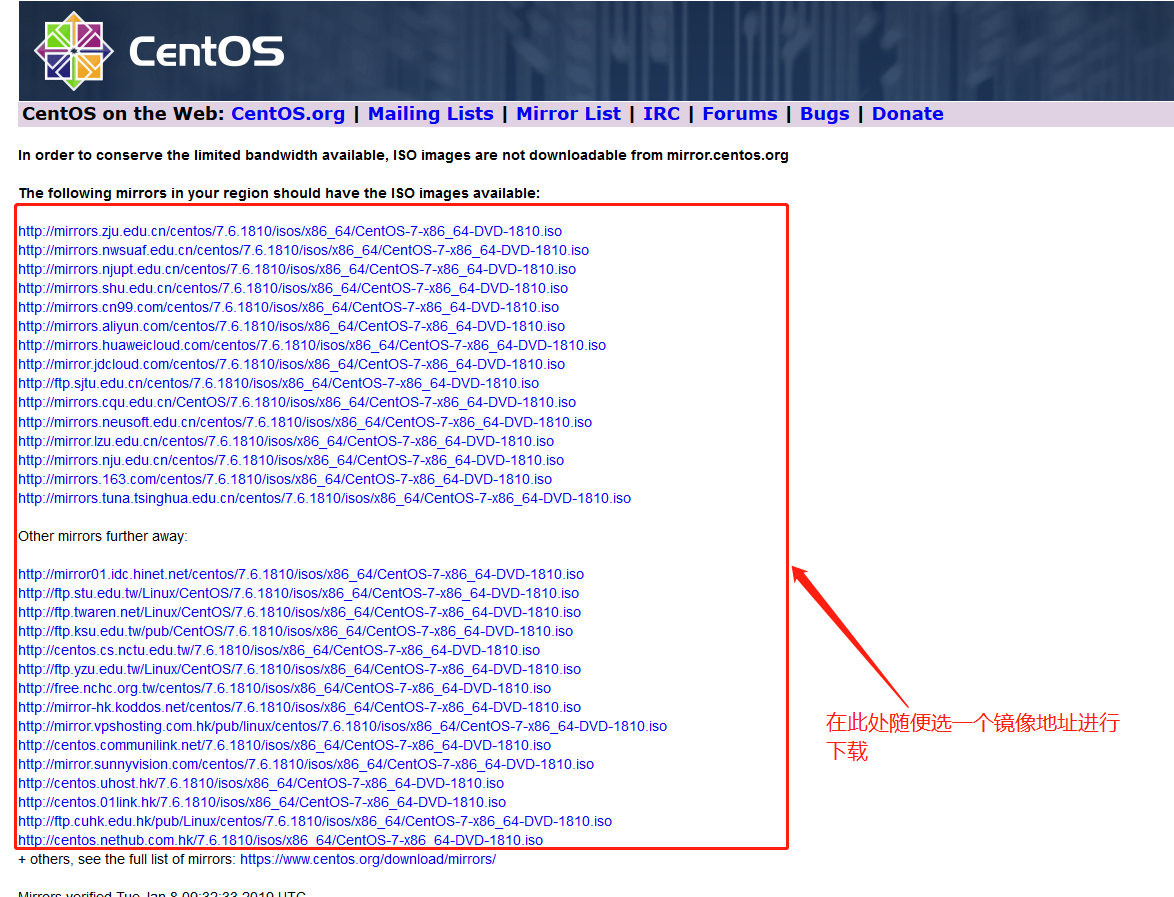
- 如果不想安装最新版的Centos系统,可点击此处进行下载历史版本
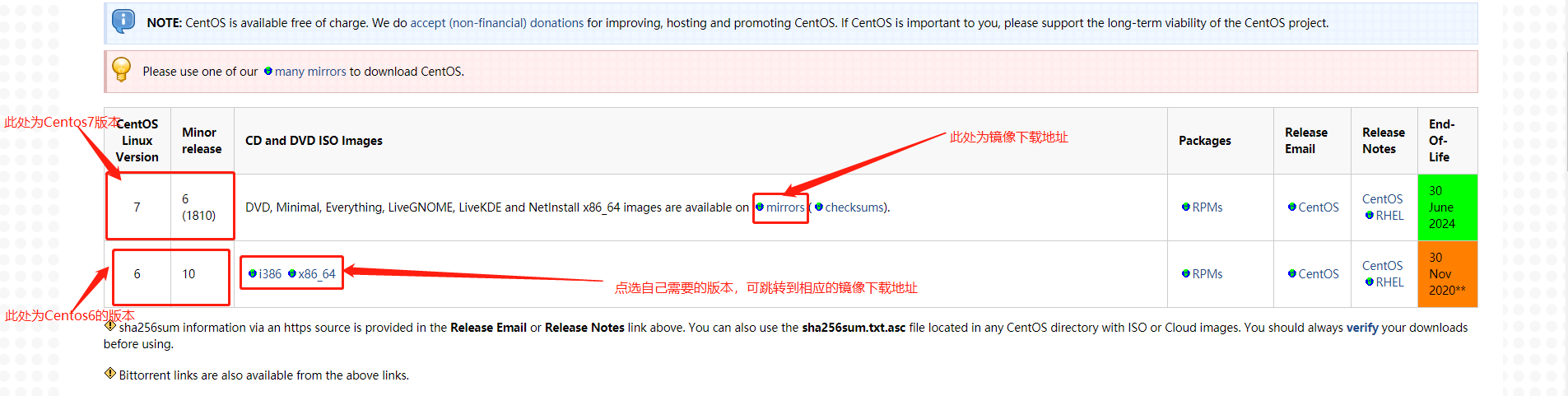
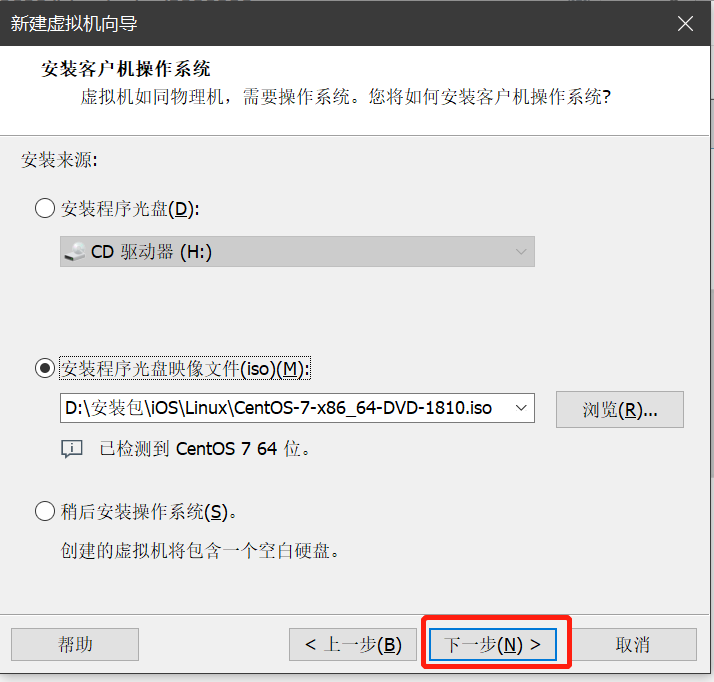
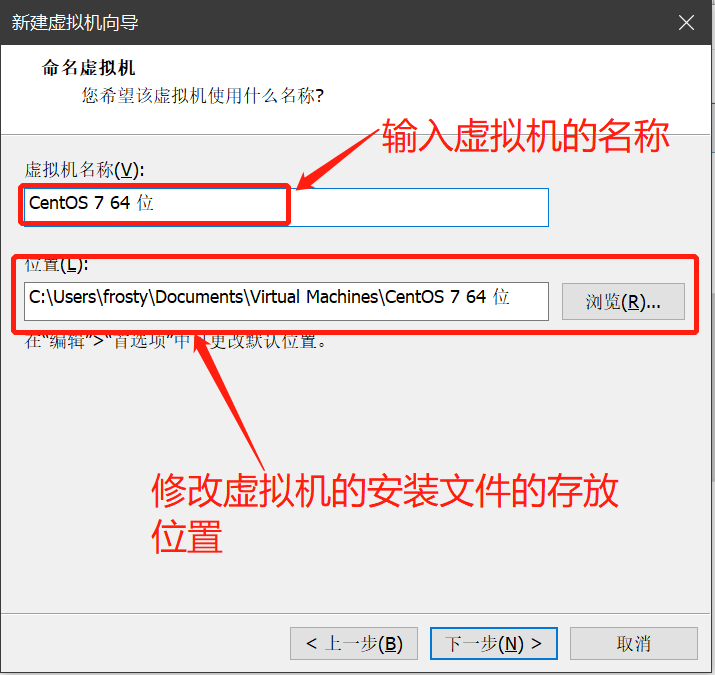
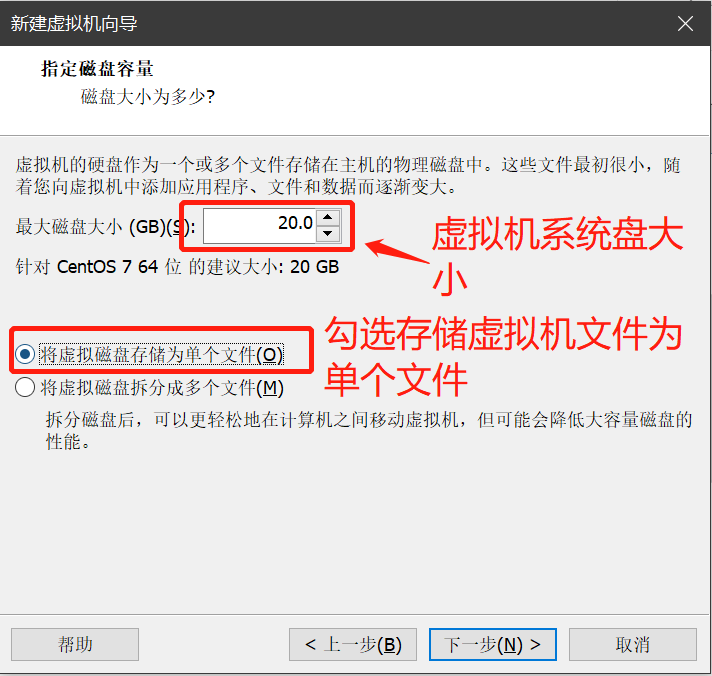
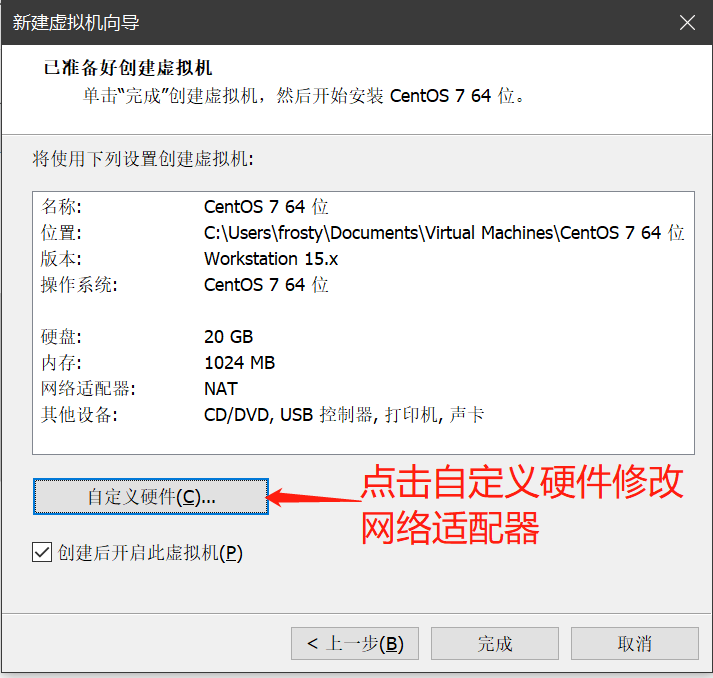
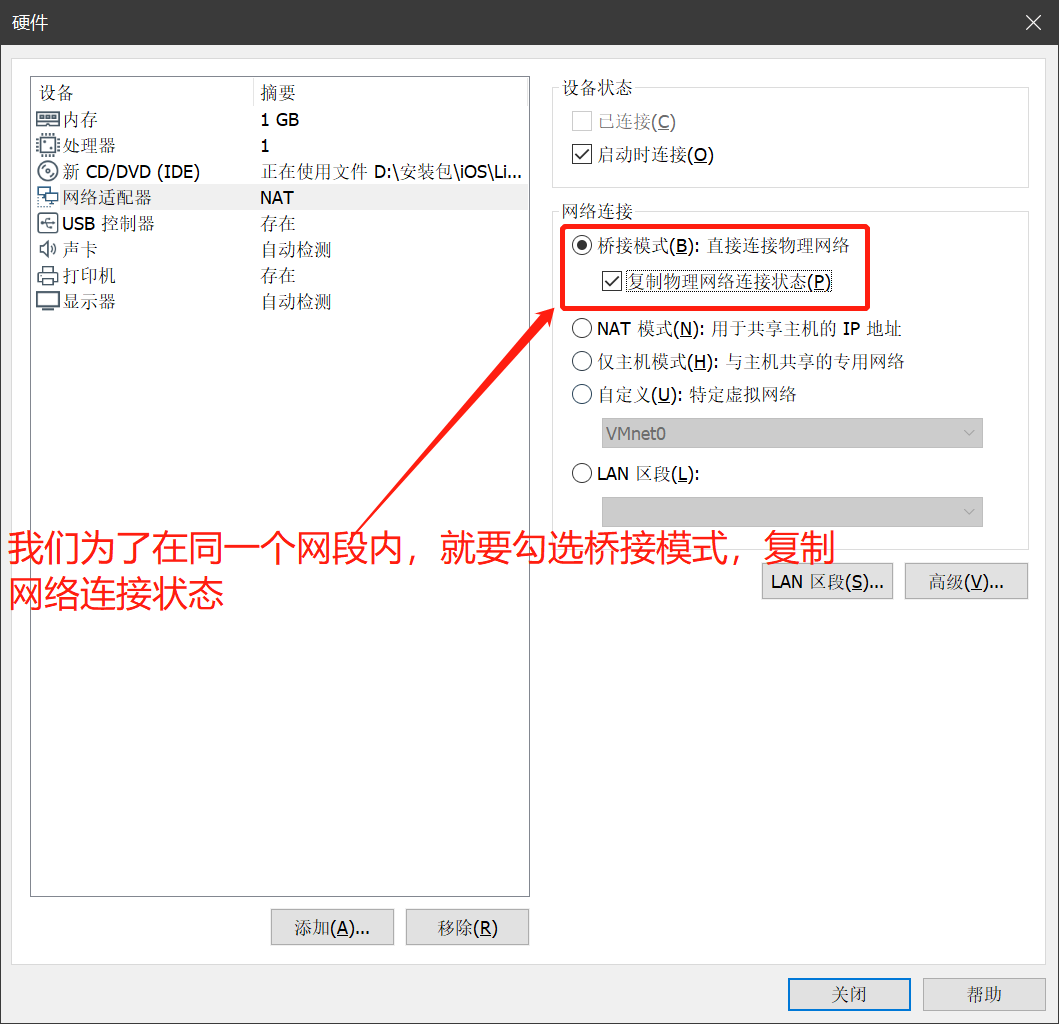
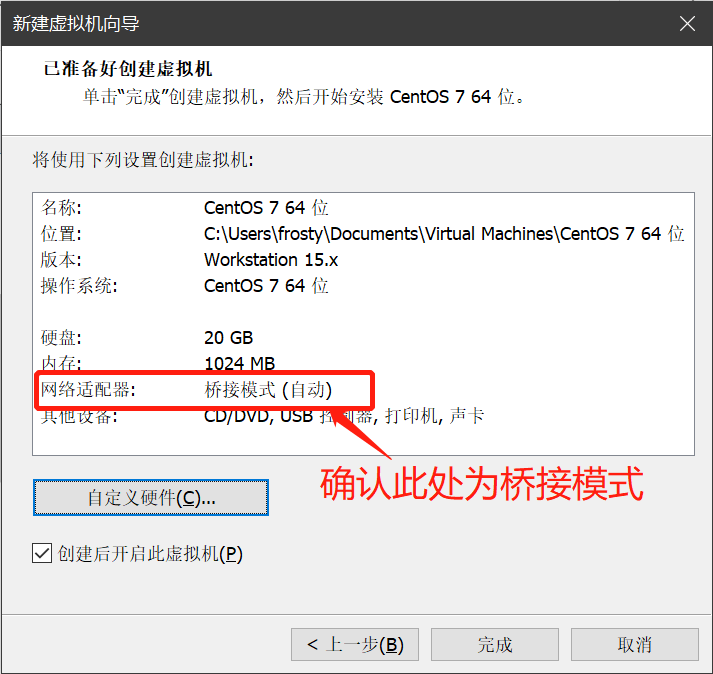
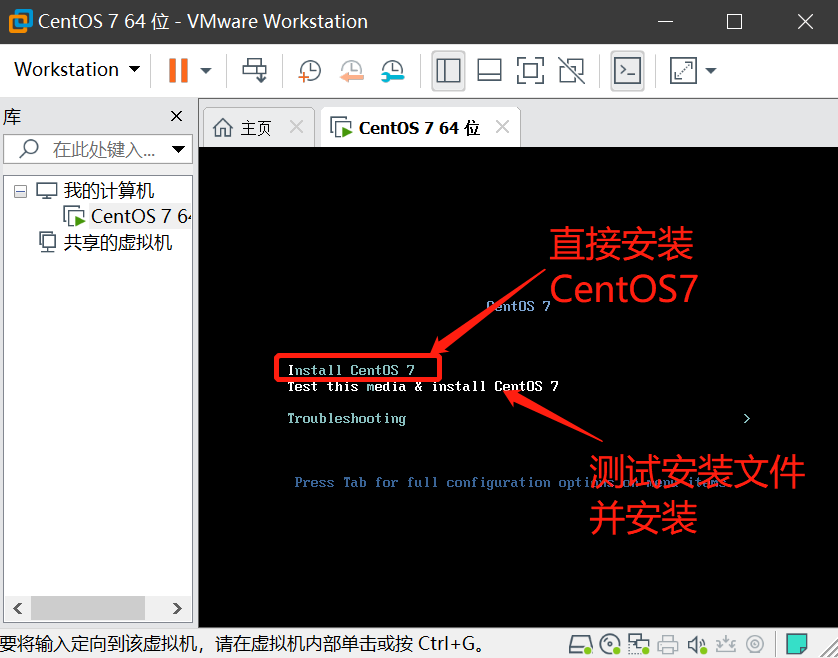
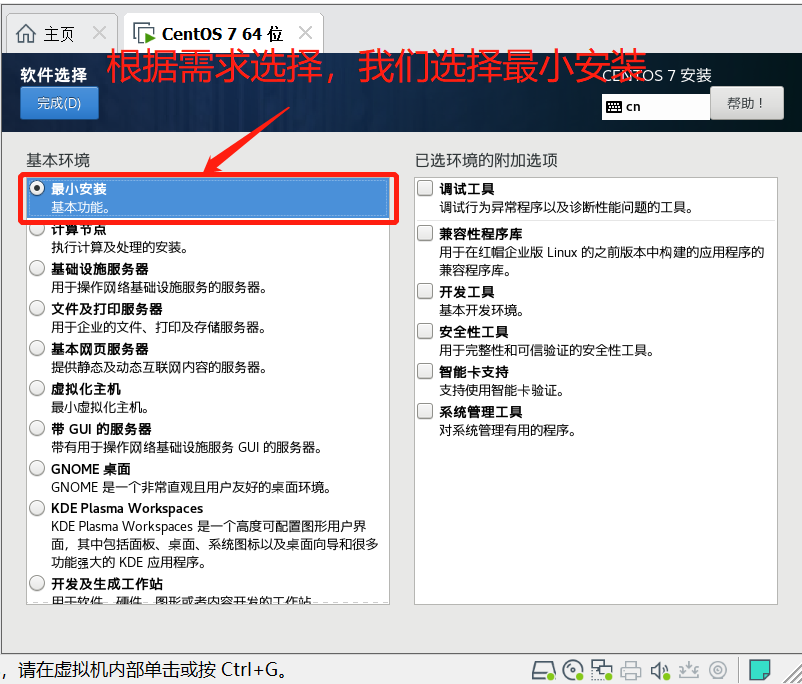
- 鼠标点击窗口处,键盘上键选择install CentOS7直接进行安装,会出现以下安装引导界面
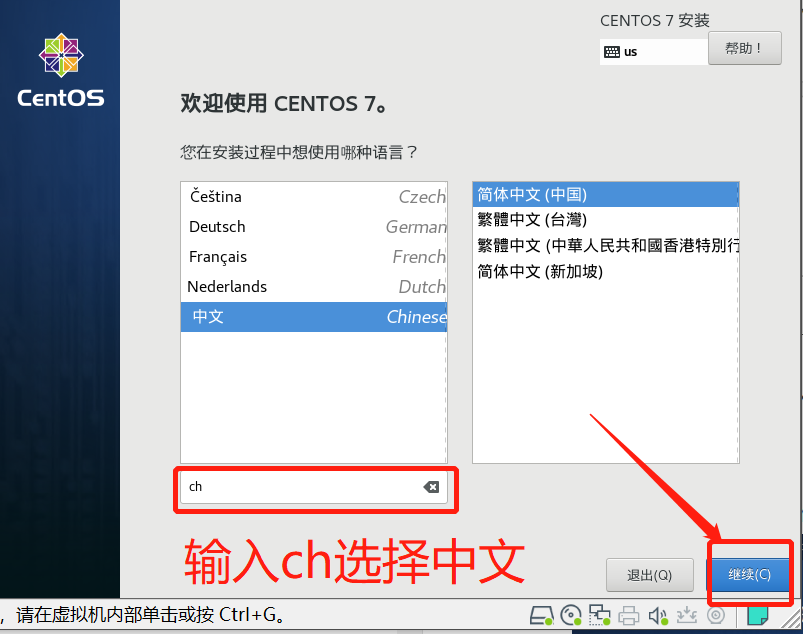
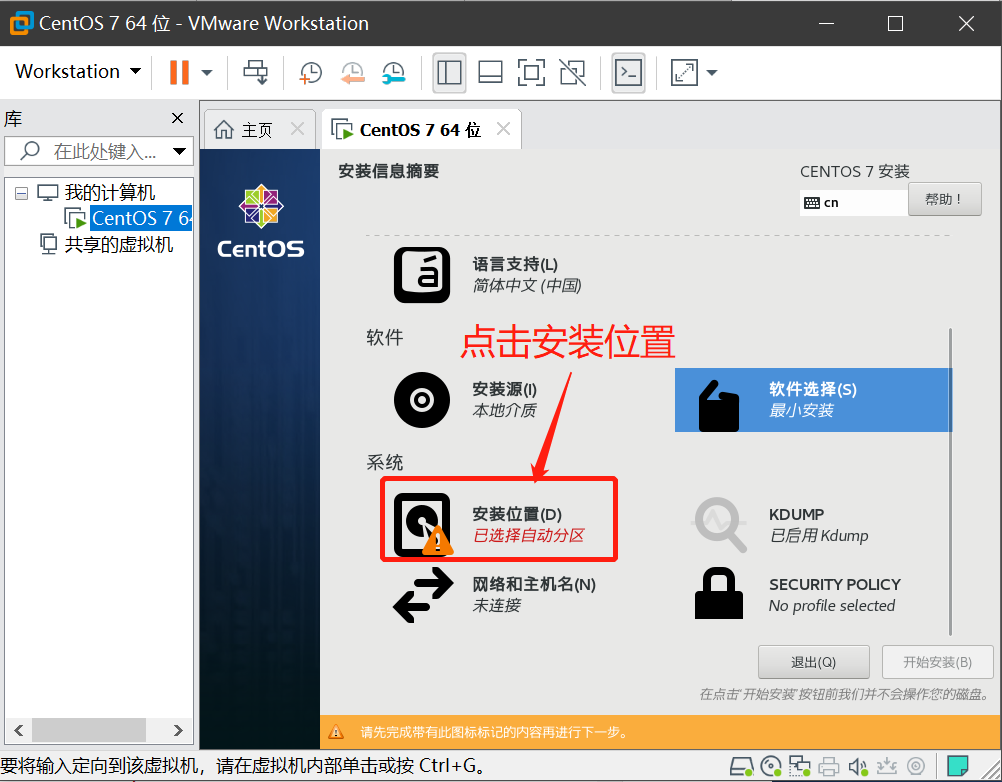
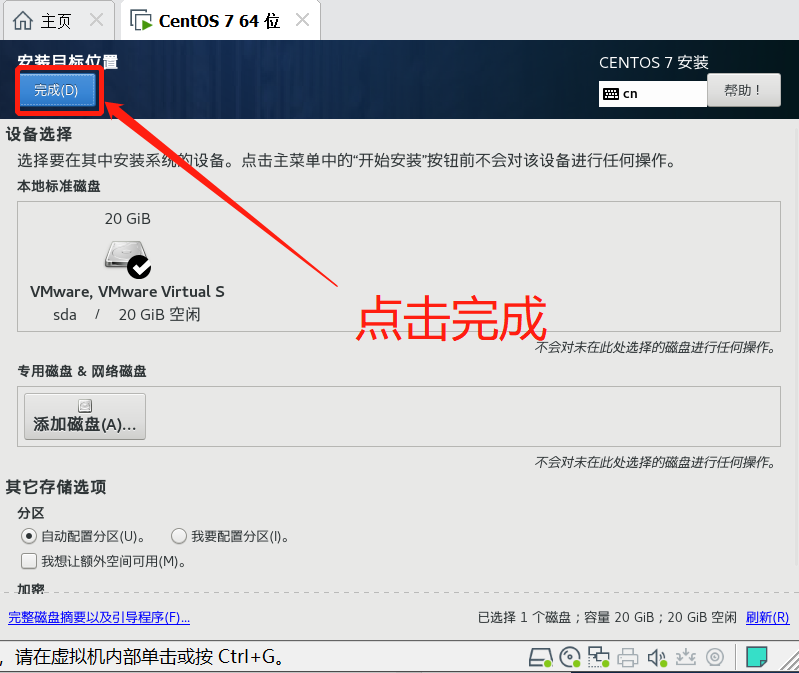
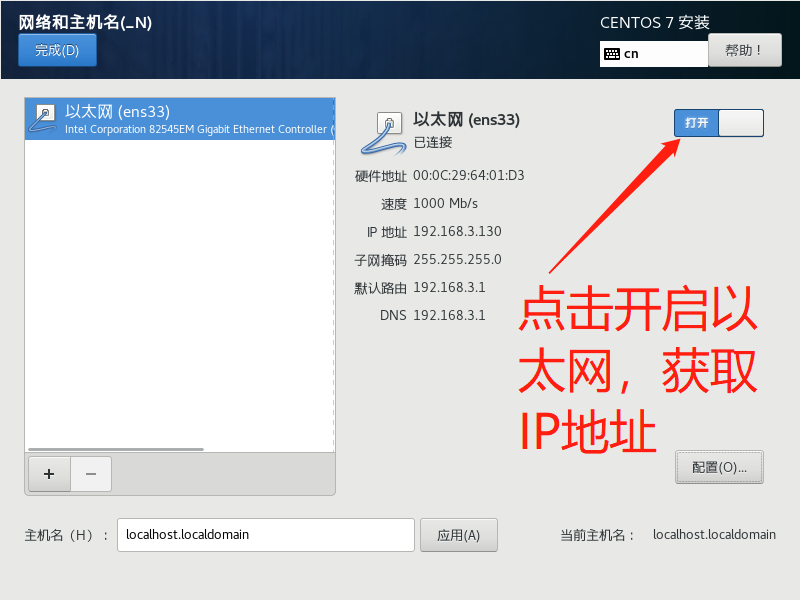
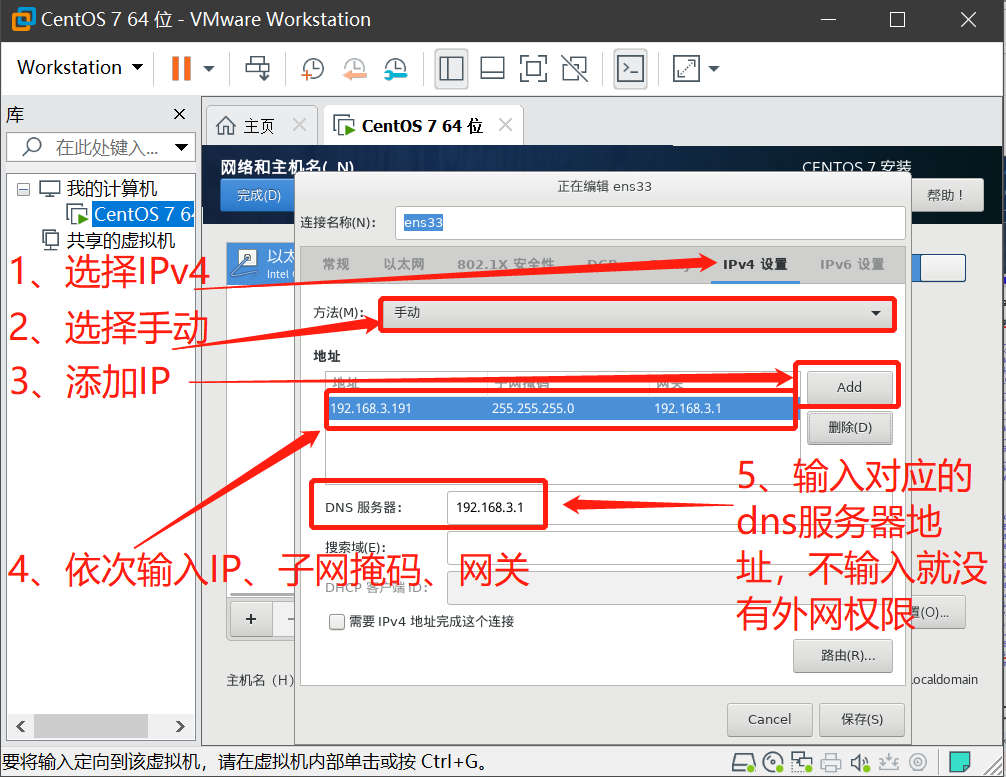
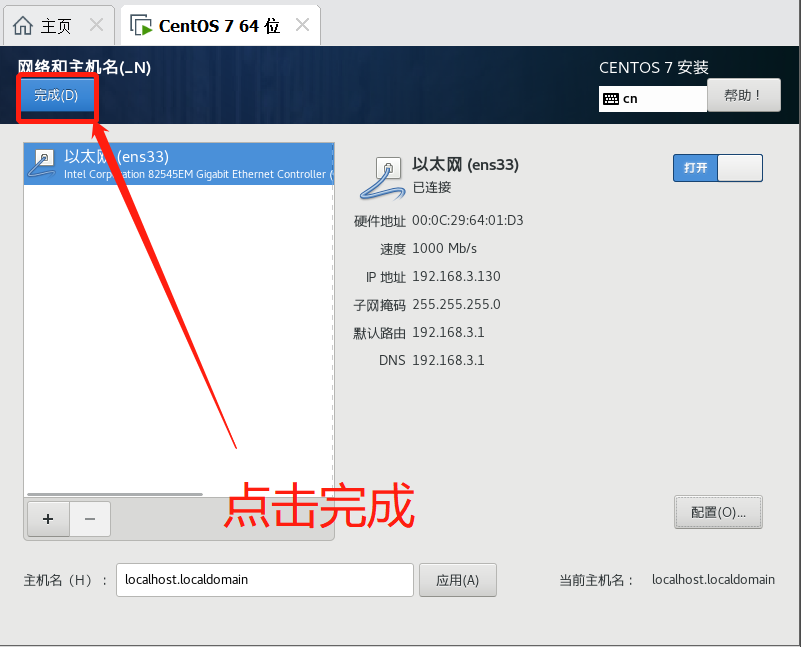
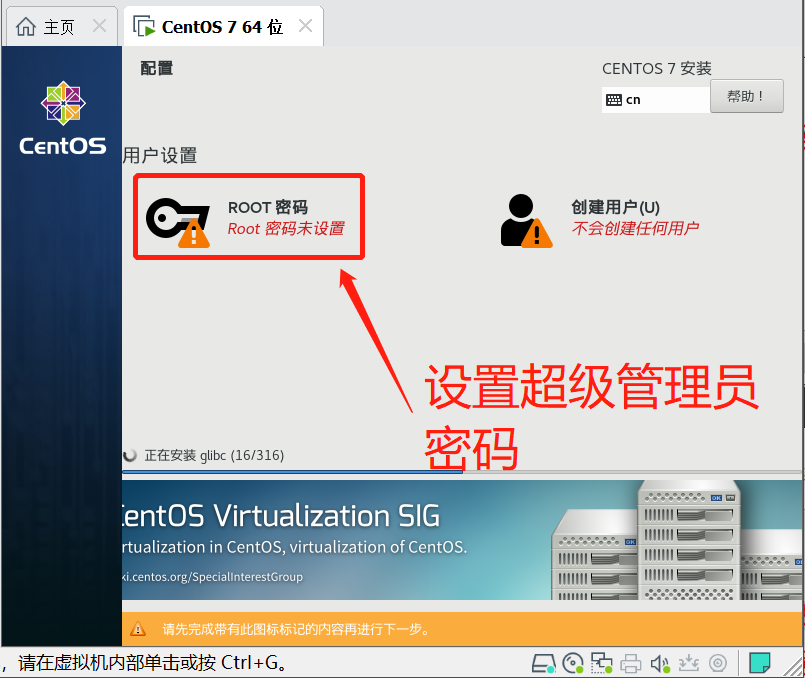
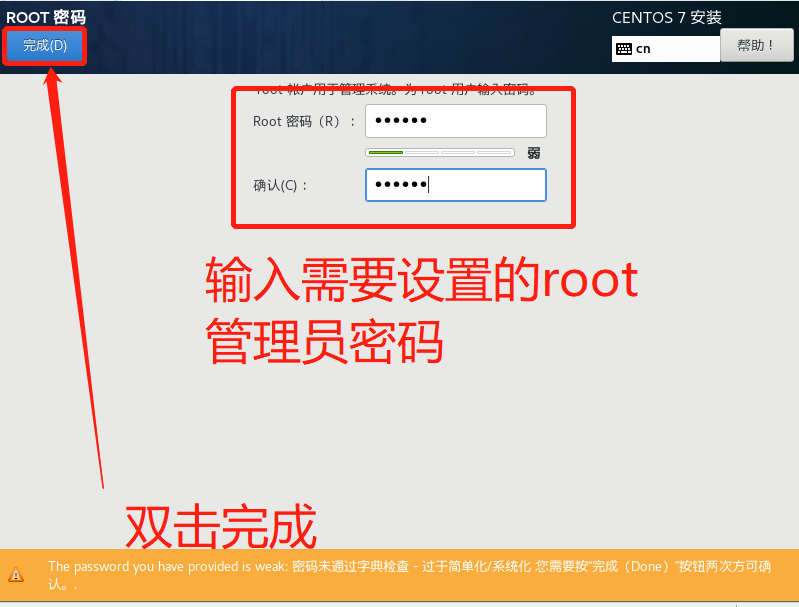
- 等待安装完成,点击重启,至此CentOS就安装完成了。
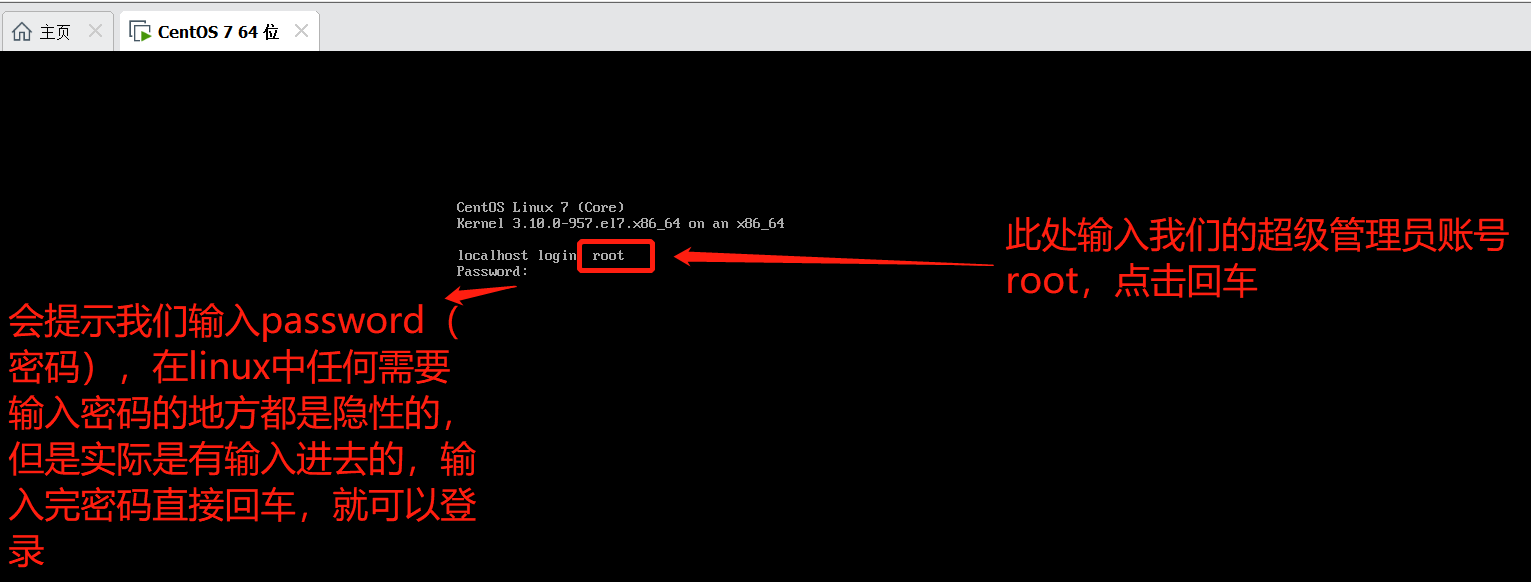
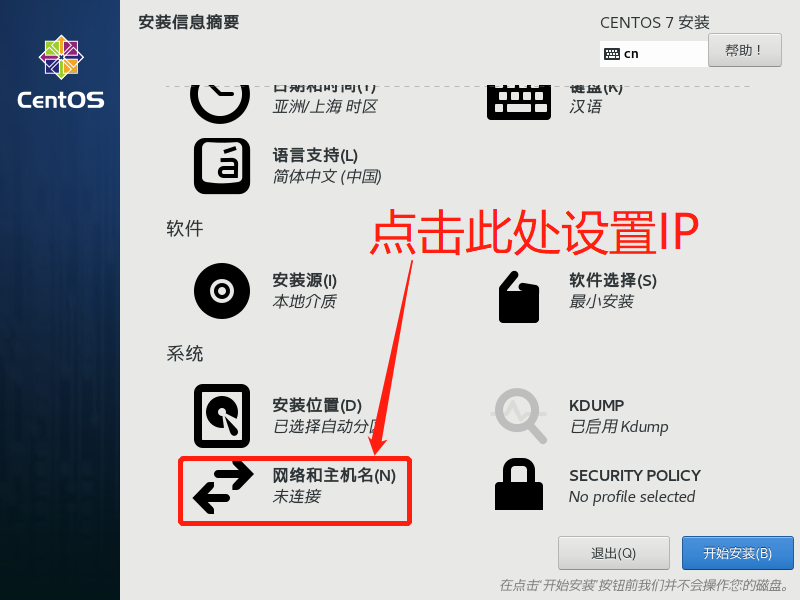
- 使用命令查询linux服务器ip地址 (如果提示找不到命令或not found ,则执行
yum install net-tools安装ifconfig命令)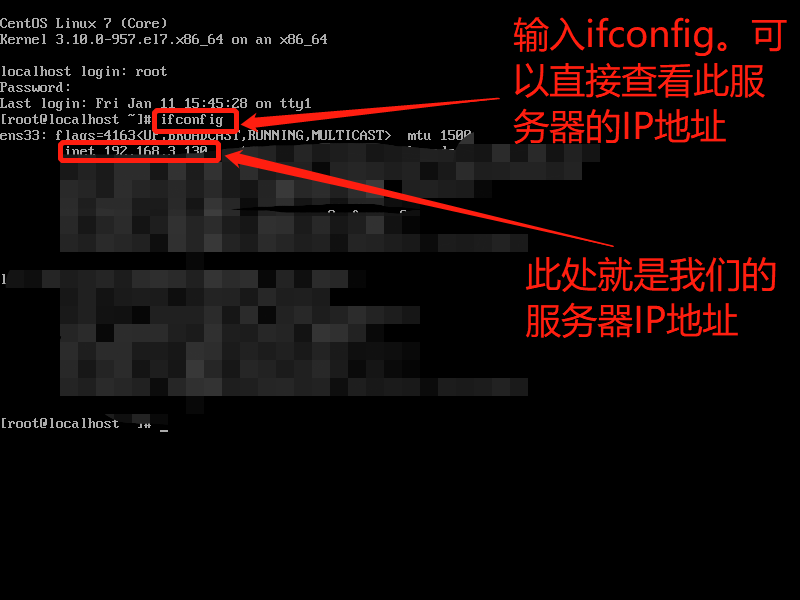
- 使用命令查询linux服务器ip地址 (如果提示找不到命令或not found ,则执行
Linux常见命令学习
使用远程连接工具连接Linux服务器
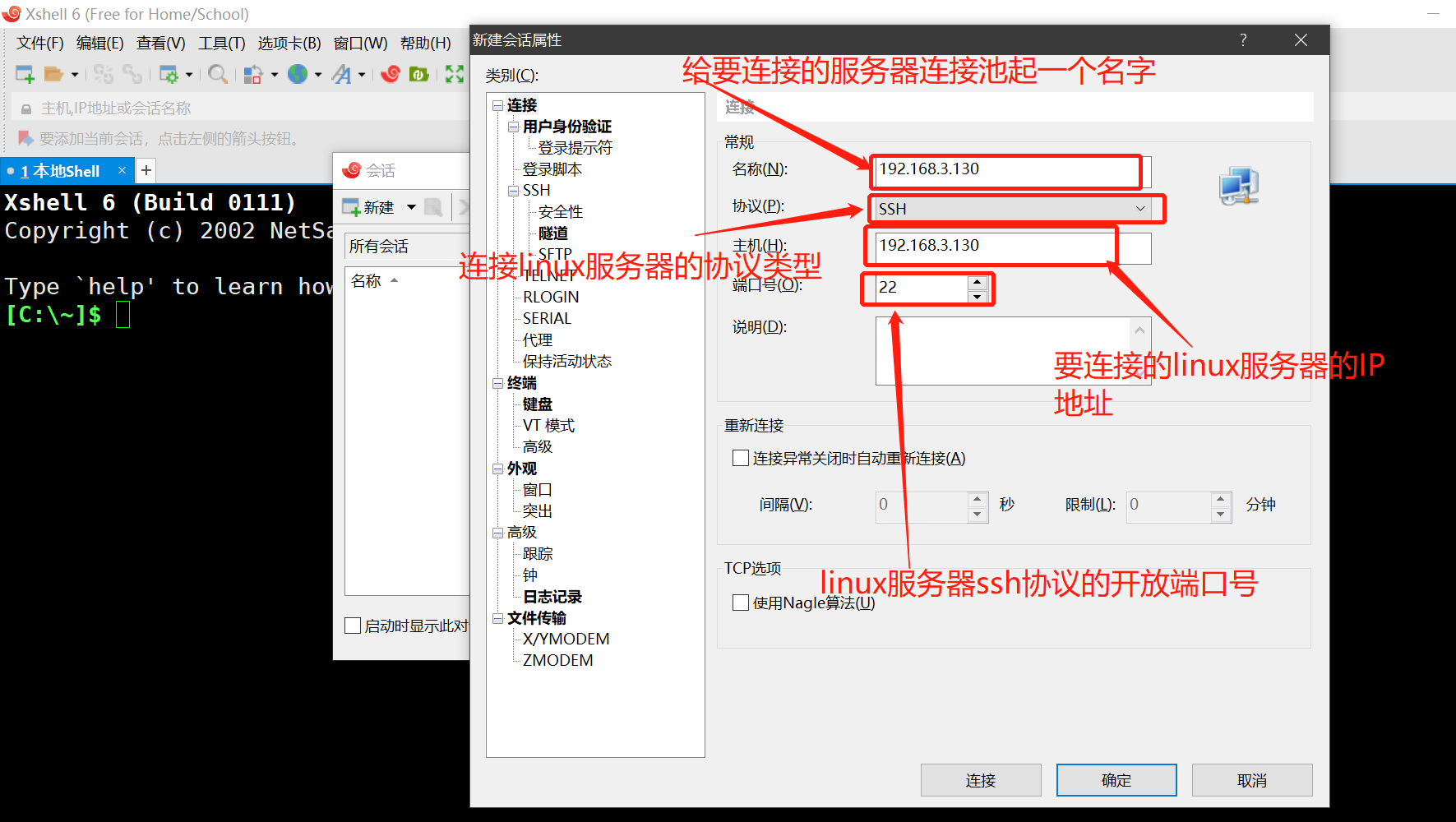
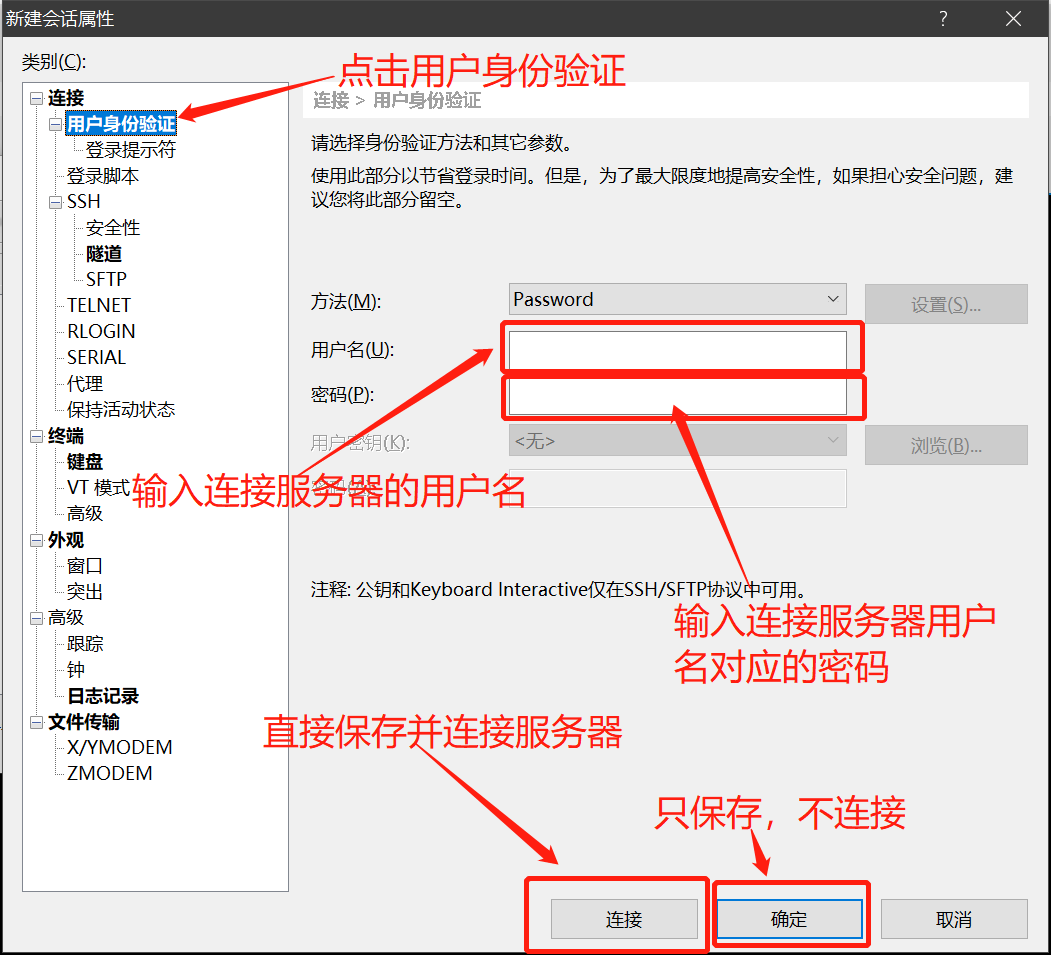
- 连接linux服务器需要的信息
- 1. 服务器的IP地址
- 2. sh协议的端口号
- 3. 服务器的用户名
- 4. 用户名对应的密码 - 连接linux服务器常用的工具:
- 1. xshell
- 2. Windows(Linux、macOS)系统自带的dos窗口(cmd)
- 3. PuTTY
- 4. google浏览器的一些插件也可以连接Linux服务器
- 5. 手机上面的一些APP也可以连接 - 使用xshell连接Linux服务器
- 有两种连接方式
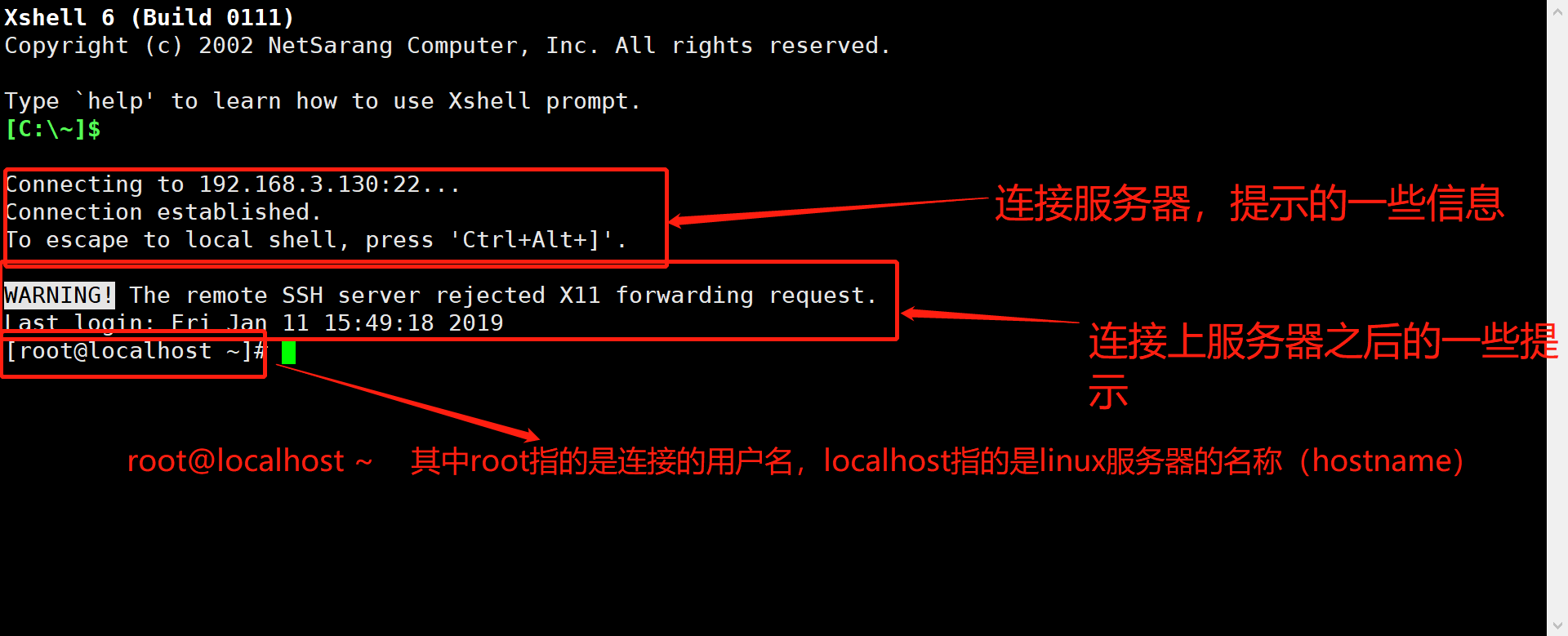
1. 通过xshell去创建快捷连接方式
2. 通过命令行去连接linux服务器
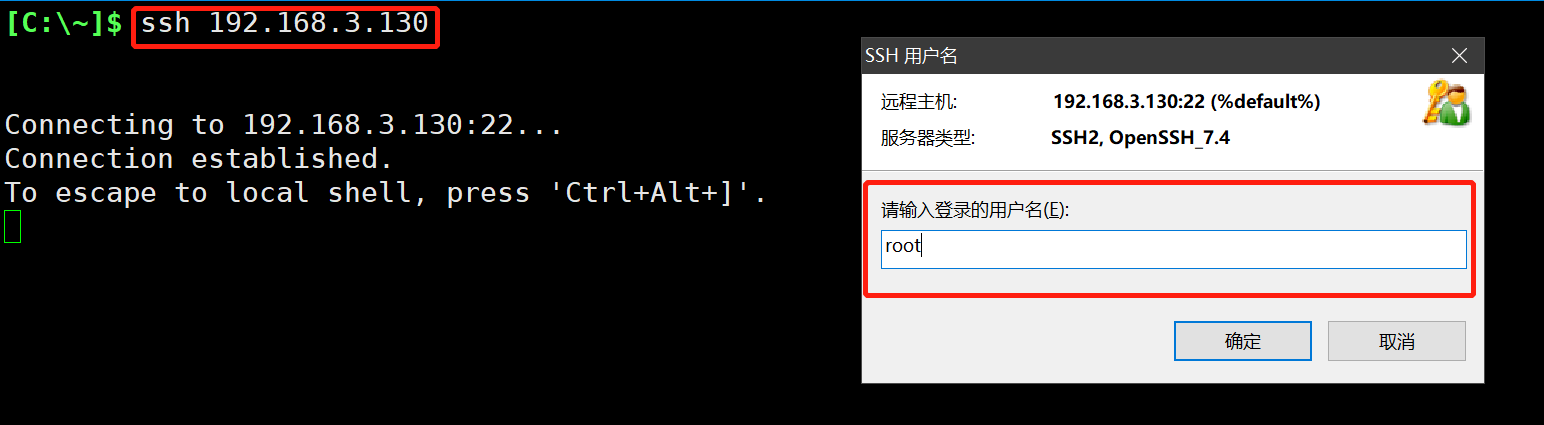
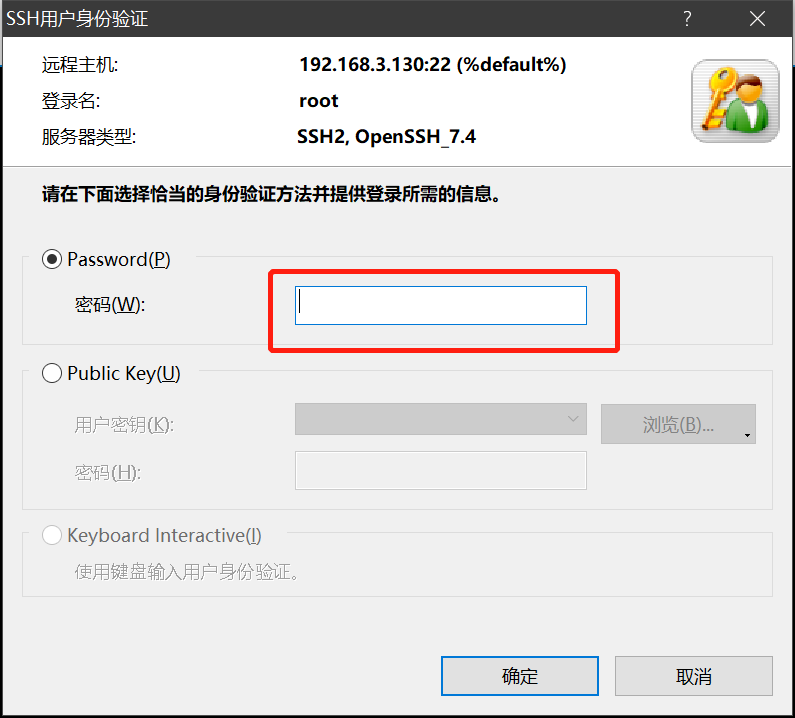
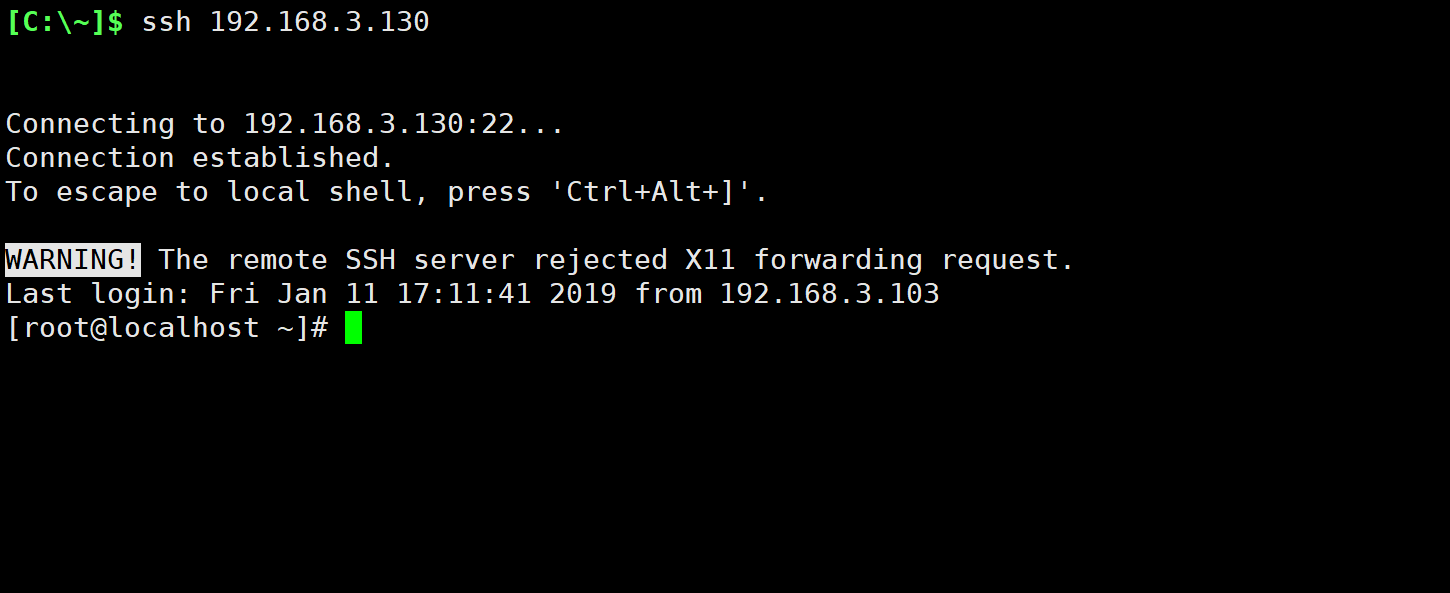
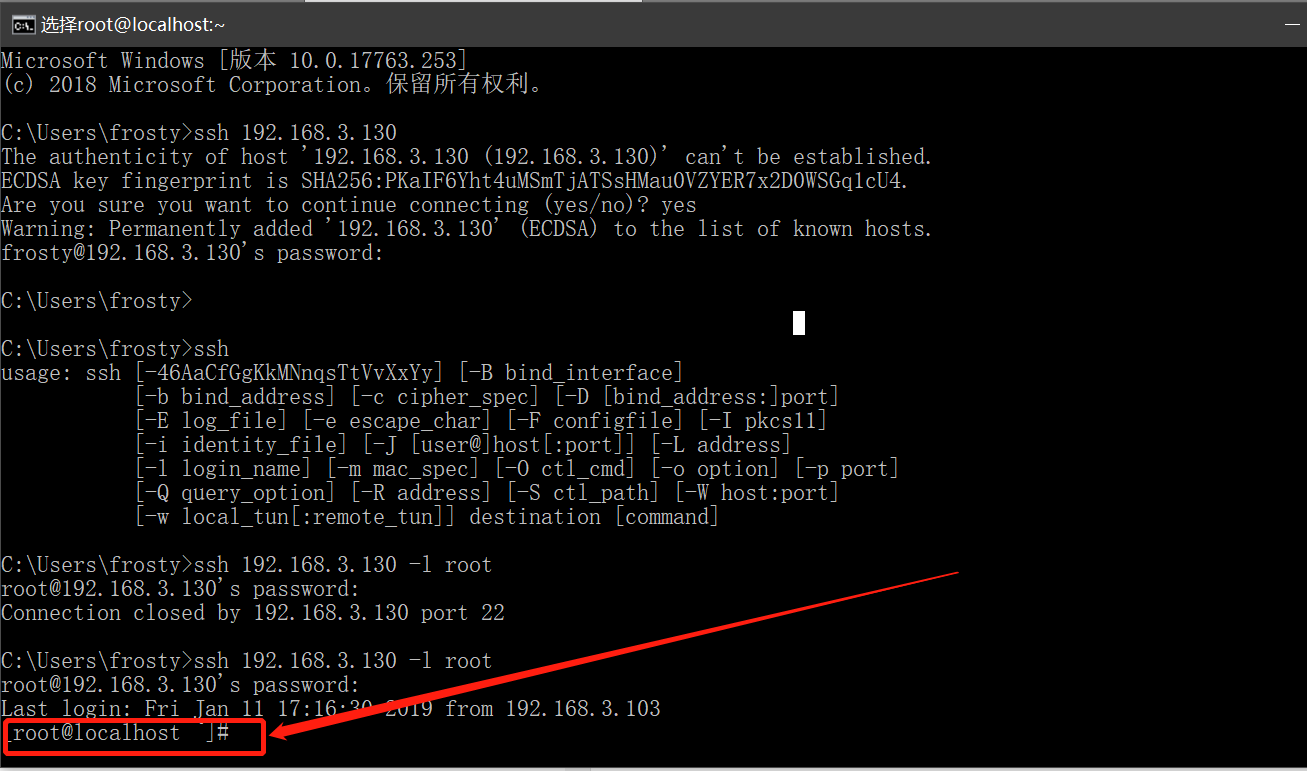
- 通过cmd去连接Linux服务器
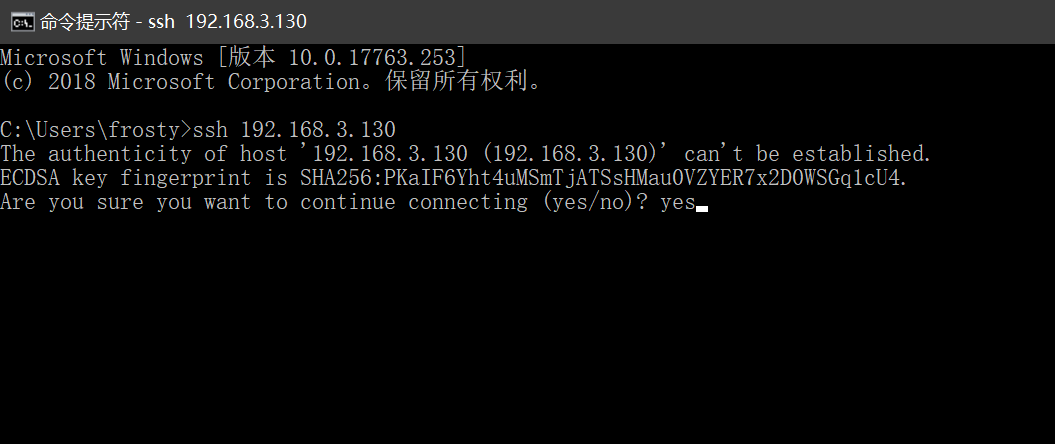
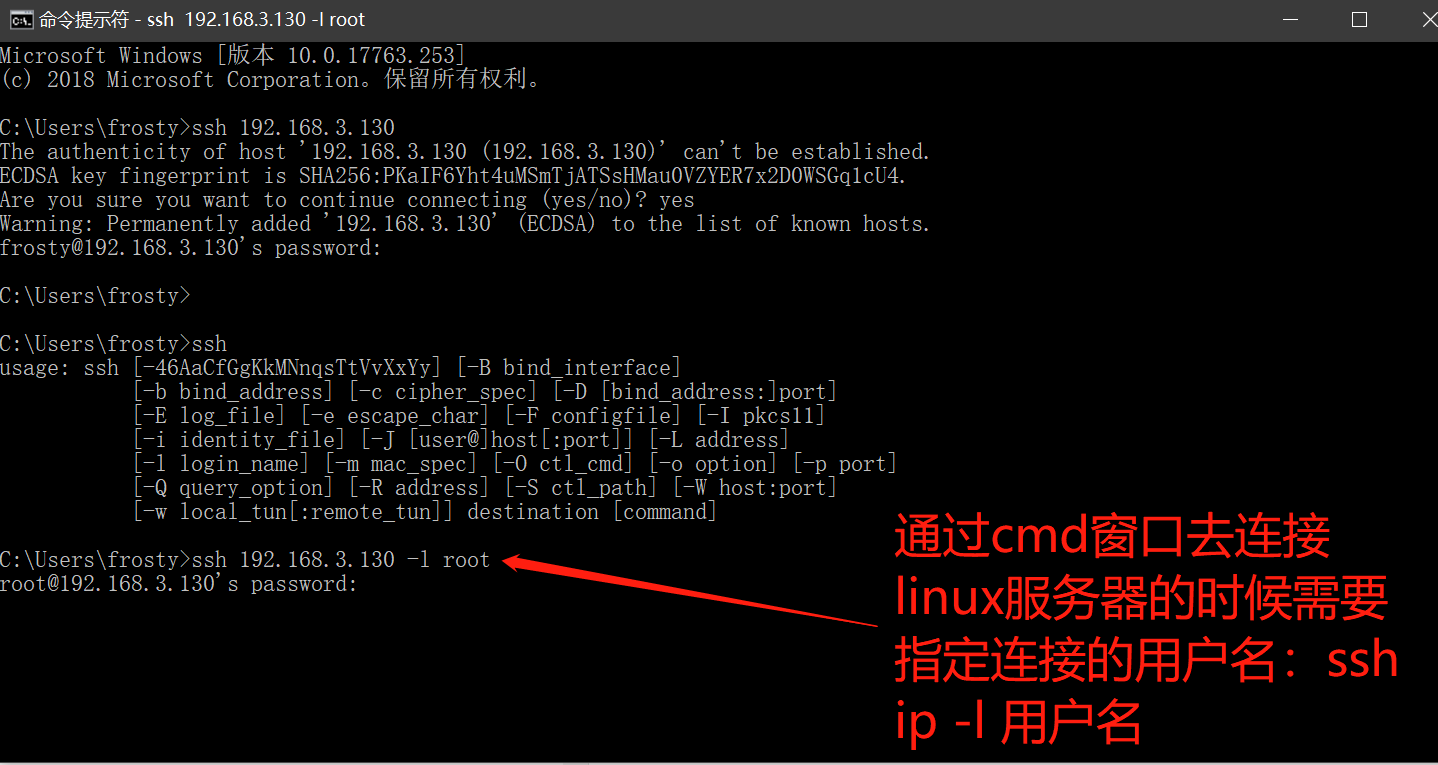
- 设置xshell工具
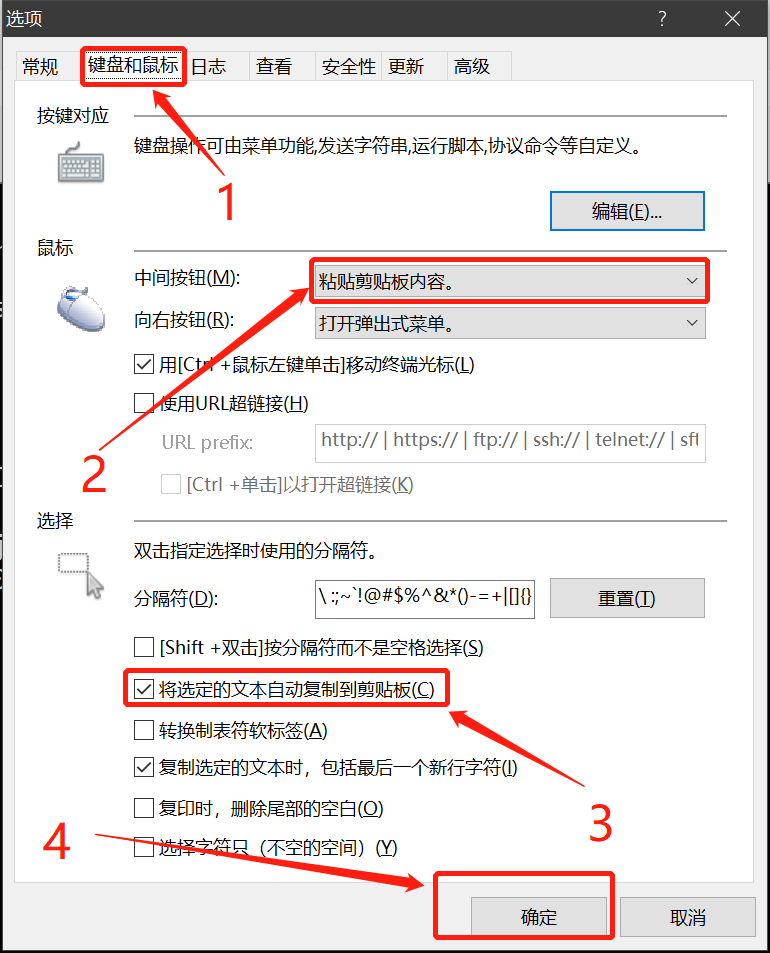
1. 设置复制粘贴快捷键(选中文本就可以自动复制,点击鼠标中间滚轮按钮就可以粘贴复制到的内容)
Linux常用命令
-
[root@localhost~]详解
- 方括弧中的root代表当前连接的用户名
- localhost 指的是所连接的服务器的hostname(具体可以直接使用haostname查询)
- ~ 位置所指的是用户当前所在的目录
- ~ 这个波浪线所指的是当前用户根目录
- home 指的是当前用户所在目录为home
- / 当前系统的根目录
-
cd 切换工作路径
- cd / 切换到当前系统根目录
- cd ~ 切换到当前用户根目录
- cd /home 切换到当前系统根目录下的home目录下(绝对路径)
- cd home 切换到home目录下(从当前工作路径下寻找--相对路径)
- cd .. 返回上一级目录(其实..是一个目录)也可以是用cd ../../返回上两级目录,如果是三个../那就是返回三层
- cd /var/log/chrony/ 切换多层目录
-
pwd 查询当前工作路径(用于展示当前工作的路径)
-
tab键 用于命令提示和补全功能键
-
ctrl + c 快捷键把当前用户前台正在命令窗口运行的一些东西强制停止,返回等待输入的状态
-
df 查询已挂载磁盘使用情况
- df [参数] [文件名]
- 参数:
- -a:all 显示已挂载全部的文件磁盘信息
- -h:以二进制展示已挂载的全部文件的磁盘大小信息
- -H:以十进制展示已挂载的全部文件的磁盘大小信息
- df -h /home 查询的是根目录下home目录的磁盘信息
- df -h 在没有加目录的情况下默认使用根目录
-
磁盘挂载
- 在Linux下磁盘是挂在目录下的
- 在目录下挂载磁盘,linux系统会把此目录下所有的文件存储到挂载的磁盘中
-
cp 复制
- cp [源] [目标] 复制文件,从源复制某个文件或者文件夹到目标
- cp -r abc webserver/bcd 详解:-r 对文件夹操作,把abc文件夹复制到webserver下并且重命名为bcd
- cp 111.txt ../ 详解:把111.txt文件复制到上一层目录,如果不强制指定文件名称,则使用源文件名称
- cp 111.txt ../222.txt 详解:把111.txt文件复制到上一层,且重命名为222.txt
- 备份:cp 源文件 源文件名称.20190115001.bak
- 恢复:mv 源文件名称.20190115001.bak 源文件名称
- scp [源] [目标] 从网络中别的服务器复制文件(跨服务器复制)
- scp -r 登陆此服务器的用户名@ip:/home/abc /home/
- scp -r root@192.168.3.130:/home/abc /home/
- cp [源] [目标] 复制文件,从源复制某个文件或者文件夹到目标
-
mv 剪切
- mv [源] [目标]
- mv 111.txt ../ 详解:把111.txt文件剪切到上一层目录,如果不强制指定文件名称,则使用源文件名称
- mv 111.txt ../222.txt 详解:把111.txt文件剪切到上一层,且重命名为222.txt
- mv 111.txt 222.txt 详解:可以直接当成重命名(剪切此文件,并重命名为222.txt 到当前目录下)
- mv [源] [目标]
-
删除
- rm [文件或者文件夹]
- rm 文件名称 :带提示符的删除文件
- rm -r 文件夹:带提示符对文件夹的删除操作
- rm -rf 文件或者文件夹:对文件或者文件夹的操作,不带提示符,直接删除
- rm [文件或者文件夹]
-
新建
- mkdir 新建目录
- mkdir abc :在当前目录创建一个叫abc的目录
- mkdir /home/abc/bcd :在系统根目录的home下的abc目录下创建一个叫bcd的目录(必须保证上层目录是已经存在的)
- mkdir -p abc/1/2/3/4/5/6/7/8/9/0 :创建多层空目录
- 新建文件
- touch 创建文本文件
- touch 111.txt 创建一个111.txt的空文本文件
- vi、vim
- vi或者vim命令可以用于创建文件,但前提是必须对文件进行编辑且要不是空文件的时候才可以创建
- touch 创建文本文件
- mkdir 新建目录
-
vi 修改
- vi、vim(如果没有此命令则执行yum install vim -y 进行安装)
- a 光标后退一格进行编辑
- i 光标原地不动编辑
- o 光标换行编辑
- insert 就是i的缩写
- esc键退出当前可编辑状态
- 在未编辑状态下:
-
:q 退出vi或者vim命令(前提是文件未被修改,如果修改,则会报错)
-
:q! 不保存强制退出vi命令
-
:wq 保存且退出
#!/usr/bin/env bash echo "我爱学习,学习使我快乐!" echo "我爱工作,工作使我快乐!"
-
- vi、vim(如果没有此命令则执行yum install vim -y 进行安装)
-
find [查找的目录] [参数] [参数值]查找(只列出常用的-name参数,其他参数可自行百度linux下find命令详解)
- 精确查找:find / -name 111.txt
- 模糊匹配:find / -name *.txt
- 模糊匹配:find /home/ -name 1*.*
-
上传、下载(rz、sz)
- 首先要安装一个上传下载的命令:yum install lrzsz -y
- 上传:rz(只可以上传文件,不可以上传文件夹)
- 下载:sz [需要下载的文件名称]
-
解压
- zip、tar.gz(linux中特有的压缩文件)
- 需要安装解压命令:yum install unzip -y
- unzip 压缩包名称
- tar.gz包解压:tar -zxvf 需要解压的文件名称
- tar.gz包压缩:tar -zcvf 压缩后的文件名称.tar.gz 源文件或者目录
- tar包解压:tar -xvf 需要解压的tar包名称
- tar包压缩:tar -cvf 压缩后的文件名称.tar 源文件或者目录
- zip、tar.gz(linux中特有的压缩文件)
-
安装
- yum
- yum install [需要安装的软件名称] [-y表示无需提示用户,直接确认]
- rpm
- 安装:rpm -ivh [需要安装的安装包](需是rpm后缀的安装包)
- 卸载:rpm -e --nodeps [已安装软件名称1 已安装软件名称2...]
- 查找:rpm -qa | grep lrzsz* 查询到已安装的所有lrzsz开头的安装包
- yum
-
pwd 查询当前路径
-
ll 列出当前路径下所有文件和文件夹的详细列表
- ll [需要列出的目录,如没有则默认当前工作路径] [参数]
- ll /home -a(a指展示所有文件包括隐藏文件)
-
ls 列出当前路径下所有文件和文件夹
- 同上ll命令
- ls -l命令等同于ll 文件或者文件夹前加 . 可以隐藏此文件或者文件夹
-
权限解析(一共10个):drwxrwxrwx,第一个字母为单独的,剩下9个字母每三个一组代表各自权限
- 第一个字母:
- d 代表目录
- - 代表的是文件
- l 代表的是连接
- 第一组的三个代表的是所有者的权限
- 第二组代表的是所有者所在组的组成员的权限
- 第三组代表的是除所有者和所有者所在组的其他用户的权限
- rwx所代表的意义:
- r read缩写:可读权限 赋权操作中用4代表
- w write缩写:可写权限 赋权操作中用2代表
- x 可执行权限 赋权操作中用1代表
- - 没有此权限 赋权操作中用0代表
- 赋权:
- 修改文件权限
- chmod -R 755 文件或者路径
- chmod -R +x 文件或者目录
- chmod -R -x 文件或者目录
- 修改文件所有者和所在组
- chown -R 用户名称:组名称 文件或者路径
- chown -R 用户名称 文件或者路径
- chgrp -R 组名称 文件或者路径
- 修改文件权限
- 第一个字母:
-
系统目录详解
- bin 存放的是可执行文件(命令)
- etc 存放linux中所有的系统配置文件
- home 所有用户目录存放地
- lib 依赖的包
- opt 软件安装目录
- sbin 可执行文件(命令)
- usr 用户信息
-
JDK安装配置
-
上传JDK安装包
jdk-8u102-linux-x64.tar.gz到/opt/目录下 -
使用
tar -zxvf jdk-8u102-linux-x64.tar.gz -
执行
rm -rf jdk-8u102-linux-x64.tar.gz删除源安装包 -
执行
vi /etc/profile打开linux环境变量文件 -
在最后增加以下内容:
# jdk环境变量 export JAVA_HOME=/opt/jdk1.8.0_102 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar -
执行
source /etc/profile命令重新加载环境变量文件,使刚才配置的jdk环境变量生效 执行java -version验证环境变量是否配置成功
-
-
tomcat配置安装
- 执行rz命令上传
apache-tomcat-8.0.53.zip到/opt目录下 unzip apache-tomcat-8.0.53.zip解压tomcat到当前目录- 执行
cd apache-tomcat-8.0.53进入tomcat根目录 - 执行
cd bin/进入tomcat的bin目录 - 执行
chmod +x *.sh对所有.sh文件进行授可执行权限
- 修改tomcat端口号
- 在tomcat的根目录执行vim conf/server.xml
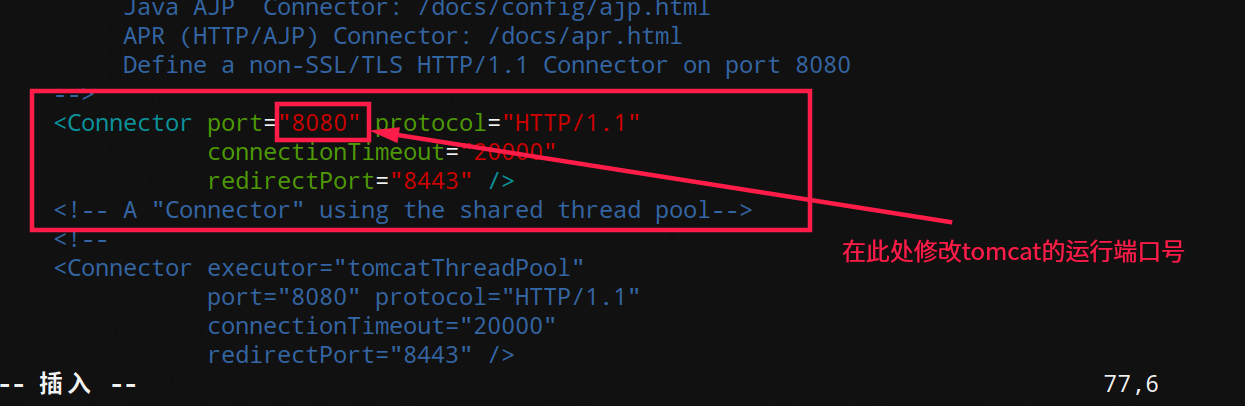
- 修改完成之后按esc然后按:wq退出编辑状态并保存
- 上传软件包到tomcat根目录下的webapps中
- 在bin目录下执行./startup.sh启动tomcat
- 在tomcat的根目录执行vim conf/server.xml
- 执行rz命令上传
-
tomcat目录详解
- bin 放的是tomcat的可执行文件(包含咱们常用的启动,停止)
- conf 存放的是tomcat的配置文件
- lib 存放tomcat的一些基础依赖包
- logs 存放tomcat日志,包含项目日志、tomcat运行日志
- temp 存放的是tomcat下的一些文件备份
- webapps 存放Java软件包的目录(常见的软件包以.war,例如:ThreeNewBoard.war)
- work 工作空间
-
CentOS7关闭防火墙
- 执行
systemctl status firewalld.service检查服务器防火墙状态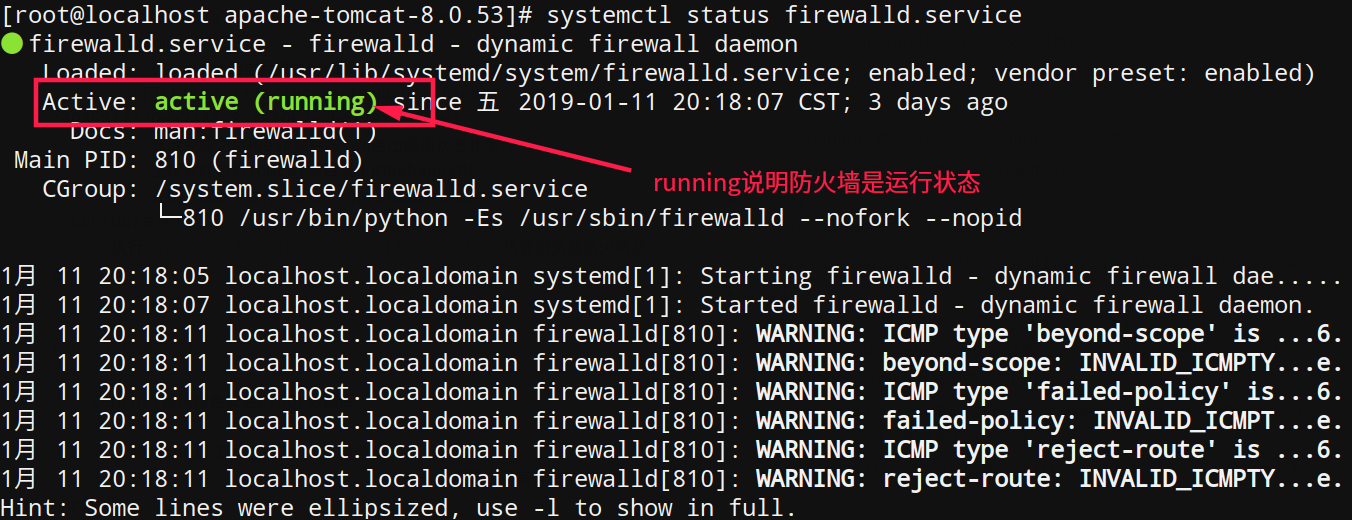
- 执行
systemctl stop firewalld.service关闭防火墙 在执行
在执行systemctl status firewalld.service检查服务器防火墙状态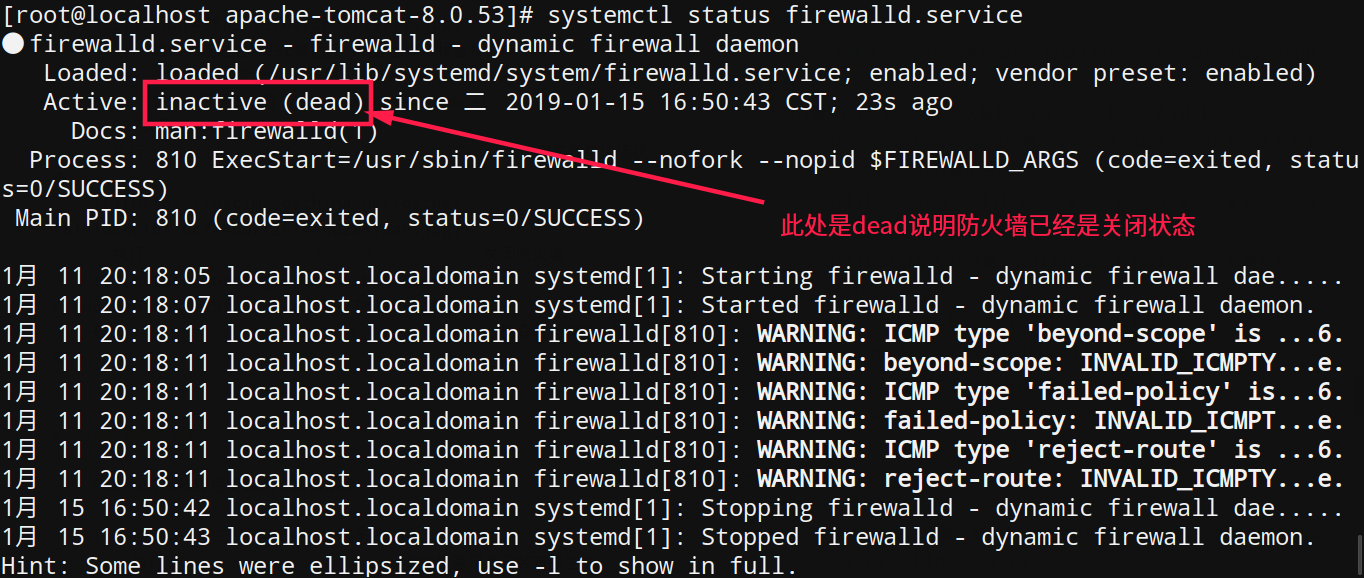
- 执行
systemctl disable firewalld.service禁止防火墙开机启动
- 至此CentOS防火墙关闭完成
- 执行
-
查看端口号
netstat -anp查看运行的端口号netstat -anp | grep 8080查看运行的端口号,过滤显示8080端口信息
-
history 查看系统历史执行命令记录
-
top命令
- PID 软件在系统运行的进程号
- USER 启动这个软件的用户
- %CPU 软件占用CPU的百分比
- %MEM 软件占用系统内存的百分比
- TIME+ 软件启动的时间
- COMMAND 进程关联的软件名称
-
ps -ef | grep tomcat查看当前运行的软件,以tomcat或者java关键字进行过滤- 杀进程
kill -9 进程号执行这条命令可以直接杀死Linux中的某个进程
- 杀进程
-
WEB项目中常用的一些文件类型(Java)
- jdbc.properties 属于java web项目中的数据库连接池文件
- .xml、.json、*.properties前两个属于数据存储类文件,后一个属于java中的配置文件
-
日志级别:debug<info<warn<Error
- warn:告警日志,输出警告一类的日志,不会影响系统的正常运行
- error:错误日志,输出错误一类的日志,会影响系统的正常运行
- debug:调试日志,指的是系统输出开发调试级别的详细日志,因内容及其详细,我们做软件测试一般不关注,且线上环境严禁输出debug日志
- info:普通日志:系统运行的状态,信息,等等输出的一些日志,主要用来关注系统是否正常以及运行状态
-
查看日志的命令
- tomcat的日志在tomcat的根目录下的logs中,如果开发没有强制指定app的日志输出文件,则默认会被tomcat输出到catalina.out

- tail -f [日志文件名称] 动态打印日志
tail -f catalina.out命令默认打印倒数10行日志 -tail -200f catalina.out命令动态打印日志文件中倒数200行日志tail -f catalina.out | grep 'error'命令动态打印且过滤输出日志中行中包含error关键字的日志
- 查询日志中含有某个关键字的信息
- cat app.log |grep 'error'
- 查询日志尾部最后10行的日志
- tail -n 10 app.log
- 查询10行之后的所有日志
- tail -n +10 app.log
- 查询日志文件中的头10行日志
- head -n 10 app.log
- 查询日志文件除了最后10行的其他所有日志
- head -n -10 app.log
- 查询日志中含有某个关键字的信息,显示出行号(在1的基础上修改)
- cat -n app.log |grep 'error'
- 显示102行,前10行和后10行的日志 92 102 112
- cat -n app.log |tail -n +92|head -n 20
- 据日期时间段查询(前提日志总必须打印日期,先通过grep确定是否有该时间点)
- sed -n '/2018-11-02 10:00:00/,/2018-11-02 10:55:00/p' app.log
- 1s=1000ms 一秒等于1000毫秒
- 1ms=1000um 一毫秒等1000微秒
- 把日志保存到文件
- cat -n app.log |grep "error" > temp.txt
- vim 查看日志
- vim app.log
- 使用vim命令进入查看状态(只进入查看状态,不进入可编辑状态)敲 /要查询的关键字 然后敲击回车键,可用于标记日志中的关键字高亮显示
- > 文件名称 清空文本文件(常用于清空日志文件)
- tomcat的日志在tomcat的根目录下的logs中,如果开发没有强制指定app的日志输出文件,则默认会被tomcat输出到catalina.out
-
ssh命令详解
- 格式:ssh [user@host] [command]
- 参数(只列出常用)
- -l:指定连接远程服务器登录用户名
- -p:指定远程服务器上的端口
-
Log位置
- /var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一
- /var/log/secure 与安全相关的日志信息
- /var/log/maillog 与邮件相关的日志信息
- /var/log/cron 与定时任务相关的日志信息
- /var/log/spooler 与UUCP和news设备相关的日志信息
- /var/log/boot.log 守护进程启动和停止相关的日志消息
-
grep
- 主要参数
- -c:只输出匹配行的计数
- -I:不区分大 小写(只适用于单字符)
- -h:查询多文件时不显示文件名
- -l:查询多文件时只输出包含匹配字符的文件名
- -n:显示匹配行及 行号
- -s:不显示不存在或无匹配文本的错误信息
- -v:显示不包含匹配文本的所有行
- 主要参数
-
用户和群组
- groupadd group_name 创建组
- groupdel group_name 删除组(要想删除组,首先必须先删除组内所有用户)
- groupmod -n new_group_name old_group_name 重命名一个用户组
- useradd -c "Name Surname " -g admin -d /home/user1 -s /bin/bash user1 创建一个属于 "admin" 用户组的用户
- useradd user_name 创建一个新用户
- userdel -r user_name 删除一个用户加-r顺带删除用户根目录 ( '-r' 排除主目录)
- usermod -c "User FTP" -g system -d /ftp/user1 -s /bin/nologin user1 修改用户属性
- passwd 修改当前用户密码
- passwd user_name 修改指定用户密码-只能超级管理员用户执行
- chage -E 2005-12-31 user1 设置用户口令的失效期限
- pwck 检查 '/etc/passwd' 的文件格式和语法修正以及存在的用户
- grpck 检查 '/etc/passwd' 的文件格式和语法修正以及存在的群组
- newgrp group_name 登陆进一个新的群组以改变新创建文件的预设群组
- 创建用户并将该用户分配到指定的组:useradd -g 组名 用户名
- 改变用户所在组:usermode -g 组名 用户名 (改变条件 必须为root 用户操作)
- 查看linux中所有组信息
- vi /etc/group
- cat /etc/group
- 查看linux中所有用户信息
- vi /etc/passwd
- cat /etc/passwd
-
linux服务器关机与重启
- halt 立刻关机
- poweroff 立刻关机
- shutdown -h now 立刻关机(root用户使用)
- shutdown -h 10 10分钟后自动关机 如果是通过shutdown命令设置关机的话,可以用shutdown -c命令取消重启
- reboot 重启
- shutdown -r now 立刻重启(root用户使用)
- shutdown -r 10 过10分钟自动重启(root用户使用)
- shutdown -r 20:35 在时间为20:35时候重启(root用户使用) 如果是通过shutdown命令设置重启的话,可以用shutdown -c命令取消重启
MySQL数据库安装
-
Centos7系统绿色安装MySQL数据库
- 使用shell工具连接Centos服务器
- 执行
rpm -qa|grep mariadb命令检查是否安装有原生的mariadb
- 执行
rpm -e --nodeps mariadb-libs-5.5.56-2.el7.x86_64卸载系统自带的mariadb
- 执行
rm -rf /etc/my.cnf删除etc目录下的my.cnf文件 - 执行
groupadd mysql命令创建MySQL组 - 执行
useradd -g mysql mysql命令创建MySQL用户
- 下载mysql的tar包下载地址下载页面的列表拉到最下方选择TAR下载

- 下载后的源文件类似于:mysql-5.7.23-linux-glibc2.12-x86_64.tar.gz
- 执行
rz命令把mysql安装包上载到 /usr/local/src/ 目录下(如提示没有命令,可执行:yum install lrzsz -y进行安装上传下载命令) - 执行
tar -xvf mysql-5.7.23-linux-glibc2.12-x86_64.tar.gz命令解压安装包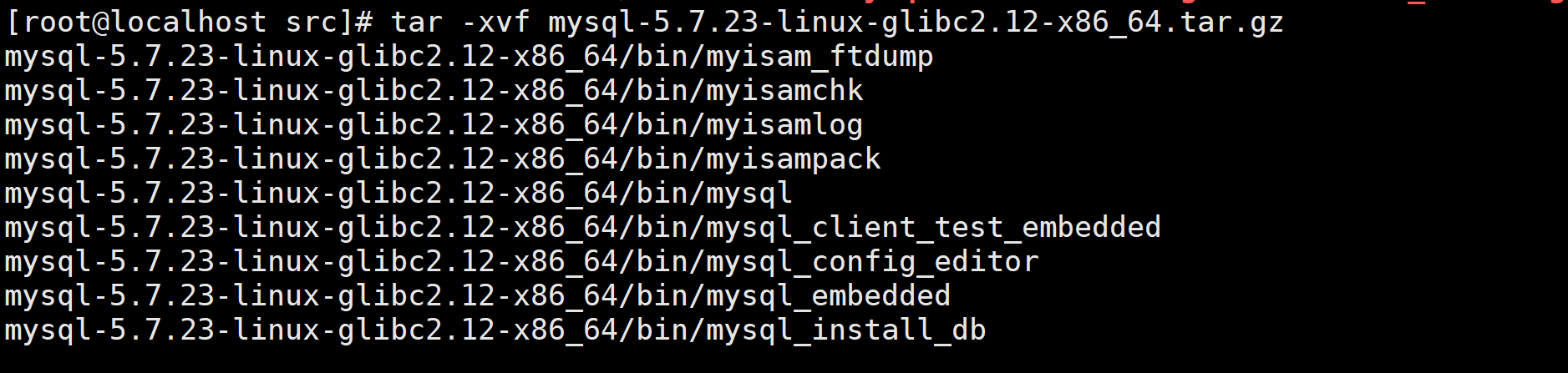
- 执行
mv mysql-5.7.23-linux-glibc2.12-x86_64 mysql命令把解压后的包重命名为mysql
- 执行
mv mysql /usr/local命令把安装包剪切到上层目录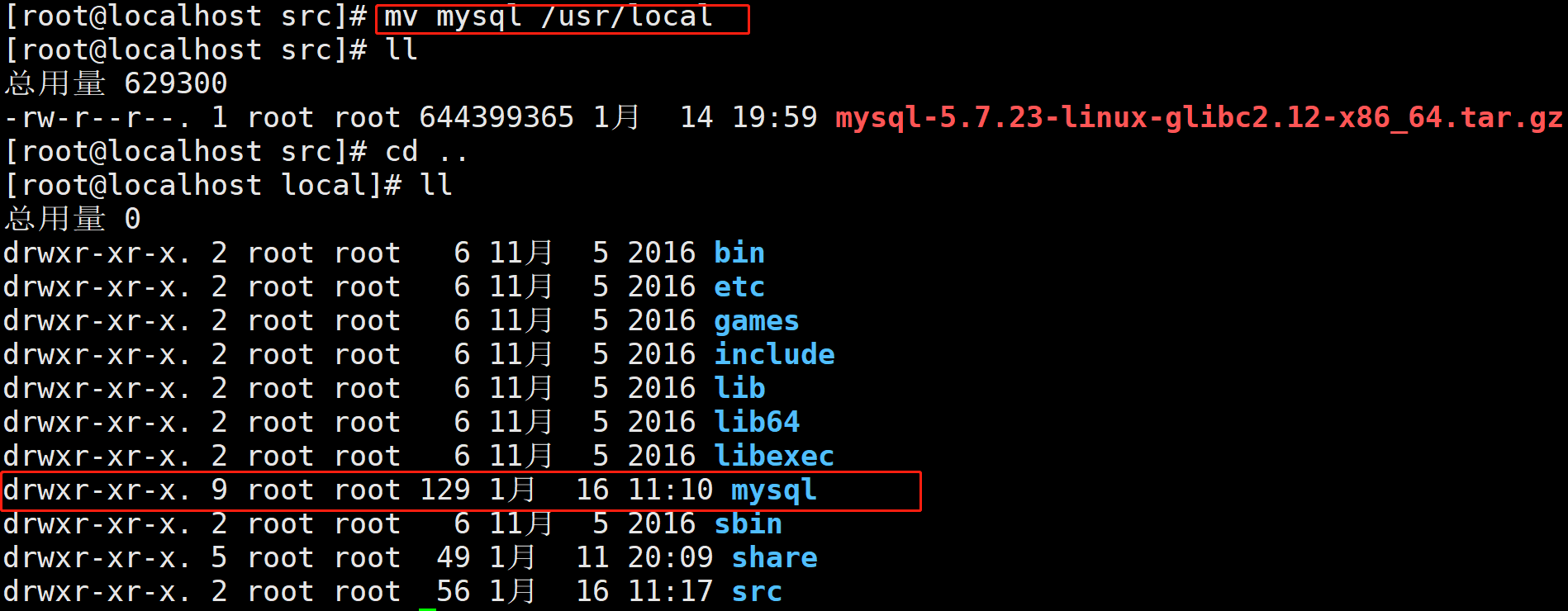
- 执行
cd mysql/命令进入安装包根目录,执行mkdir data命令建立数据表存储目录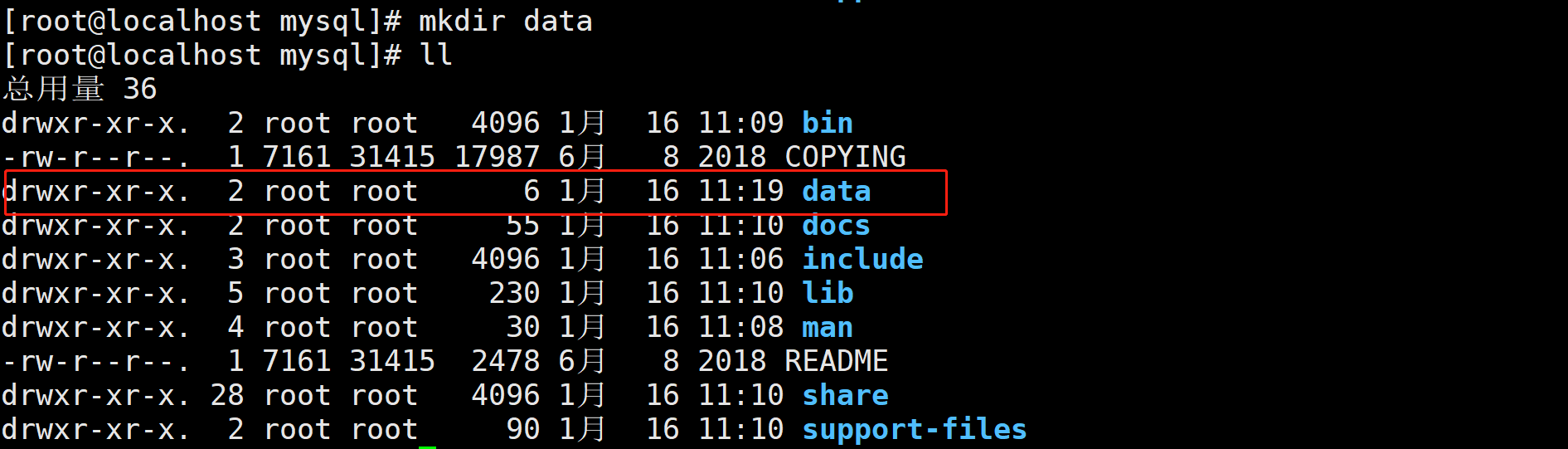
- 执行
chown -R mysql:mysql /usr/local/mysql命令修改mysql安装目录所属用户和用户组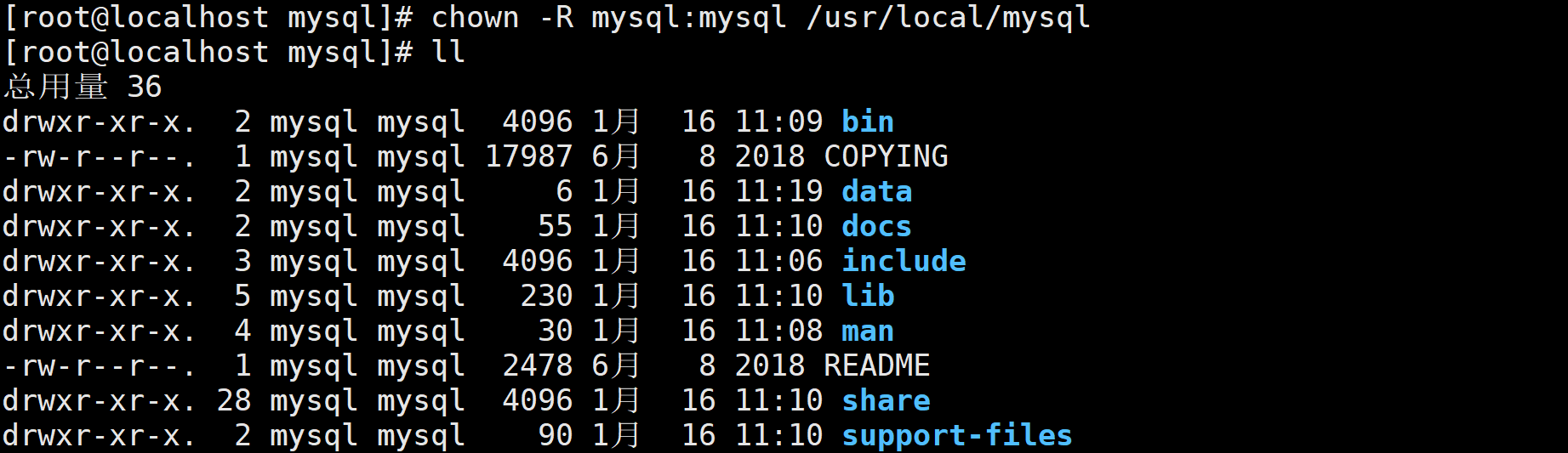
- 执行
touch /etc/my.cnf命令创建mysql配置文件
- 执行
vim /etc/my.cnf命令进入编辑模式复制下面的内容到配置文件中并保存退出
[mysql] # 设置mysql客户端默认字符集 default-character-set=utf8 [mysqld] # 设置3306端口 port = 3306 # 设置mysql的安装目录 basedir=/usr/local/mysql # 设置mysql数据库的数据的存放目录 datadir=/usr/local/mysql/data # 允许最大连接数 max_connections=200 # 服务端使用的字符集默认为8比特编码的latin1字符集 character-set-server=utf8 # 创建新表时将使用的默认存储引擎 default-storage-engine=INNODB lower_case_table_names=1 max_allowed_packet=16M
-
执行命令
cd /usr/local/mysql/进入mysql根目录执行bin/mysql_install_db --user=mysql --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data/命令安装mysql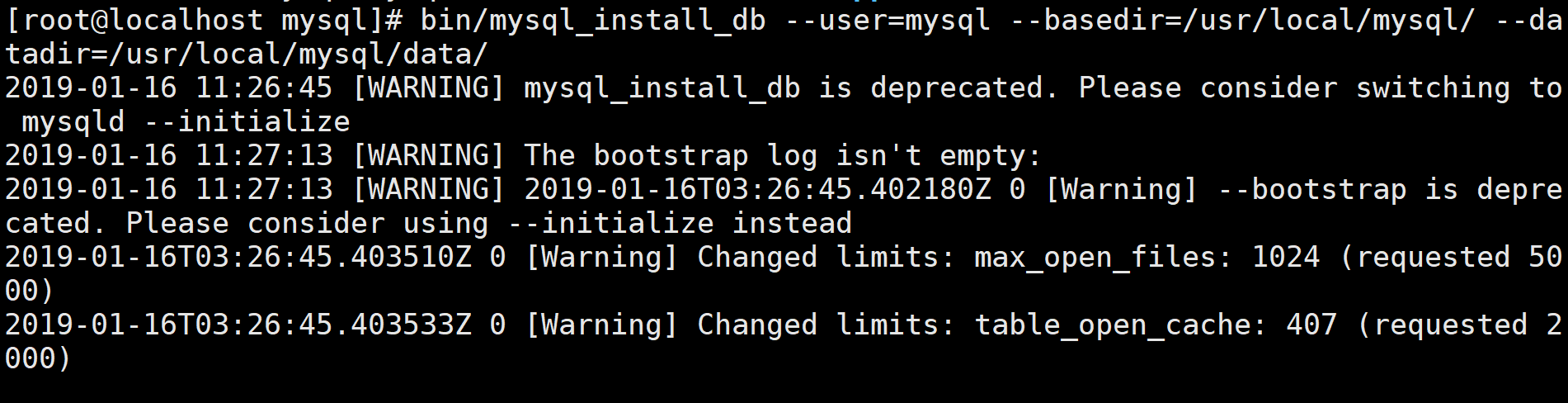
-
执行
chmod 777 /etc/my.cnf命令对配置文件赋权
-
执行
chmod +x /etc/init.d/mysqld命令对启动文件进行赋权
-
执行chkconfig --level 35 mysqld on命令设置开机自启,并执行
chkconfig --list mysqld查看设置是否生效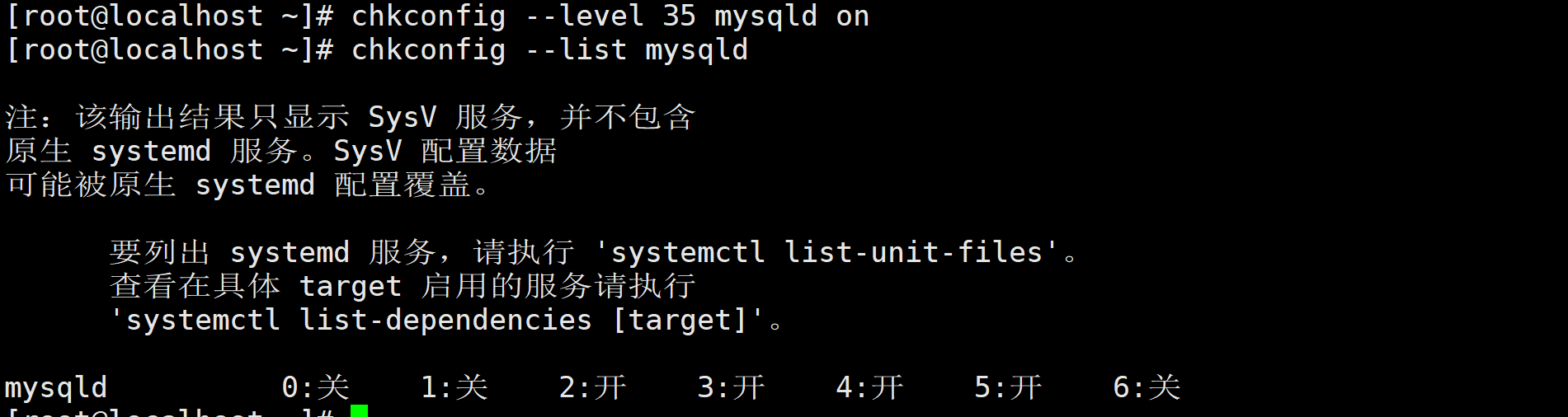
-
执行
vim /etc/profile修改配置文件,在配置文件最底下增加export PATH=$PATH:/usr/local/mysql/bin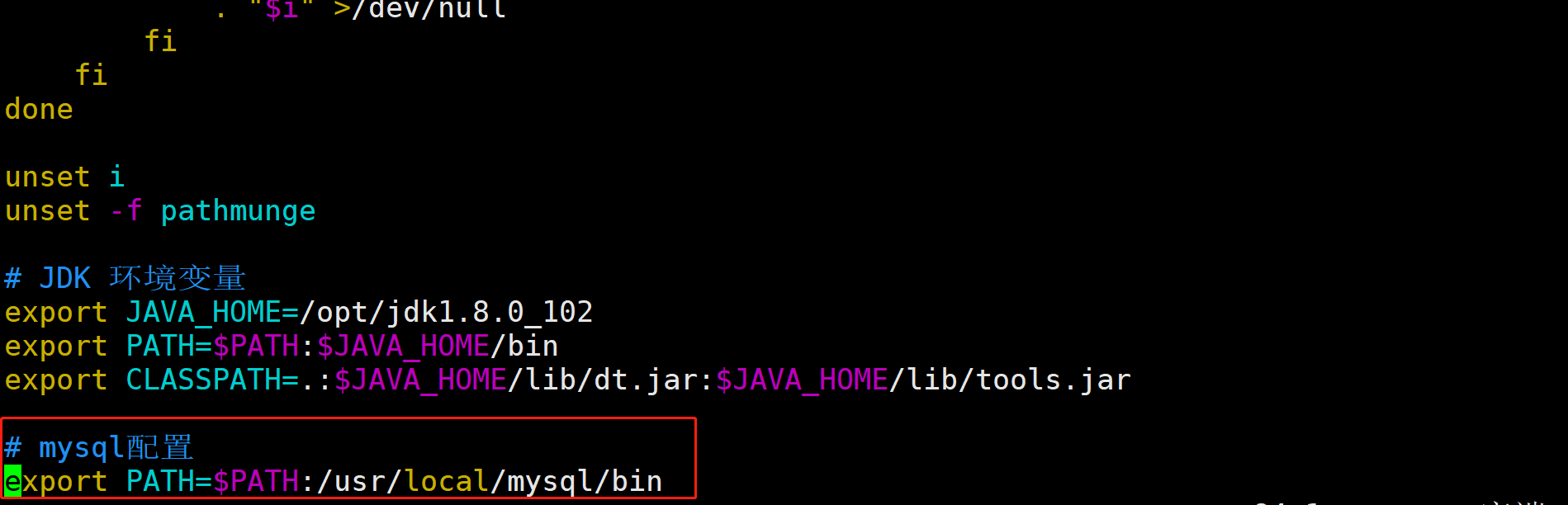
-
执行
source /etc/profile命令使修改生效
-
执行
cat /root/.mysql_secret命令获取初始密码
-
执行
/etc/init.d/mysqld restart启动MySQL数据库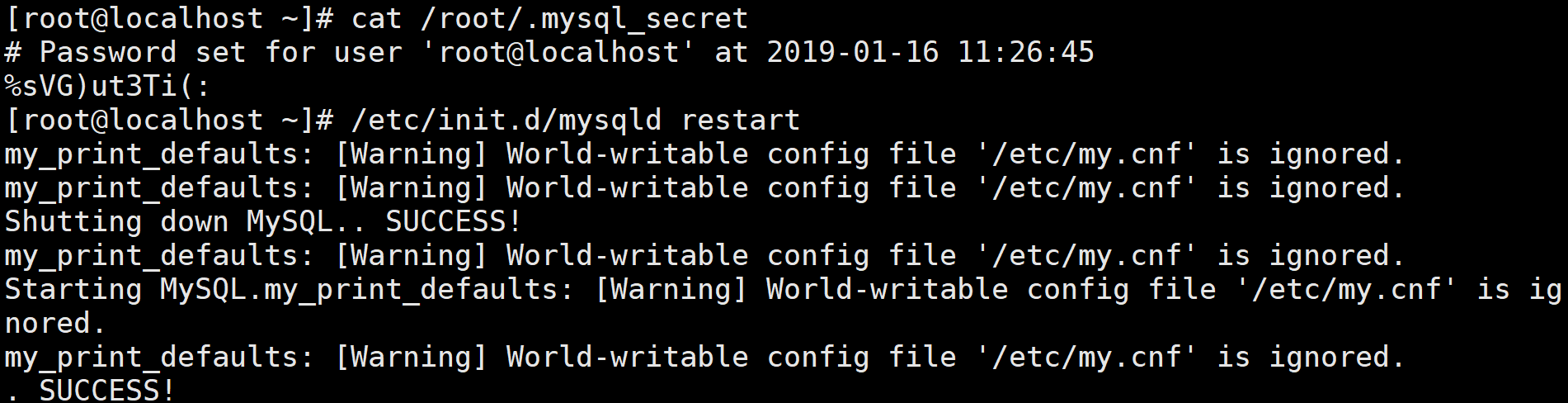
-
执行
mysql -u root -p命令并输入初始密码登入mysql后台界面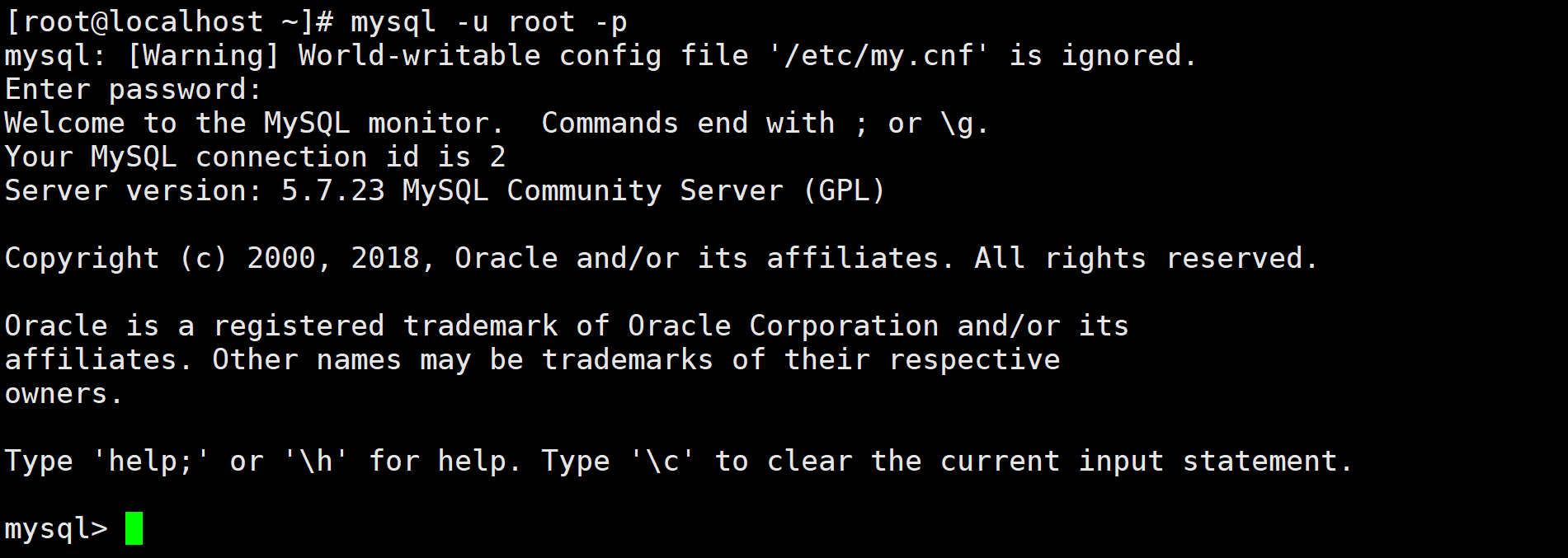
-
执行
set PASSWORD = PASSWORD('新密码');sql语句修改mysql的root密码
-
执行
use mysql切换到mysql库
-
执行
update user set host='%' where user='root';语句添加远程访问权限
-
执行
select host,user from user;命令查看是否成功
-
执行
exit退出mysql页面
-
执行
chkconfig --add mysqld添加服务 -
执行
chkconfig --list mysqld检查服务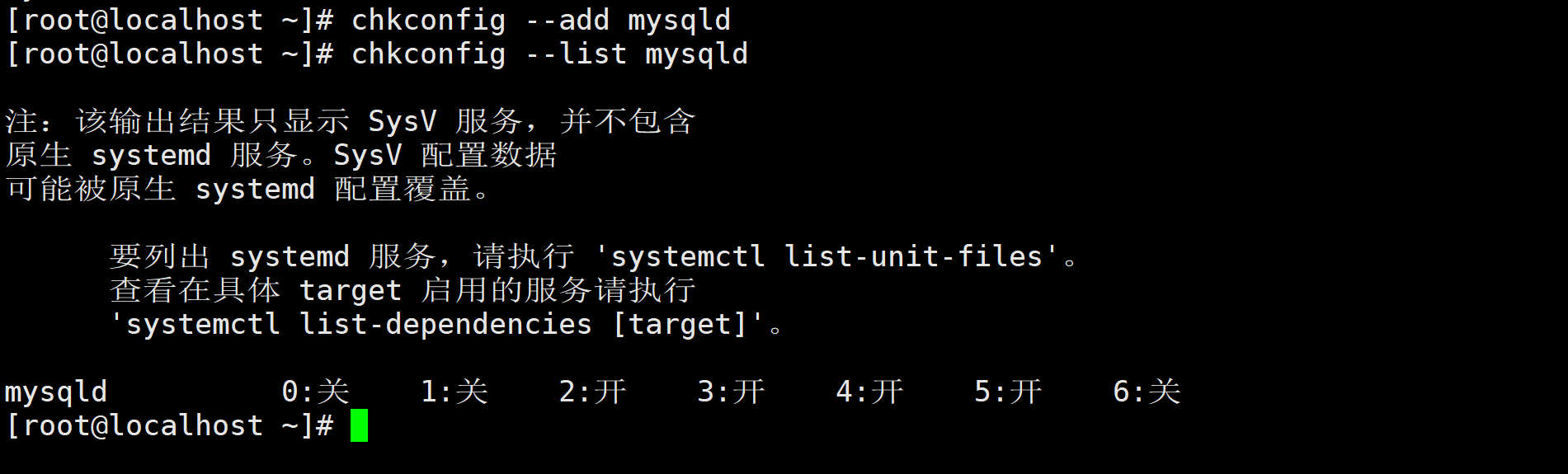
-
执行
service mysqld status查询MySQL启动状态
-
执行
service mysqld restart重启mysql(附:停止mysql:service mysqld stop启动mysql:service mysqld start)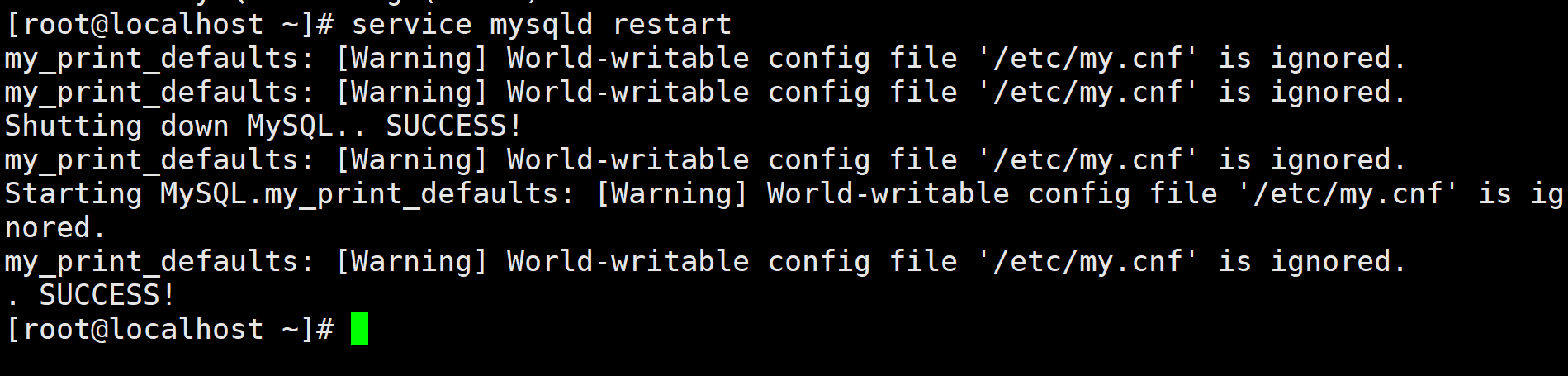
-
执行
mysql -u root -p命令输入修改的心的MySQL的root密码进行验证是否修改完成 -
执行
yum install -y iptables-services安装iptables-service -
执行
systemctl stop firewalld临时关闭Centos7的防火墙 -
执行
systemctl disable firewalld禁止防火墙开机启动 -
执行
service iptables status查看防火墙状态
-
CentOS7 通过YUM安装MySQL5.7
- 执行
cd /home/进入到要存放安装包的位置 - 执行
rpm -qa | grep mysql或者yum list installed | grep mysql查看系统中是否已安装 MySQL 服务 - 执行
yum -y remove mysql-libs.x86_64删除 MySQL 及其依赖的包 - 执行
wget http://repo.mysql.com/mysql57-community-release-el7-8.noarch.rpm命令下载下载 mysql57-community-release-el7-8.noarch.rpm 的 YUM 源 - 执行
rpm -ivh mysql57-community-release-el7-8.noarch.rpm命令安装mysql57-community-release-el7-8.noarch.rpm - 执行
yum install mysql-server -y安装 MySQL - 等待安装完成,执行
service mysqld start启动MySQL服务 - 执行
grep "password" /var/log/mysqld.log命令从安装日志中获取MySQL初始密码(如未获取到相应密码,可执行mysqld_safe --user=root --skip-grant-tables --skip-networking & mysql -u root进入MySQL数据库后先执行却库SQLuse mysql;,在执行update user set password=password("新密码") where user="root";修改密码,然后执行exit退出进行验证,如忘记root密码时也可使用此方法进行修改) - 执行
mysql -u root -p命令输入初始密码 - 执行
SET PASSWORD = PASSWORD('新密码');sql修改root密码 - 执行
grant all privileges on *.* to root@"%" identified by "MySQL的root用户密码";设置用户 root 可以在任意 IP 下被访问 - 执行
grant all privileges on *.* to root@"localhost" identified by "MySQL的root用户密码";设置用户 root 可以在本地被访问 - 执行
flush privileges;命令刷新权限使之生效 - 输入
exit,在执行mysql -u root -p输入新密码进行验证 - 执行
vim /etc/my.cnf根据以下方式添加内容
在 [mysqld] 前添加如下代码: [client] default-character-set=utf8 在 [mysqld] 后添加如下代码: character_set_server=utf8 - 执行
- 链接数据库在数据库中执行
show variables like '%character%';查看数据库表的字符集,6个utf8就算OK
-
MySQL文件存放位置:
- 配置文件:/etc/my.cnf
- 存放数据库文件的目录:/var/lib/mysql
- 日志记录文件:/var/log/ mysqld.log
- 服务启动脚本:/usr/lib/systemd/system/mysqld.service
- socket文件:/var/run/mysqld/mysqld.pid
SQL学习、MySQL、Oracle、SQL Server数据库
- 连接MySQL数据库四大基本要素
- 数据库服务器的IP
- 数据库服务器的数据库端口号
- 数据库用户名
- 数据库密码
- linux登陆MySQL数据库
- mysql -u root -p
- -u 用户(登陆的用户)
- -p 密码
- -h host 主机名
- -P 端口号(MySQL默认端口号3306)
- mysql -u root -p
- Windows电脑使用Navicat工具连接数据库
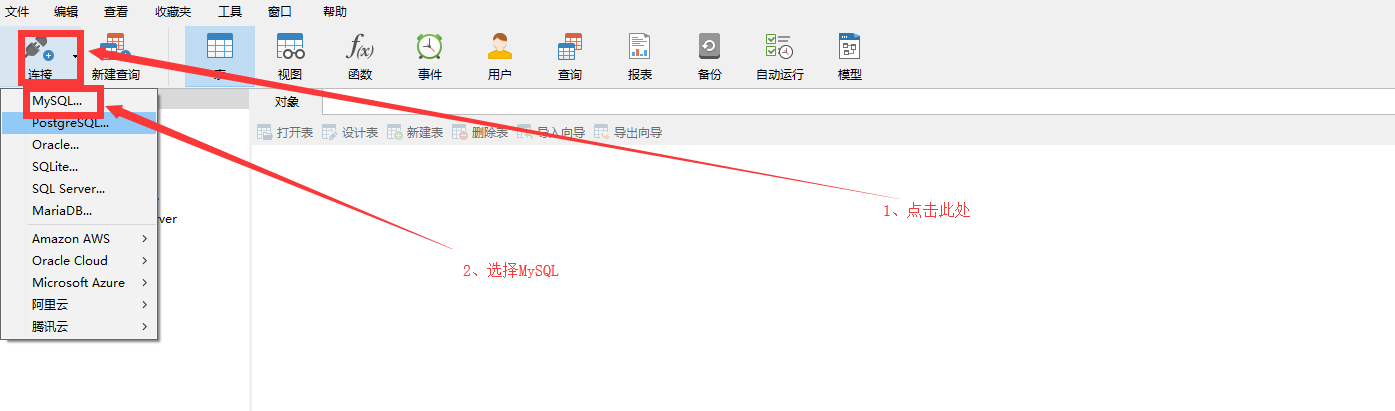
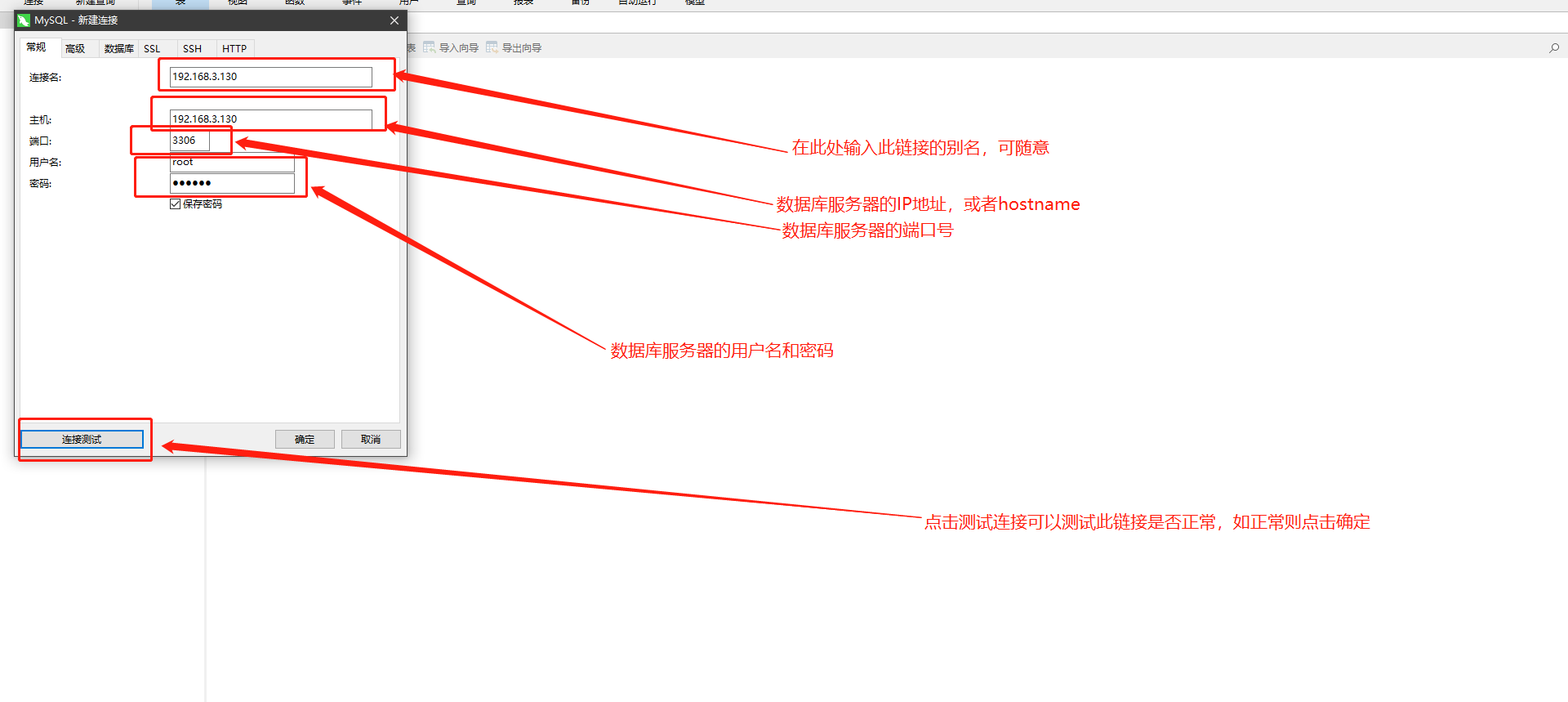
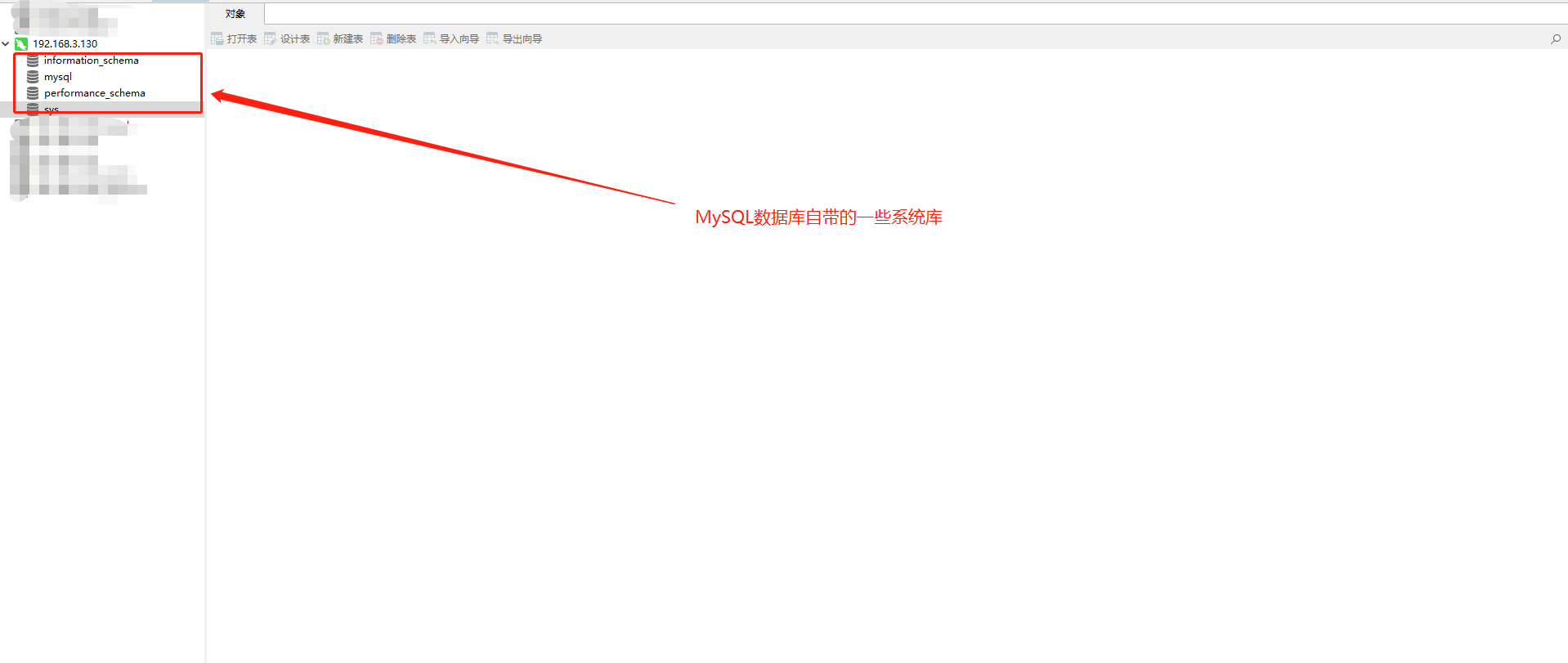
- SQL
-
SQL是用于访问和处理数据库的标准计算机语言
-
指结构化查询语言,全称是 Structured Query Language
-
对于数据库的操作可分为:增、删、改、查
-
所有的数据库支持大部分标准化SQL语句,但对于部分语句如top语句等等会有轻微差异
-
linux 后台使用MySQL数据库
- 查询库:show databases;
- 切库:use student;
- 查询所有表:show tables;
- 查询表中所有数据:select * from table_name;
-
在SQL语言中所有关键字不区分大小写
-
分号是区分每条SQL的标准关键字,尽量在每条SQL语句结束添加分号
-
常用SQL关键字:
- SELECT 从数据库中提取数据(查询操作)
- UPDATE 修改数据库中的数据(修改操作)
- DELETE 从数据库中删除数据(删除操作)
- INSERT INTO 向数据库中插入新数据(新增操作)
- CREATE DATABASE 创建新数据库(新增操作)
- ALTER DATABASE 修改数据库(修改操作)
- CREATE TABLE 创建新表(新增操作)
- ALTER TABLE 修改表(修改操作)
- DROP TABLE 删除表(删除操作)
- CREATE INDEX 创建索引(新增操作)
- DROP INDEX 删除索引(删除操作)
-
SELECT 查询语句
-
从数据库查询数据,结果被存储到结果集中
-
语法:
SELECT column_name,column_name FROM table_name; SELECT 需要展示的数据列 FROM 查询的数据源; SELECT * FROM table_name;
-
-
SELECT DISTINCT 语句用于返回唯一不同的值
-
语法:
SELECT DISTINCT column_name,column_name FROM table_name; -
实例
SELECT DISTINCT age from student;
-
-
WHERE 子句用于过滤记录
-
语法:
SELECT column_name,column_name FROM table_name WHERE column_name operator value; 实例: SELECT * from student where age > 20 ; SELECT * from student where name='后秀辽'; -
运算符:
运算符 描述 = 等于 <>或!= 不等于 > 大于 < 小于 >= 大于等于 <= 小于等于 BETWEEN 在某个范围内 LIKE 搜索某种模式(模糊匹配) IN 针对某个列可能出现的多个值(包含) -
实例:
select * from student where age = 20; select * from student where sex <> '男'; select * from student where sex != '男'; -- 注释 # 注释 # 注释 -- BETWEEN AND 这两个在一起使用,取值范围包前包后 select * from student where age BETWEEN 16 and 20; -
AND & OR 运算符用于基于一个以上的条件对记录进行过滤
-
AND 逻辑与,汉语可当并且用
-
OR 逻辑或,汉语中可当或者使用
select * from student where age = 18 and sex = '女'; select * from student where age = 18 or sex = '女';
-
-
-
ORDER BY 关键字用于对结果集进行排序
-
语法
SELECT column_name,column_name FROM table_name ORDER BY column_name,column_name ASC|DESC; -
示例
-- 升序 SELECT * from student ORDER BY age; -- 降序 SELECT * from student ORDER BY age desc; -- 多列排序 -- order by 后的字段谁在前,先排谁,如果有相同的,在根据第二个字段进行排序,如果第二个字段也有相同的,则有第三个字段的话会根据第三个字段进行排序... select * from number ORDER BY age,chengji;
-
-
INSERT INTO 语句用于向表中插入新记录
-
语法:
-- insert into 语句有两种语法 -- 第一种,不指定插入的列,直接提供需要插入的值即可 -- 需要注意的是不指定列,则必须插入的值为所有列,且顺序必须和表中的列顺序保持一致 INSERT INTO table_name VALUES (value1,value2,value3,...); -- 第二种,指定插入的列,根据指定的列顺序提供插入的值 INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...);
-
-
UPDATE 语句用于更新表中已存在的记录
-
语法:
UPDATE table_name SET column1=value1,column2=value2,... WHERE some_column=some_value; -
注意事项:
- 执行update语句之前一定要先把where字句后的条件拿到select语句中执行,确保查询到的数据是我们想要更新的数据,在去执行update语句
- 执行没有where子句的update语句是对表中所有数据的修改,所以一定要慎重执行
-
-
DELETE 语句用于删除表中的记录(逐行删除)
-
语法:
DELETE FROM table_name WHERE some_column=some_value; -- 删除所有数据 DELETE * FROM table_name; -
注意事项:
- 执行delete语句之前一定要先把where字句后的条件拿到select语句中执行,确保查询到的数据是我们想要删除的数据,在去执行delete语句
- 执行没有where子句的delete语句是对表中所有数据的删除,所以一定要慎重执行
-
-
TOP、LIMIT、ROWNUM 字句
-
MySQL 语法
SELECT column_name(s) FROM table_name LIMIT number; -
SQL Server语法
SELECT TOP number * FROM table_name; -
Oracle语法
SELECT column_name(s) FROM table_name WHERE ROWNUM <= number;
-
-
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式(模糊匹配)
-
语法:
SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern; -
两个占位符:_和%
- _表示占一位
- %表示0个或者多个字符
-
示例:
SELECT * from student WHERE name LIKE '后__'; SELECT * from student WHERE name LIKE '%后%';
-
-
IN 操作符允许在SQL中的where子句中规定多个值
-
语法
SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,...); -- 示例: select * from student where age = 18 or age = 20 or age = 22; select * from student where age in (18,20,22);
-
-
BETWEEN 操作符用于选取介于两个值之间的数据范围内的值
-
语法:
SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2; -- 示例: select * from student where age >=18 and age <=22; select * from student where age BETWEEN 18 and 22;
-
-
NOT BETWEEN 操作符用于选取不介于两个值之间的数据
-
语法:
SELECT column_name(s) FROM table_name WHERE column_name NOT BETWEEN value1 AND value2; -- 示例: select * from student where age <18 or age >22; select * from student where age NOT BETWEEN 18 and 22;
-
-
带有 IN 的 BETWEEN 操作符
-
语法:
SELECT column_name(s) FROM table_name WHERE (column_name1 BETWEEN value1 AND value2) AND column_name2 NOT IN (value3, value4); -- 示例: SELECT * FROM student WHERE (age BETWEEN 18 AND 20) AND xi NOT IN ('计算机系', '金融系');
-
-
AS 可以为表名称或列名称指定别名
-
语法
SELECT column_name AS alias_name FROM table_name AS alias_name; -- 示例: select name as '姓名',sex as '性别', adder as '地址',xi as '系' FROM student; select * from student as s,number as n where s.`name`= n.`name`;
-
-
SQL 连接(JOIN)连接查询,join 用于把来自两个或多个表的行结合起来
-
INNER JOIN 内联,如果连接的两个表中有匹配的连接数据,则返回匹配的,没有匹配的则返回空数据
-
语法
SELECT column_name(s) FROM table_name1 INNER JOIN table_name2 ON table_name1.column_name=table_name2.column_name; -- 示例 SELECT * FROM student INNER JOIN number ON student.name = number.name; -- 一般内联直接使用JOIN ON关键字,下面的这条SQL语句等同于上面的SQL SELECT * FROM student JOIN number ON student.name = number.name; -
示意图
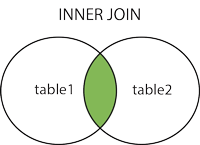
-
-
LEFT JOIN 左联,以左表为主,右表为辅,查询出满足条件的左表的所有数据,然后拿右表进行关联,如果有关联数据则显示关联的数据,如果没有,则右表的列展示为空,左表展示满足条件的全部数据
-
语法
SELECT column_name(s) FROM table_name1 LEFT JOIN table_name2 ON table_name1.column_name=table_name2.column_name; -- 示例 SELECT * FROM student LEFT JOIN number ON student.name = number.name -
示意图
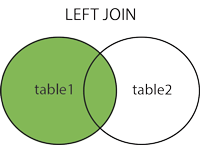
-
-
RIGHT JOIN 右联,和左联相反
-
语法
SELECT column_name(s) FROM table_name1 RIGHT JOIN table_name2 ON table_name1.column_name=table_name2.column_name; -- 示例 SELECT * FROM number RIGHT JOIN student ON student.name = number.name -
示意图
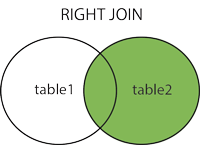
-
-
FULL JOIN 全联,左联和右联的集合体,备注:此SQL不支持MySQL数据库
-
语法
SELECT column_name(s) FROM table_name1 FULL OUTER JOIN table_name2 ON table_name1.column_name=table_name2.column_name; -- 示例 SELECT * FROM number FULL OUTER JOIN student ON student.name = number.name; -
示意图
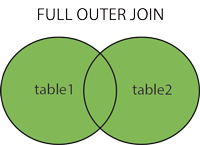
-
-
-
SQL UNION操作符用于合并两个或多个 SELECT 语句的结果集。请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同
-
UNION语法:
SELECT column_name(s) FROM table1 UNION SELECT column_name(s) FROM table2; -
UNION ALL 语法
SELECT column_name(s) FROM table1 UNION ALL SELECT column_name(s) FROM table2; -
INSERT INTO SELECT 语句从一个表复制数据,然后把数据插入到一个已存在的表中。目标表中任何已存在的行都不会受影响.
-
语法
-- 从一个表中复制所有的列插入到另一个已存在的表中 INSERT INTO table_name2 SELECT * FROM table_name1; -- 示例 INSERT into student_copy1 SELECT * FROM student -- 只复制希望的列插入到另一个已存在的表中 INSERT INTO table2 (column_name(s)) SELECT column_name(s) FROM table1; -- 示例 insert into number_copy1(name) SELECT name from student;
-
-
SQL CREATE DATABASE 语句,用于创建数据库
-
语法
CREATE DATABASE database_name; -- 示例 CREATE DATABASE `interface_one` -- 指定数据库字符集和排序规则 DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
-
-
CREATE TABLE 语句,用于创建数据库中的表
-
语法
CREATE TABLE `table_name` ( `column_name1` data_type(size), `column_name2` data_type(size), `column_name3` data_type(size), ) -- 参数示意 column_name 参数规定表中列的名称 data_type 参数规定列的数据类型(例如 varchar、integer、decimal、date 等等)。 size 参数规定表中列的最大长度。 -- 示例 -- 创建表之前一定检查是否存在相同的表,以下语句可以理解为:删除number这个表,如果存在的话 DROP TABLE IF EXISTS `number`; CREATE TABLE `number` ( `name` varchar(255), `kemu` varchar(255), `chengji` int(11), `id` int(9) )
-
-
约束(Constraints)SQL 约束用于规定表中的数据规则
-
CREATE TABLE + CONSTRAINT 语法
CREATE TABLE table_name ( column_name1 data_type(size) constraint_name, column_name2 data_type(size) constraint_name, column_name3 data_type(size) constraint_name, ... ) -
SQL中的约束
-
非空约束:NOT NULL 指定某列不能存储空值
-
示例
CREATE TABLE `number` ( -- 对name列做非空约束 `name` varchar(255) NOT NULL, `kemu` varchar(255), `chengji` int(11), `id` int(9) )
-
-
唯一约束:UNIQUE 保证某列的值在一张表中是唯一存在的(可以存在空值,但是只能存在一个)
-
示例
-- mysql CREATE TABLE `number` ( -- 对name列做非空约束 `name` varchar(255) NOT NULL, `kemu` varchar(255), `chengji` int(11), `id` int(9), -- 对name做唯一约束 UNIQUE(name) ) -- sql server 和Oracle CREATE TABLE `number` ( -- 对name列做非空约束 -- 对name做唯一约束 `name` varchar(255) NOT NULL UNIQUE, `kemu` varchar(255), `chengji` int(11), `id` int(9) ) -- 为已经存在的表增加唯一约束 ALTER TABLE number ADD UNIQUE (name); -- 增加唯一约束,并自定义约束名称 ALTER TABLE number ADD CONSTRAINT nb_name UNIQUE (name) -- 撤销约束 -- MySQL ALTER TABLE number DROP INDEX nb_name -- SQL server 和 oracle ALTER TABLE number DROP CONSTRAINT nb_name
-
-
主键约束:PRIMARY KEY 是非空约束和唯一约束的集合体,唯一标示表中一行的数据(主键约束可以使用一列或者两列乃至多列共做主键)
-
语法
-- mysql CREATE TABLE `number` ( `name` varchar(255), `kemu` varchar(255), `chengji` int(11), `id` int(9) NOT NULL, -- 为表中增加主键约束 PRIMARY KEY (id) ) -- sqlserver 和 oracle数据库 CREATE TABLE `number` ( `name` varchar(255), `kemu` varchar(255), `chengji` int(11), -- 为表中增加主键约束 `id` int(9) NOT NULL PRIMARY KEY ) -- 为已经存在的表增加主键约束 ALTER TABLE number ADD PRIMARY KEY (id); -- 如需命名主键约束 ALTER TABLE number ADD CONSTRAINT nb_id PRIMARY KEY (id) -- 撤销主键约束 ALTER TABLE Persons DROP PRIMARY KEY -
自增序列
- 在数据库中一般使用自增序列作为主键,且自增序列唯一且不为空,在已有数据的表中创建自增序列,数据库会自动填充空值
-
语法
-- 创建表时增加自增序列 CREATE TABLE number ( id int NOT NULL AUTO_INCREMENT, name VARCHAR(255) ) -- 建表后增加自增序列 -- 此SQL可以修改已经生成的自增序列,可以指定增长的开始值,也可以修改被删除数据库,如果自增序列会出现断裂,也可以使用以下语句进行重新生成 -- 每次执行此SQL会使数据库中的自增序列按照当前最大的数继续自增 ALTER TABLE number AUTO_INCREMENT=1
-
- 在数据库中一般使用自增序列作为主键,且自增序列唯一且不为空,在已有数据的表中创建自增序列,数据库会自动填充空值
-
-
外键约束:FOREIGN KEY 保证一个表中的数据匹配另一个表中的值的参照完整性
-
语法
-- mysql创建外键约束 CREATE TABLE student ( student_id int(9) NOT NULL, name varchar(255), PRIMARY KEY (student_id), FOREIGN KEY (student_id) REFERENCES number(student_id) ) -- SQLserver和Oracle创建外键约束 CREATE TABLE student ( name varchar(255), student_id int(9) FOREIGN KEY REFERENCES number(student_id) ) -- MySQL、SQLserver、Oracle CREATE TABLE student ( name varchar(255), student_id int(9), CONSTRAINT fk_StuNumber FOREIGN KEY (student_id)REFERENCES number(student_id) ) -- 如果表已经存在则使用下面的方式进行创建 ALTER TABLE number ADD FOREIGN KEY (student_id) REFERENCES number(student_id) -- 如需对外键约束重命名,则使用以下方法 ALTER TABLE Orders ADD CONSTRAINT fk_StuNumber FOREIGN KEY (student_id) REFERENCES number(student_id) -- 撤销外键约束 -- MySQL ALTER TABLE Orders DROP FOREIGN KEY fk_StuNumber -- SQLserver和Oracle ALTER TABLE Orders DROP CONSTRAINT fk_StuNumber
-
-
检查约束: CHECK 检查列中的值要符合检查约束的条件
-
语法
-- MySQL CREATE TABLE student ( name varchar(255), student_id int(9), sex int(2), CHECK (student_id > 0) ) -- SQLserver、Oracle CREATE TABLE student ( name varchar(255), student_id int(9) CHECK(student_id > 0), sex int(2) ) -- 创建表之后的check约束 ALTER TABLE student ADD CHECK (student_id>0) -- 撤销CHECK约束 -- MySQL ALTER TABLE student DROP CHECK chk_student -- SQLserver、Oracle ALTER TABLE student DROP CONSTRAINT chk_student
-
-
默认约束:DEFAULT 规定没有给列赋值时的默认值
-
语法
CREATE TABLE student ( name varchar(255), student_id int(9), adder varchar(255) DEFAULT '中国' ) -- 当表已经被创建时增加默认约束 -- MySQL ALTER TABLE student ALTER adder SET DEFAULT '中国' -- SQLserver ALTER TABLE student ADD CONSTRAINT ab_c DEFAULT '中国' for adder -- Oracle ALTER TABLE student MODIFY adder DEFAULT '中国' -- 撤销约束 -- MySQL ALTER TABLE student ALTER adder DROP DEFAULT -- SQLserver、Oracle ALTER TABLE student ALTER COLUMN adder DROP DEFAULT
-
-
-
-
CREATE INDEX 语句用于在表中创建索引
-
创建索引
CREATE INDEX index_name ON table_name (column_name,...) -- 示例 CREATE INDEX SIndex ON student (name) CREATE INDEX SIndex ON student (name,student_id)
-
-
DROP 语句
-
删除索引
ALTER TABLE table_name DROP INDEX index_name -
删除表
DROP TABLE table_name; -
删除数据库
DROP DATABASE database_name; -
TRUNCATE TABLE截断表
TRUNCATE TABLE table_name;
-
-
ALTER TABLE 语法
-- 向数据库中添加列 ALTER TABLE table_name ADD column_name datatype; -- 删除表中的列 ALTER TABLE table_name DROP COLUMN column_name; -- 改变表中列的数据类型 -- MySQL ALTER TABLE table_name MODIFY COLUMN column_name datatype; -- SQLserver ALTER TABLE table_name ALTER COLUMN column_name datatype -- Oracle 10g之后版本 ALTER TABLE table_name MODIFY column_name datatype; -
CREATE VIEW 视图,是基于 SQL 语句的结果集的可视化的表
-
语法
CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition -
示例
CREATE VIEW Transcript AS SELECT s.NAME AS '姓名', s.sex AS "性别", s.studentid AS "学号", n.kemu AS '科目', n.chengji AS '成绩' FROM student AS s JOIN number AS n ON s.NAME = n.NAME; -- 查询视图 SELECT * FROM Transcript; -
删除视图
DROP VIEW view_name;
-
-
函数
-
DATE()函数
-- 时间格式化 DATE_FORMAT() 格式化时间的函数 DATE_FORMAT(date,format) date:合法的时间,format规定要展示的日期/时间格式 %a 简写的英文星期 %b 简写的英文月份 %c 数值表示的月份 %D 带有英文后缀的月中的第几天 %d 表示月中的第几天(00-31) %e 表示月中的第几天(0-31) %f 表示微秒数 %H 小时(0-23) %h 小时(00-23) %I 小时(01-12) %i 分钟(00-59) %j 表示年中的第几天(001-366) %k 小时数(0-23) %l 小时(1-12) %M 完整的英文月份 %m 月份(00-12) %p AM或者PM %r 十二个小时制的时间(hh:mm:ss AM或者PM) %S 秒数(00-59) %T 24小时制的时间(hh:mm:ss) %U 年中的第几周(00-53)星期日是一周的第一天 %u 年中的第几周(00-53)星期一是一周的第一天 %W 完整的英文星期 %w 一周的第几天(0表示星期日) %Y 4位表示的年份 %y 2位表示的年份 select date_format(now(),'%Y年%m月%d日 %T') -
NULL值代表遗漏的未知数据
-
IS NULL
-- 注:NULL和空字符串还有0是有区别的 SELECT * FROM student WHERE email IS NULL; -
IS NOT NULL
SELECT * FROM student WHERE email IS NOT NULL; -
IFNULL 函数
-- mysql SELECT IFNULL(email,"000@00.com") FROM student WHERE email IS NULL; -- Oracle SELECT name,NVL(email,000@00.com) FROM student WHERE email IS NULL; -- SQL Server SELECT name,ISNULL(email,000@00.com) FROM student WHERE email IS NULL;
-
-
-
数据类型
-
Text 类型
数据类型 描述 CHAR(size) 保存固定长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的长度。最多 255 个字符。 VARCHAR(size) 保存可变长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的最大长度。最多 255 个字符。**注释:**如果值的长度大于 255,则被转换为 TEXT 类型。 TINYTEXT 存放最大长度为 255 个字符的字符串。 TEXT 存放最大长度为 65,535 个字符的字符串。 BLOB 用于 BLOBs(Binary Large OBjects)。存放最多 65,535 字节的数据。 MEDIUMTEXT 存放最大长度为 16,777,215 个字符的字符串。 MEDIUMBLOB 用于 BLOBs(Binary Large OBjects)。存放最多 16,777,215 字节的数据。 LONGTEXT 存放最大长度为 4,294,967,295 个字符的字符串。 LONGBLOB 用于 BLOBs (Binary Large OBjects)。存放最多 4,294,967,295 字节的数据。 ENUM(x,y,z,etc.) 允许您输入可能值的列表。可以在 ENUM 列表中列出最大 65535 个值。如果列表中不存在插入的值,则插入空值。**注释:**这些值是按照您输入的顺序排序的。可以按照此格式输入可能的值: ENUM('X','Y','Z') SET 与 ENUM 类似,不同的是,SET 最多只能包含 64 个列表项且 SET 可存储一个以上的选择。 -
Number 类型
数据类型 描述 TINYINT(size) 带符号-128到127 ,无符号0到255。 SMALLINT(size) 带符号范围-32768到32767,无符号0到65535, size 默认为 6。 MEDIUMINT(size) 带符号范围-8388608到8388607,无符号的范围是0到16777215。 size 默认为9 INT(size) 带符号范围-2147483648到2147483647,无符号的范围是0到4294967295。 size 默认为 11 BIGINT(size) 带符号的范围是-9223372036854775808到9223372036854775807,无符号的范围是0到18446744073709551615。size 默认为 20 FLOAT(size,d) 带有浮动小数点的小数字。在 size 参数中规定显示最大位数。在 d 参数中规定小数点右侧的最大位数。Float(4,2) DOUBLE(size,d) 带有浮动小数点的大数字。在 size 参数中规显示定最大位数。在 d 参数中规定小数点右侧的最大位数。 DECIMAL(size,d) 作为字符串存储的 DOUBLE 类型,允许固定的小数点。在 size 参数中规定显示最大位数。在 d 参数中规定小数点右侧的最大位数。 -
Date 类型
数据类型 描述 DATE() 日期。格式:YYYY-MM-DD **注释:**支持的范围是从 '1000-01-01' 到 '9999-12-31' DATETIME() *日期和时间的组合。格式:YYYY-MM-DD HH:MM:SS **注释:**支持的范围是从 '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59' TIMESTAMP() *时间戳。TIMESTAMP 值使用 Unix 纪元('1970-01-01 00:00:00' UTC) 至今的秒数来存储。格式:YYYY-MM-DD HH:MM:SS **注释:**支持的范围是从 '1970-01-01 00:00:01' UTC 到 '2038-01-09 03:14:07' UTC TIME() 时间。格式:HH:MM:SS **注释:**支持的范围是从 '-838:59:59' 到 '838:59:59' YEAR() 2 位或 4 位格式的年 **注释:**4 位格式所允许的值:1901 到 2155。2 位格式所允许的值:70 到 69,表示从 1970 到 2069。 -
AVG()函数返回数值列的平均值
SELECT AVG(column_name) FROM table_name -- 示例 select AVG(age) FROM number; -
COUNT() 函数返回匹配指定条件的行数
SELECT COUNT(column_name) FROM table_name; SELECT COUNT(*) FROM table_name; -- 示例 select count(*) from student; select count(name) from student; -
MAX() 函数返回指定列的最大值。
SELECT MAX(column_name) FROM table_name; -- 示例 select max(age) from student; -
MIN() 函数返回指定列的最小值
SELECT MIN(column_name) FROM table_name; -- 示例 select min(age) from student; -
SUM() 函数返回数值列的总数
SELECT SUM(column_name) FROM table_name; -- 示例 select sum(age) from student; -
ROUND() 函数用于把数值字段舍入为指定的小数位数
-
字符串处理函数
函数 功能 concat(s1, s2, … , sn) 连接s1, s2, …, sn 为一个字符串 insert(str, x, y, instr) 将字符串str从第x位置开始, y个字符长度的子字符串替换为字符串instr lower(str) 将字符串str中所有的字符转换为小写 upper(str) 将字符串str中所有的字符转换为大写 left(str, x) 返回字符串str最左边的x个字符 right(str, y) 返回字符串str最右边的y个字符 lpad(str, n, pad) 用字符串pad对str最左边进行填充, 直到长度为n个字符长度 rpad(str, n, pad) 用字符串pad对str最右边进行填充, 直到长度为n个字符长度 ltrim(str) 去掉str中最左边的空格 rtrim(str) 去掉str中最右边的空格 repeat(str, x) 返回str中重复出现x次的结果 replace(str, a, b) 将字符串str中的a更换为b strcmp(s1, s2) 比较字符串s1, s25 trim(str) 去掉字符串str两边的空格 substring(str, x, y) 返回字符串str x位置开始y个字符长度的字符串
-
-
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组
-
语法
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name; -- 示例 select xi,avg(age) from student where xi is not null and xi !="" GROUP BY xi;
-
-
HAVING 关键字
-
SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用
-
语法
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name HAVING aggregate_function(column_name) operator value; -- 示例,查找成绩总分大于200的学生 select name from number GROUP BY name HAVING sum(chengji)>200
-
-
高级查询
-
简单子查询:子查询是SELECT语句中另外一条SELECT语句,语句内出现表达式的地方都可以使用子查询,子查询可以从任何表中提取数据,只要对该表有适当的访问权限即可,通过在一个子查询或者另一个子查询内嵌套子查询,可以从两个或者多个表组合信息而不必编写复杂的整个组合表然后在过滤掉多余的或者不想管的联合查询的JOIN语句,子查询可以包含联合,WHERE子句、HAVING 子句和 GROUP BY 子句
-
语法规则:
- 子查询的SELECT必须用圆括弧括起来
- 不能包括 COMPUTE 或 FOR BROWSE 子句
- 如果同时指定TOP语句,则可能只包含 ORDER BY 语句
SELECT top 10 form table_name SELECT * from table_name limit 10,10 - 子查询最多可以嵌套32层
- 任何使用表达式的地方都可以使用子查询,只要他返回的是单个值
- 如果某个表只出现在子查询中而不出现在外部查询中那么该表的列就无法包含在输出中
```sql select * from A where A.列 in (select b.列 from B ) -- 子查询中没有告诉sql A表和B表有关联的情况下,B表的数据列不能出现在外部查询中 -
子查询常用的语法格式
- 第一种语法格式
- WHERE 查询表达式 [NOT] IN(子查询)
- 第二种语法方式
- WHERE 查询表达式 比较运算符[ANY | ALL] (子查询)
- 第三种语法方式
- WHERE [NOT] EXISTS(子查询)
- 第一种语法格式
-
子查询与其他的 SELECT 语句之间的区别(除必须在括弧中出现外)
- SELECT 语句只能使用那些来自 FROM 子句中的表中的列,子查询不仅可以使用在该子查询的FROM 子句中的表,而且还可以使用子查询的 FROM 子句中表的任何列
- SELECT 语句中的子查询必须是返回单一数据列(除from子句的子查询),根据在查询中的使用方法,(如将子查询结果用作包括子查询的 SELECT 子句中的一个数据项),包括子查询的查询可能要求子查询返回单个值(而不是来自单列的多个值)
- 子查询不能有 ORDER BY 子句(因为用户看不到返回多个数据值的子查询的结果表,所以对于隐藏的中间结果排序没有什么意义)
- 子查询必须是由一个 SELECT 语句组成,也就是不能将多个SQL语句用 UNION 组合起来作为一个子查询 外部查询只能有一个 select 剩余的全部在括弧里面
-
SELECT 列表中的子查询(子查询是 SELECT 查询内的返回一个值的表达式,就像返回值中的单个列一样,但是,在一个表达式中,子查询必须只返回一条记录,这样的子查询被称为标量子查询(scalar subquery),也必须被封闭在括弧中)
-
示例
根据图书的作者,获取不同作者编写的图书中价格最高的信息 SQL: SELECT tb_book_author, tb_author_department, ( SELECT MAX( book_price ) FROM tb_book WHERE tb_book_author.tb_book_author = tb_book.tb_book_author ) FROM tb_book_author; -
表:tb_book_author
tb_book_author tb_author_department tb_author_resume tb_book_author_id 潘一 PHP 程序设计 1 刘一 PHP 程序设计 2 郭一 C++ 应用程序开发 3 王一 C++ 应用程序开发 4 -
表:tb_book
tb_book_id book_name book_sort book_number book_price tb_book_author 1 PHP函数参考大全 PHP 1001-100-102 89.00 潘一 2 PHP示例宝典 PHP 1001-100-103 78.00 刘一 3 C++经验技术宝典 C++ 1001-101-101 79.00 王一 4 SQL Server开发技术大全 SQL数据库 1001-102-100 69.00 李一 5 PHP网络编程自学手册 PHP 1001-100-104 52.00 潘一 6 Visual C++从入门到精通 C++ 1001-101-101 89.00 郭一 -
SQL执行结果
tb_book_author tb_author_department (无列名) 潘一 PHP 89.00 刘一 PHP 78.00 郭一 C++ 89.00 王一 C++ 79.00
-
-
多列子查询(多列子查询就是返回值有多列)
-
示例:
-
person 表:
id name sex 1 小一 女 2 小二 男 3 小三 女 4 小四 男 5 小五 女 -
job表
id name sex 1 小二 男 2 小三 女 3 小四 男 SQL: SELECT * FROM person WHERE name IN (SELECT name FROM job); SELECT * FROM person WHERE (name,sex) IN (SELECT name,sex FROM job);
-
-
使用比较运算符连接子查询
-
在 WHERE 子句中可以使用单行比较运算符来比较某个表达式与子查询的结果,可以使用的比较运算符包括:=、>、>=、<、<=、<>、!=等这些运算符各连接一个子查询,但是返回的值只能是单个的值(子查询的列基本都要是函数);且在使用 ALL 或者 ANY 修饰的比较运算符连接子查询时,必须保证所返回的结果集中只有单行数据,否则查询报错
分析SQL: SELECT cat_id,good_name FROM goods WHERE cat_id>(SELECT cat_id FROM brand WHERE name = "iPhone") -
在子查询中使用聚合函数
-
聚合函数 SUM()、COUNT()、MAX()、MIN()、和 AVG()都返回的是单个值,在子查询中应用聚合函数,并将该函数返回的结果应用到WHERE 子句的查询条件中
示例:使用 MIN()函数获取 tb_min 表中 number1 和 number2 字段的最小值 SQL: ABS()绝对值 SELECT MIN(((number1+number2)-ABS(number1-number2))/2) AS 最小数 FROM (SELECT * FROM tb_min WHERE (number1>0 AND number2>0)) AS a; 示例:使用聚合函数 AVG() 求emp员工表中员工的平均工资,并将结果作为 WHERE 子句的查询条件,通过SQL获取工资大于平均工资的员工信息。 SQL: SELECT ename,sal,job FROM student.emp WHERE sal > (SELECT AVG(sal) FROM emp);
-
-
-
-
Maven安装部署
- 项目根目录如果包含pom.xml文件,此项目为maven项目(pom.xml是maven框架的配置文件)
- maven项目的目录结构
- src :里面存放的是java源码、前端文件
- target :maven的缓存文件包含打包后的.war文件
- pom.xml :maven的配置文件
- maven是一个开源的框架
- 服务器端Tomcat,是把我们使用java写的项目运行起来
- tomcat识别的文件为.war
- .war文件其实就是一个压缩包,里面包含的是Java的源文件
- mave打包
- 程序员写的代码存储在.java文件中,编译后的文件为.class文件
- mave就是把程序员写的.java文件编译成.class文件并压缩成一个.war的压缩包
- 安装maven
-
把下载好的maven压解压到当前文件夹
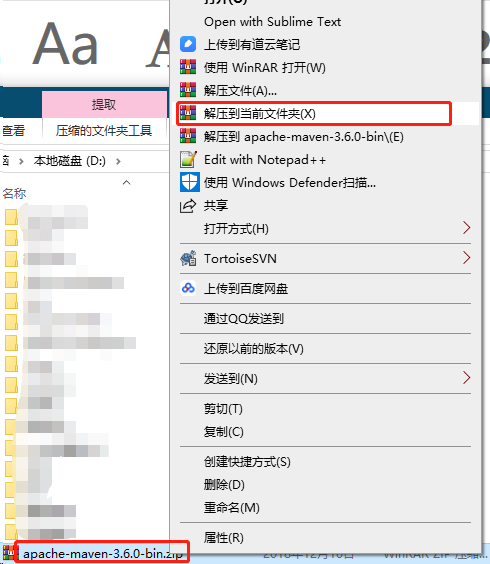
-
修改maven的中央仓库地址和jar包存放位置
- 进入apache-maven-3.6.0的根目录下的conf配置文件目录
- 修改我们maven的jar包存放位置
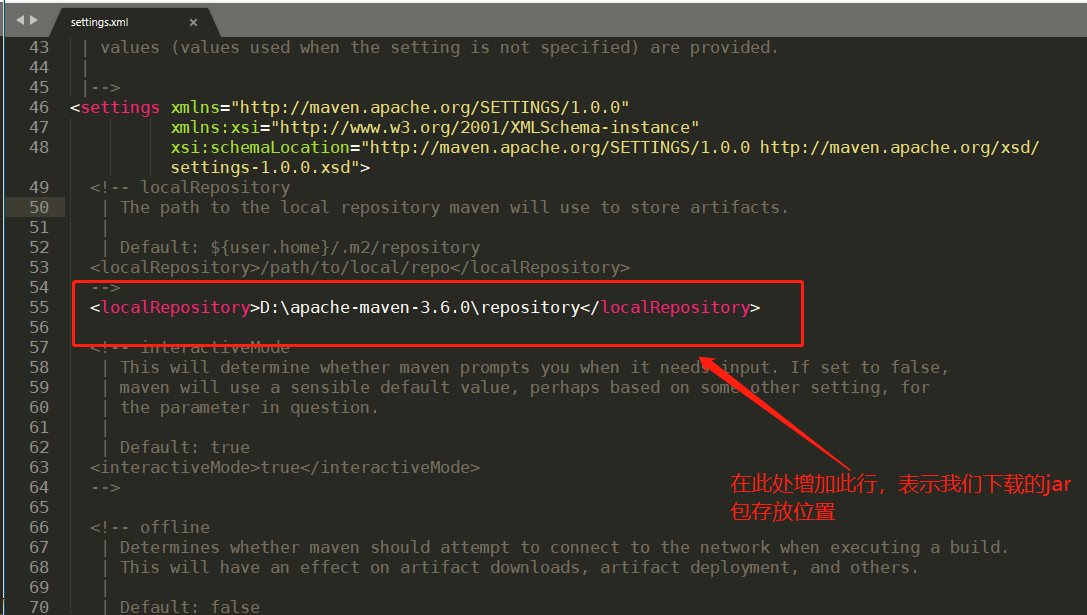
<!-- 我把下载的jar包仓库位置设置为maven的根目录下的repository文件夹,maven会自动创建对应文件夹 --> <localRepository>D:\apache-maven-3.6.0\repository</localRepository>- 配置maven的中央仓库地址
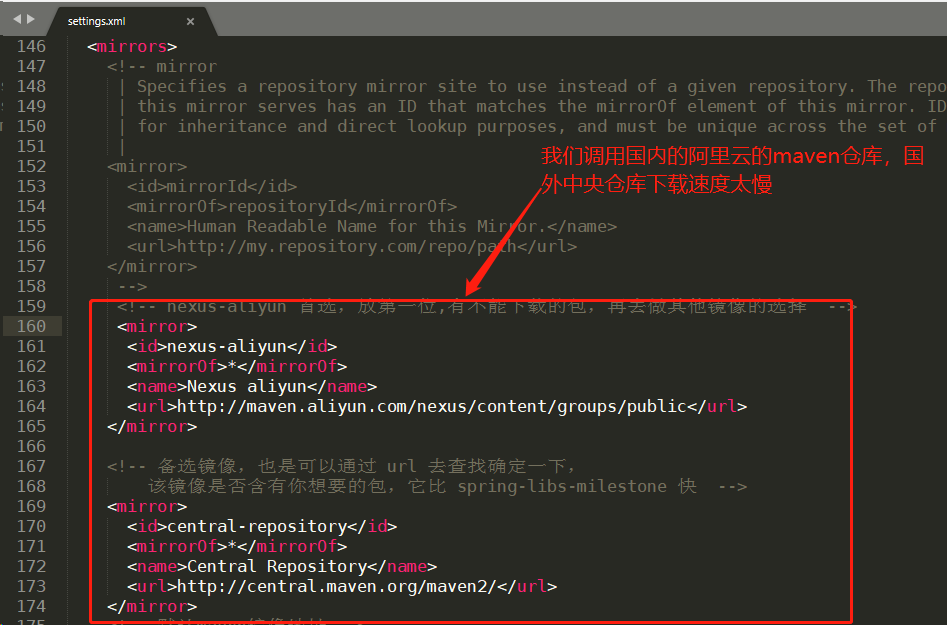
<mirror> <id>nexus-aliyun</id> <mirrorOf>*</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror> <!-- 备选镜像,也是可以通过 url 去查找确定一下,该镜像是否含有你想要的包,它比 spring-libs-milestone 快 --> <mirror> <id>central-repository</id> <mirrorOf>*</mirrorOf> <name>Central Repository</name> <url>http://central.maven.org/maven2/</url> </mirror>- 修改中央仓库地址
-
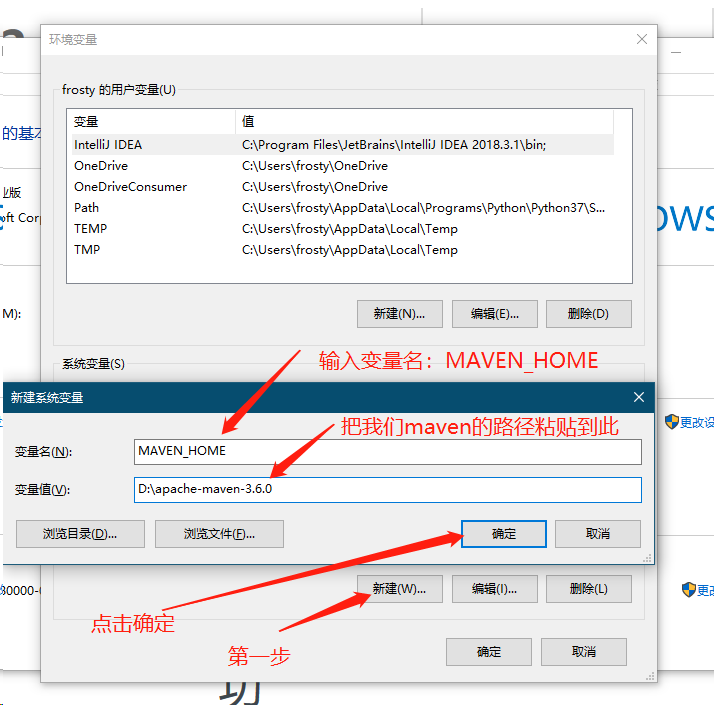
配置maven的环境变量(首先要保证自己电脑上已安装JDK且配置完环境变量)
- 找到我们解压后的maven的路径,且复制此路径
- 根据下图配置MAVEN_HOME
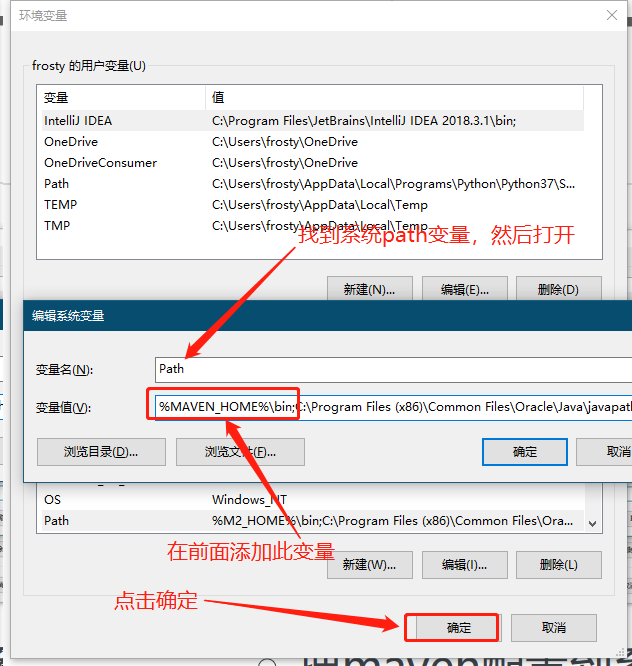
- 把maven(%MAVEN_HOME%\bin;)配置到系统 path变量中
-
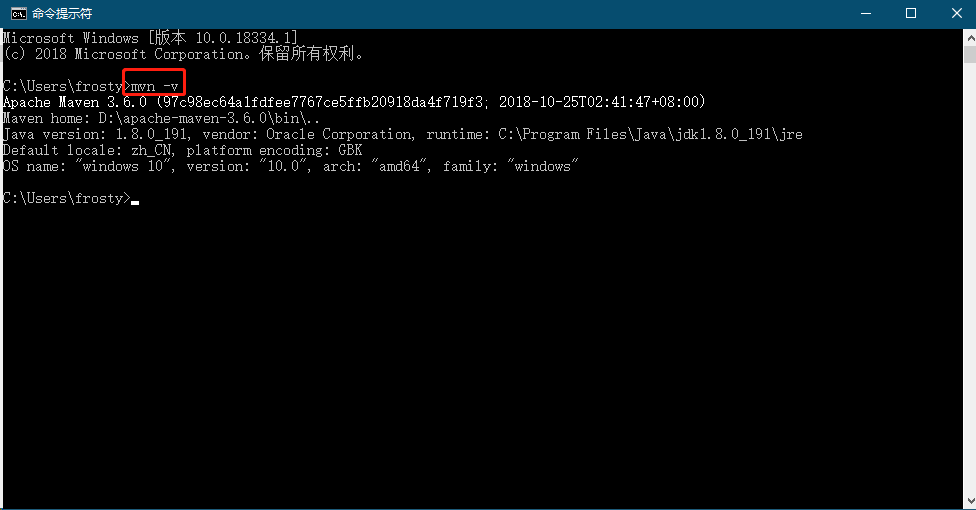
在cmd窗口使用mvn -v检查maven安装是否成功
-
使用maven进行打包
- mvn clean 清理:清理maven项目中的缓存和编译文件
- mvn package 打包:将源码文件打包为.war文件,对项目进行打包一定要在项目的根目录
- mvn test 执行单元测试命令
-
maven打包注事项:
- 所有对项目操作maven命令必须在项目的根目录下执行
- 打包前执行mvn clean对项目目录进行清理
- 电脑要安装JDK环境
-
Maven打包新三板项目,war包安装部署,修改配置文件
- 下载源码文件到本地
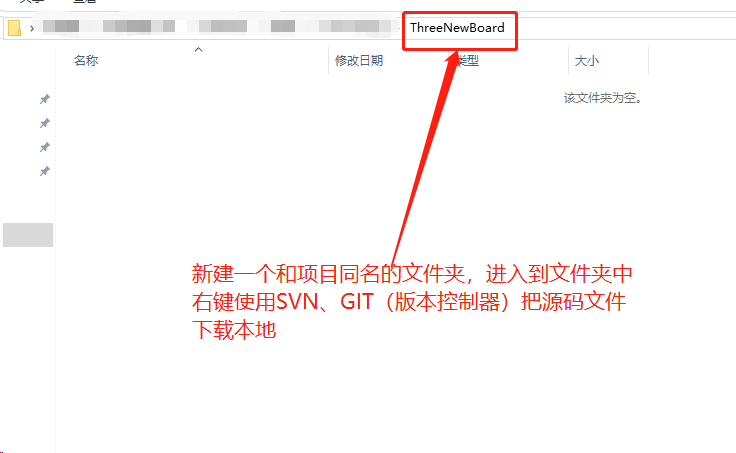
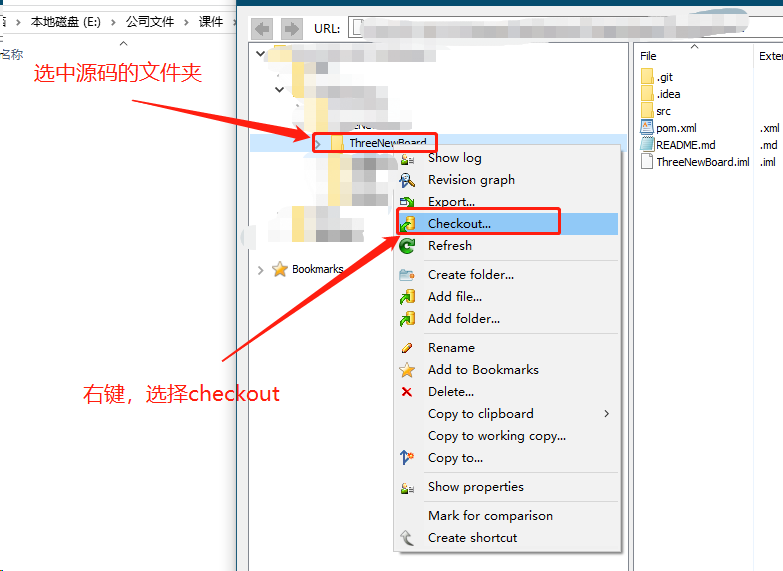
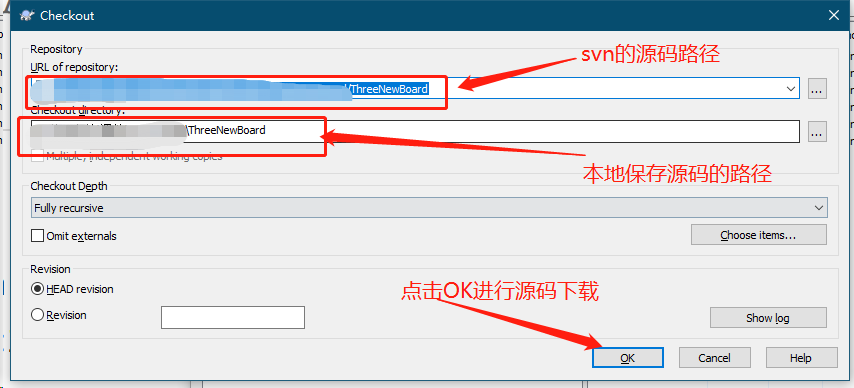
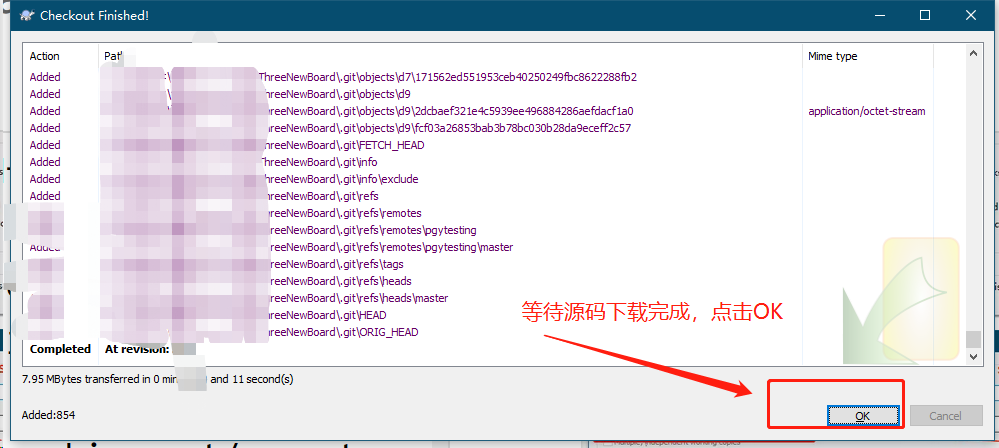
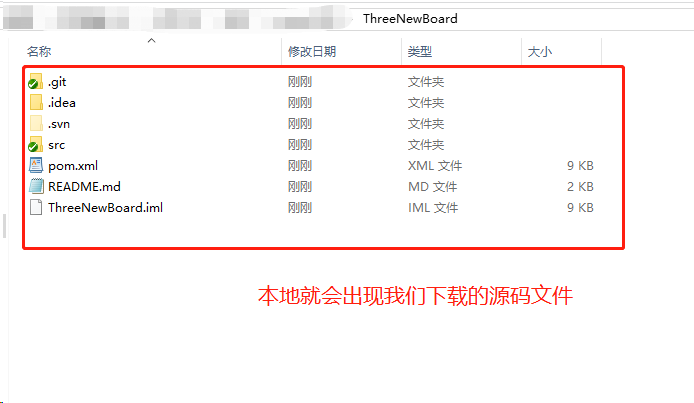
- 使用CMD命令窗口进入到源码存放的根目录

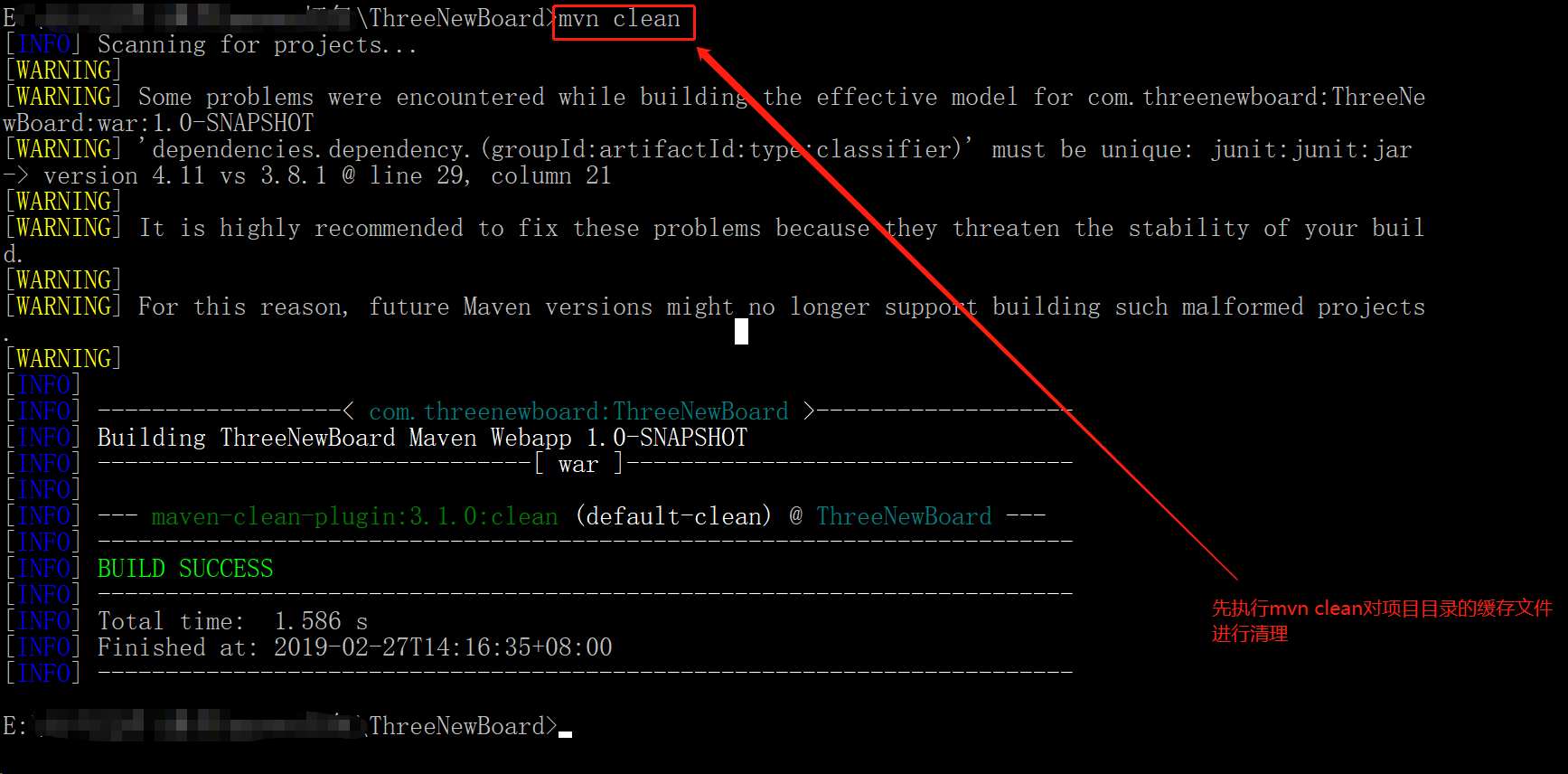
- 执行mvn clean 对项目缓存进行清理
- 执行mvn package命令进行maven项目打包

- 出现build success则打包成功

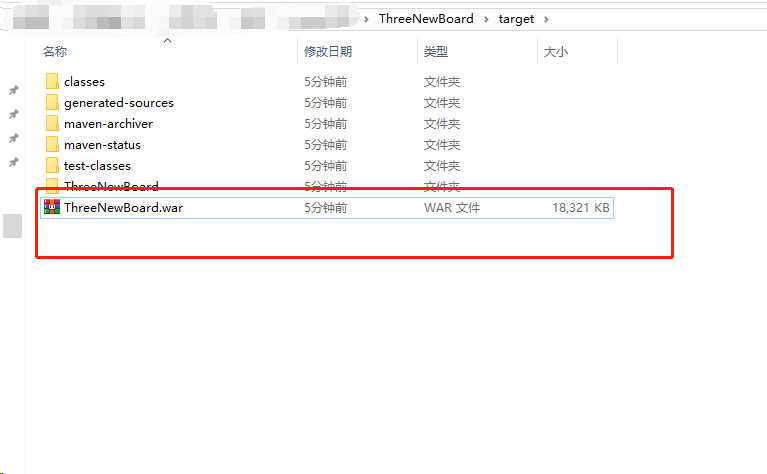
- 在项目根目录的target目录即可找到我们打好的war包
- 使用xshell连接需要部署的服务器
- 进入到我们已经部署好的tomcat/webapps目录下,使用rz命令进行war上传
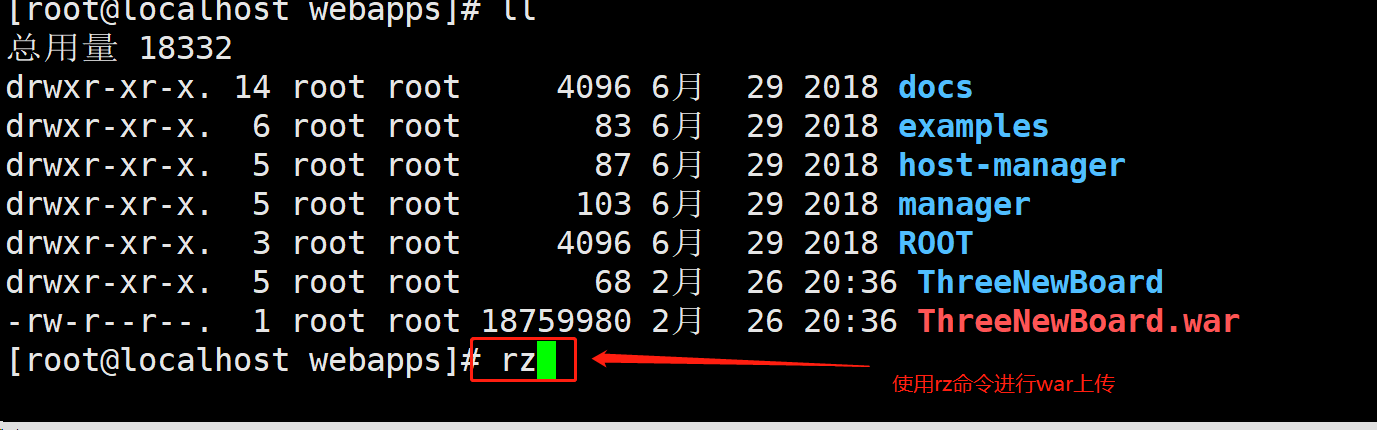
- 在tomcat的根目录中的bin目录下执行
./startup.sh启动tomcat,对war进行解压
- 进入到我们webapps目录下的项目目录中的classes目录下
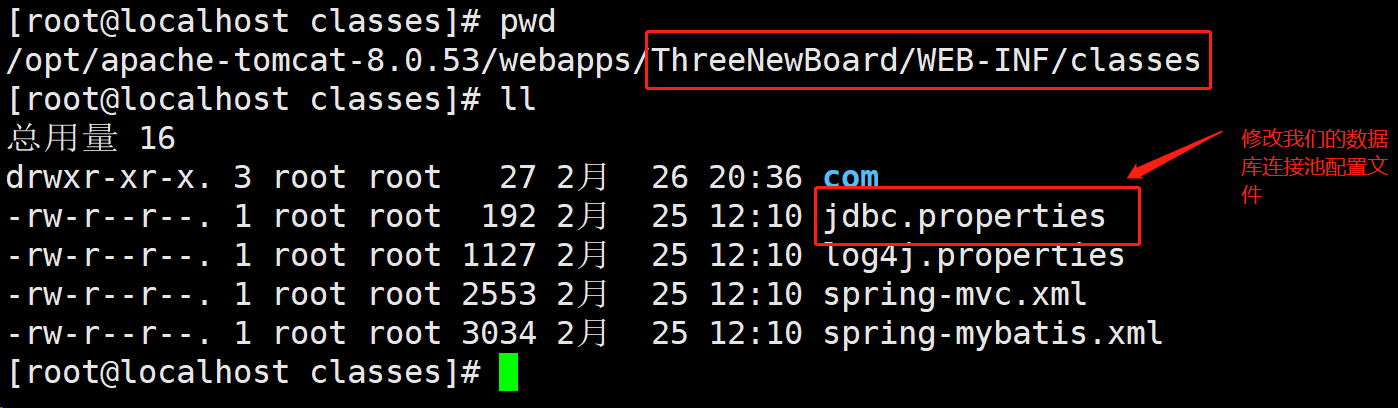
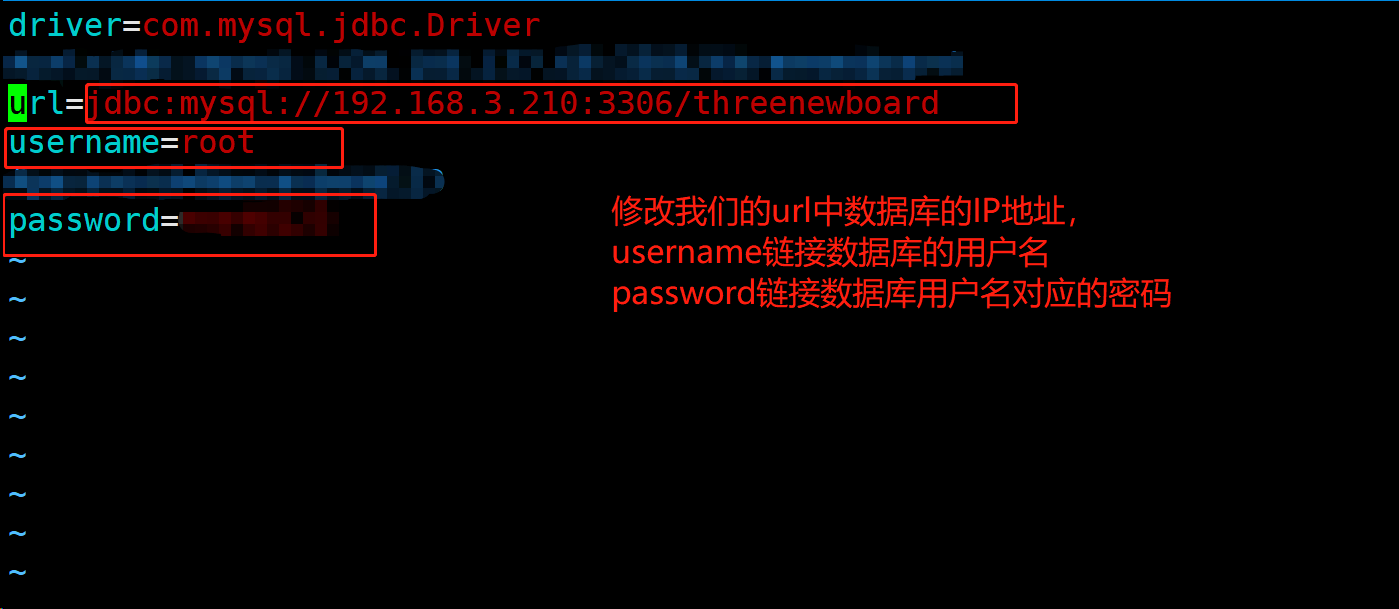
- 修改数据库链接池配置文件jdbc.properties
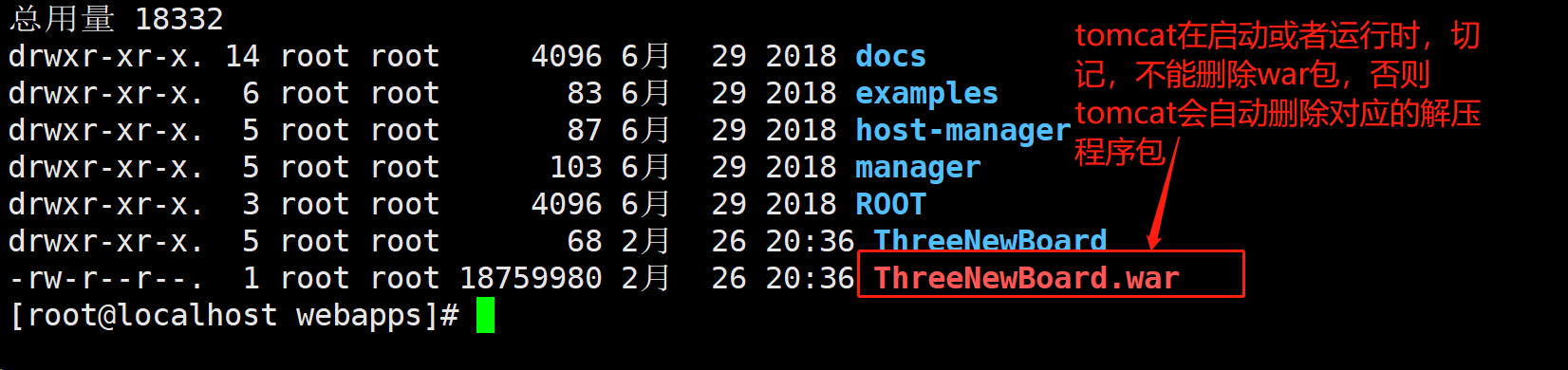
- 切记tomcat在运行状态下不可直接删除war包,否则war包对应的项目解压程序包也会被自动删除
- 使用
ps -ef | grep java查询到我们启动的tomcat的进程ID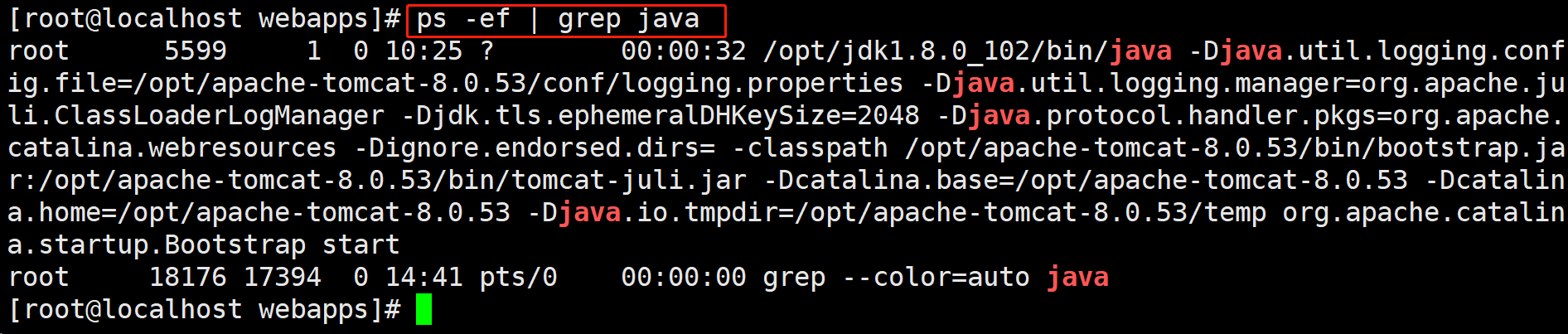
- 执行
kill -9 PID杀死tomcat的进程,执行ps -ef | grep java检查是否成功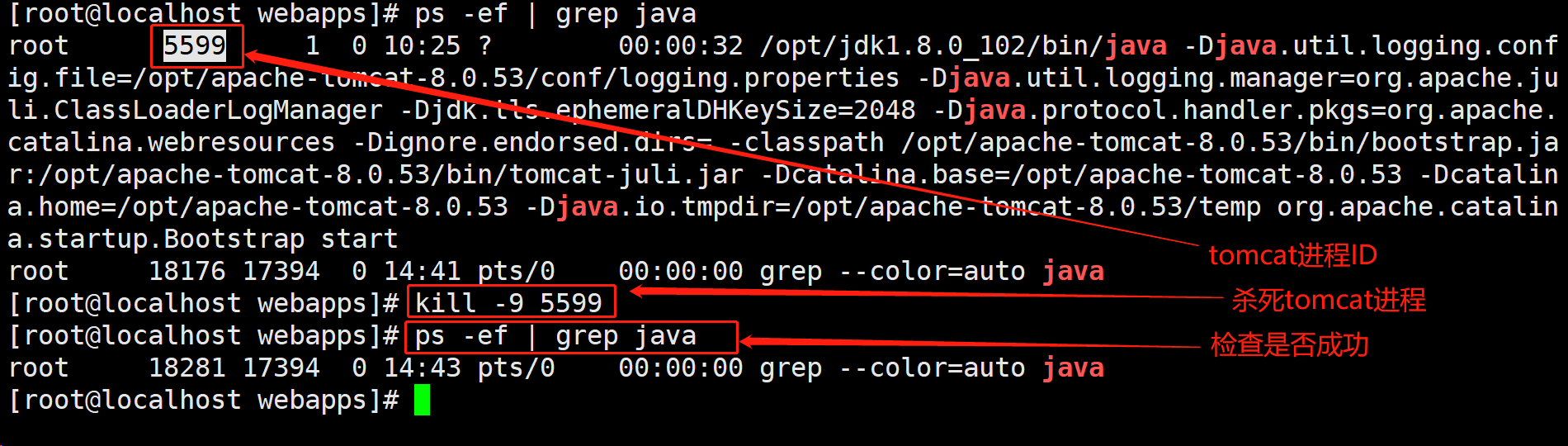
- 对war进行备份操作

- 进入tomcat根目录下的bin目录执行
./startup.sh启动tomcat
- 执行
ps -ef | grep java检查tomcat是否启动成功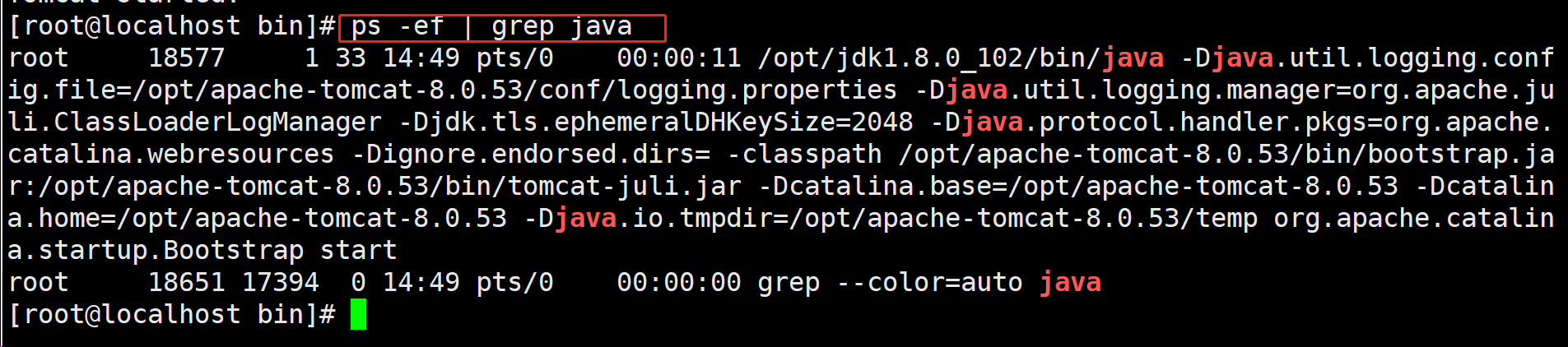















 3429
3429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









