






Pod是k8s调度的基本单位。每个Pod拥有自己独立的命名空间、网络接口以及共享磁盘等资源。同一个pod内的containers相互可见,并可以直接通讯。
为了理解Pod如何做到资源的隔离,我们需要了解容器技术依赖的两个Linux内核级功能:namespace & cgroups。
本来想自己写个文档简单介绍下cgroups的,结果发现自己估计怎么写都不可能有这个哥们好:
http://www.infoq.com/cn/articles/docker-kernel-knowledge-namespace-resource-isolation
http://www.infoq.com/cn/articles/docker-kernel-knowledge-cgroups-resource-isolation#
关于cgroups强烈建议阅读以上两篇文章。
补充
实践中,往往一个subsystem会绑定到一个hierarchy上,实现该种资源的控制。
在一台k8s的node节点上执行lssubsys -m,可以看到
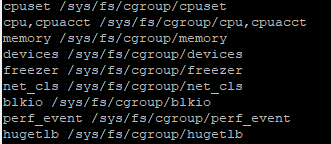
/sys/fs/cgroup下存在9个hierarchy,分别绑定了不同的subsystem。这几个hierarchy存在完全相同的目录结构,对于每个pod & container的限制存放在目录
/sys/fs/cgroup/{subsystem}/kubepods/pod{podUID}/{containerID} 下
这个节点上运行一个podUID=9eca1a96-2b23-11e8-9b0d-525400453ff7的pod,在/sys/fs/cgroup/memory/kubepods/pod9eca1a96-2b23-11e8-9b0d-525400453ff7/目录下我们可以看到
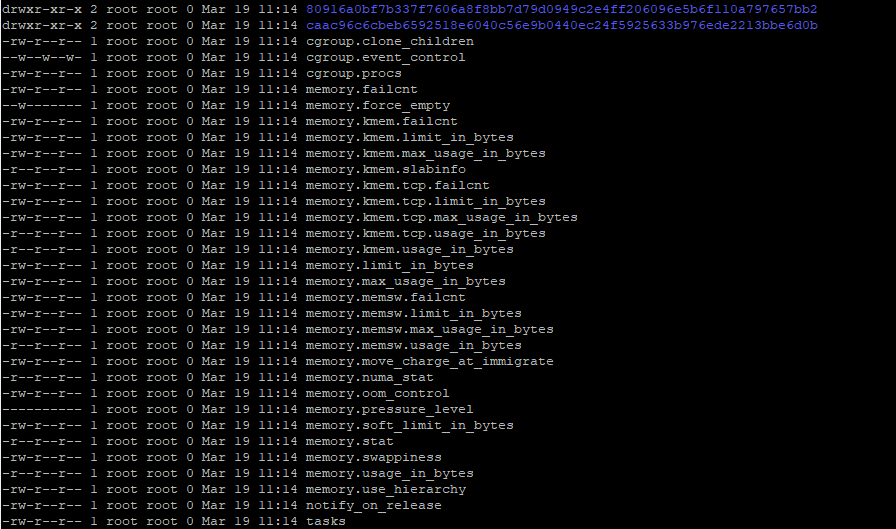
从目录结构中,可以看到该pod中运行着两个container。其中一个id=80916a0bf7b337f7606a8f8bb7d79d0949c2e4ff206096e5b6f110a797657bb2和工作containerID重合。另一个ID应该就代表sandbox container。
在工作containerID目录下,可以找到对该container的内存限制的配置。
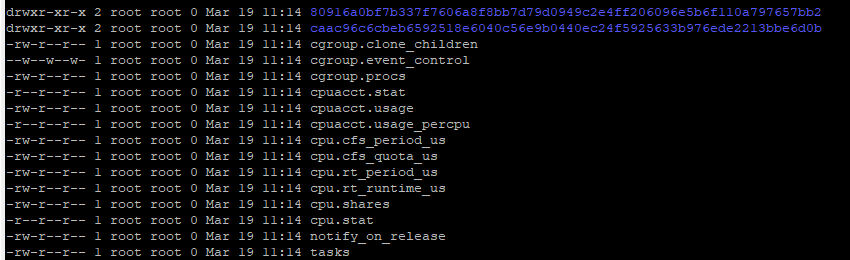
对于其他subsystem(cpu等),他们的目录结构完全相同,不同之处在于配置信息。
在/sys/fs/cgroup/cpu/kubepods/pod9eca1a96-2b23-11e8-9b0d-525400453ff7/目录下,我们可以发现以下内容:















 6000
6000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









