






接着第一节中的第一个示例,我们扩展第二个示例,将词法分析程序扩展为识别不同的词性。
下面是程序示例:
%{
/*
* 扩展第一个示例以识别其他的词性
*
*/
%}
%%
[ \t ]+ /* 忽略空白 */;
is |
am |
are |
were |
was |
be |
being |
been |
do |
does |
did |
will |
would |
should |
can |
could |
has |
had |
go {printf("%s: is a verb",yytext);}
very |
simply |
gently |
quietly |
calmly |
angrily {printf("%s: is an adverb",yytext);}
to |
from |
behind |
above |
below |
between {printf("%s: is a preposition",yytext);}
if |
then |
and |
but |
or {printf("%s: is a conjunction",yytext);}
their |
my |
your |
his |
her |
its {printf("%s : is an adjection",yytext);}
I |
you |
he |
she |
we |
they {printf("%s: is a pronoun",yytext);}
[a-zA-Z]+ {
printf("%s: do not recognize,mignt be a noun",yytext);
}
.| {ECHO; /* 通常的默认状态 */}
%%
int main()
{
yylex();
return 0;
}
int yywrap()
{
return 1;
}第二个示例实际上与第一个没有什么不同,仅仅就是列出了比前面更多的单词,原则上可以扩展这个示例为任意多的单词。但是这样感觉有些笨拙,如果是单词比较多的话,就需要将所有的单词都要列出来,如果能够有一个单词表,能够实时的添加新的单词的话,扩展性上就会好很多。下面我们再扩展一下,就是在词法分析程序运行时从输入文件中读取声明的单词时允许动态的声明词性。声明行以词性的名称开始,后面跟着要声明的单词。例如:
声明4个名词和3个动词:
noun dog cat horse cow
verb chew eat lick
该单词表在lex和yacc中就是一个简单的符号表,添加符号表可以完全改变词性语法分析程序,不必在词法分析程序中为每个要匹配的单词放置独立的模式,只要有一个匹配任意单词的模式,再查阅符号表就能决定所找到的词性。由于词性引入了一个声明行,所以他们现在是”保留字“。对于每一个保留字仍然有一个独立的lex模式。还必须添加符号表维护例程。add_word()表示添加单词,lookup_word()表示查询单词。
同时在程序代码中需要一个state变量用来记录是查找单词还是添加单词。无论如何只要我们看到以词性名字开始的行,就可以知道状态为添加单词,每次看到\n的时候,都切换回正常的查找状态。
下面是程序的实现:
%{
/* * 带符号表的单词识别程序 */
enum{
LOOKUP = 0, /* 默认-查找而不是定义 */
VERB,
ADJ,
ADV,
NOUN,
PREP,
PRON,
CONJ
};
int state;
int add_word(int type,char *word);
int lookup_word(char *word);
%}
%%
{state = LOOKUP;} /* 行结束,返回默认状态 */
/* 无论何时return wp->word_type,行都以保留的词性名字开始 */
/* 开始定义该类型的单词 */
^verb {state = VERB; }
^adj {state = ADJ; }
^adv {state = ADV; }
^noun {state = NOUN; }
^prep {state = PREP; }
^pron {state = PRON; }
[a-zA-Z]+ {
/* 一个标准的单词,定义他或查找它 */
if(state != LOOKUP){
/* 定义当前单词 */
add_word(state,yytext);
}else{
switch(lookup_word(yytext)){
case VERB: printf("%s: verb",yytext); break;
case ADJ: printf("%s: adjective",yytext); break;
case ADV: printf("%s: adverb",yytext); break;
case NOUN: printf("%s: noun",yytext); break;
case PREP: printf("%s: preposition",yytext); break;
case PRON: printf("%s: pronoun",yytext); break;
case CONJ: printf("%s: conjunction",yytext); break;
default:
printf("%s: do not recognize",yytext);
break;
}
}
}
. /* 忽略其他return wp->word_type的东西 */
%%
int main()
{
yylex();
return 0;
}
/* 定义一个单词和类型的链表 */
struct word{
char *word_name;
int word_type;
struct word *next;
};
struct word *word_list; /* 单词链表中的第一个元素 */
extern void *malloc();
int add_word(int type,char *word)
{
struct word *wp;
if(lookup_word(word) != LOOKUP){
printf("!! warning: word %s already defined",word);
return 0;
}
/* 单词不在那里,分配一个新的条目并将它链接到链表上 */
wp = (struct word *)malloc(sizeof(struct word));
wp->next = word_list;
/* 还必须复制单词本身 */
wp->word_name = (char *)malloc(strlen(word)+1);
strcpy(wp->word_name,word);
wp->word_type = type;
word_list = wp;
return 1; /* 添加成功 */
}
int lookup_word(char *word)
{
struct word *wp = word_list;
/* 向下搜索列表以寻找单词 */
for(;wp;wp = wp->next){
if(strcmp(wp->word_name,word) == 0)
return wp->word_type;
}
return LOOKUP;
}
int yywrap()
{
return 1;
}
下面是我的程序的输出结果: 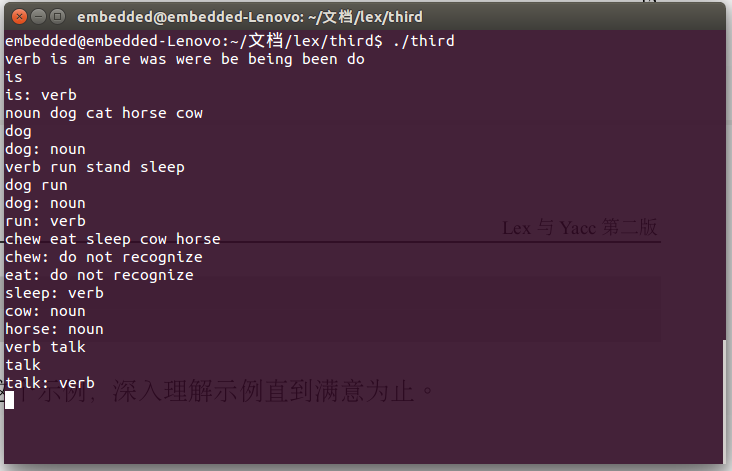















 2450
2450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









