






数据仓库设计维度表时涉及缓慢变化维,针对缓慢变化维,根据业务场景,有两种设计:其一覆盖更新,其二新增插入。针对第一种情况可以实行全面覆盖更新,针对第二种情况可以采取每日的全量备份和拉链表。每日全量备份有很多相同的数据信息,对存储空间是极大的浪费,全面覆盖更新就难以查询历史状态,而拉链表就是为了保留历史数据,又节省空间而设计的一种模式。
另外拉链表的一个优化设计是增加标记最新记录的字段,对于不需要考虑历史数据的场景亦适用。至于为什么不用expire_date来判断最新状态,我举个简单的例子做说明:比如将员工表设计成一个拉链表:那么当一个员工离职时,就会将离职员工最新记录的expire_date更新为离职日期,为了筛选出每个员工的最新记录,我就需要分情况处理,一是expire_date='9999-12-31'的情况,二是expire_date=leave_date的情况,没有增加标记字段来得方便。
- 拉链表的实现流程
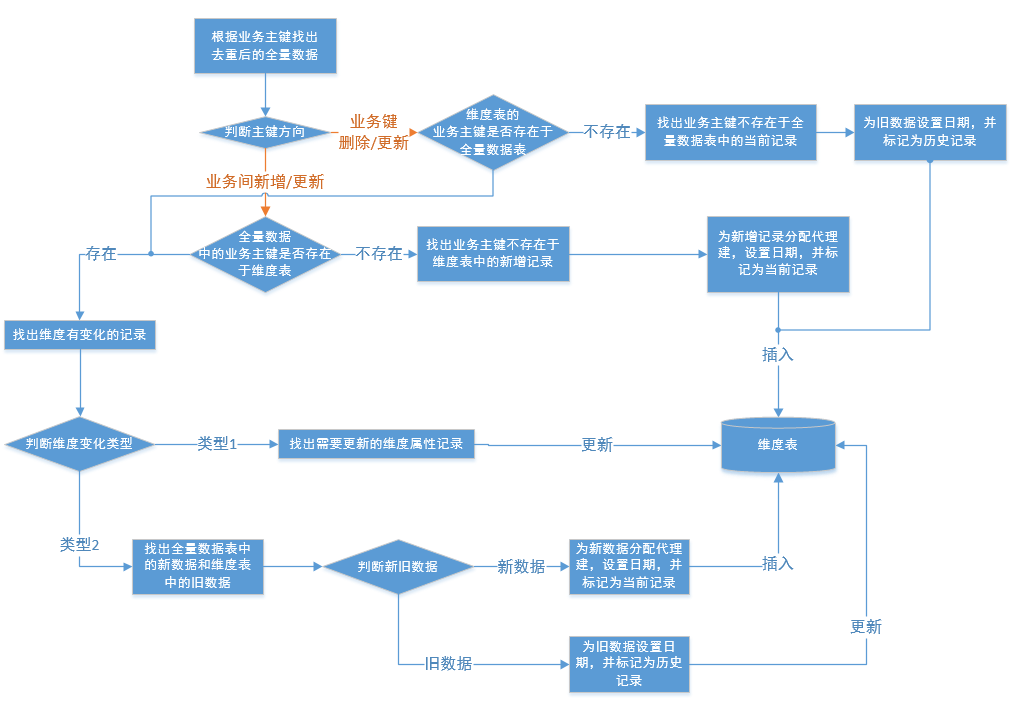
- 拉链表的设计思路
思路一:
1、将ODS的数据全量存储在临时表1中;
2、将维度表的最新数据(通过当前记录标记判断)和临时表1通过业务主键做左关联,在维度表中找出缓慢变化维有变化和不存在于临时表1的业务数据的代理主键,将这部分数据(包含历史维度表的主键)存储在临时表2中;
3、找出临时表1中需要更新(业务主键存在于维度表且标记为维度表当前记录)和新增的数据(业务主键不存在于维度表)插入到维度表中;
4、根据临时表2的代理主键,更新维度表的expire_date为pre_date;
思路二:
1、将ODS的数据全量存储在临时表1中;
2、将维度表的最新数据(通过当前记录标记判断)和临时表1通过业务主键做左关联,在维度表中找出缓慢变化维有变化和不存在于临时表1的业务数据,将这部分数据的expire_date更新为pre_date,并变更为历史记录;
3、找出临时表1中需要更新(每个业务主键的最后一条记录)和新增的数据(业务主键不存在于维度表)插入到维度表中;
思路三:
1、将ODS的数据全量存储在临时表1中;
2、找出临时表1中需要更新和新增的数据插入到维度表中;
3、根据维度表中同一个业务主键,相同expire_date有两条的数据,更新valid_date早的记录的expire_date;
4、在维度表中找出不存在于临时表1的业务主键,更新这些业务主键对应最新记录为历史记录;
- 拉链表实现方式
第一步都是实现维度表的全量加载:
1、kettle
在kettle中实现了思路三的方式
1.1 第一个转换,更新和新增的数据插入到历史维度表
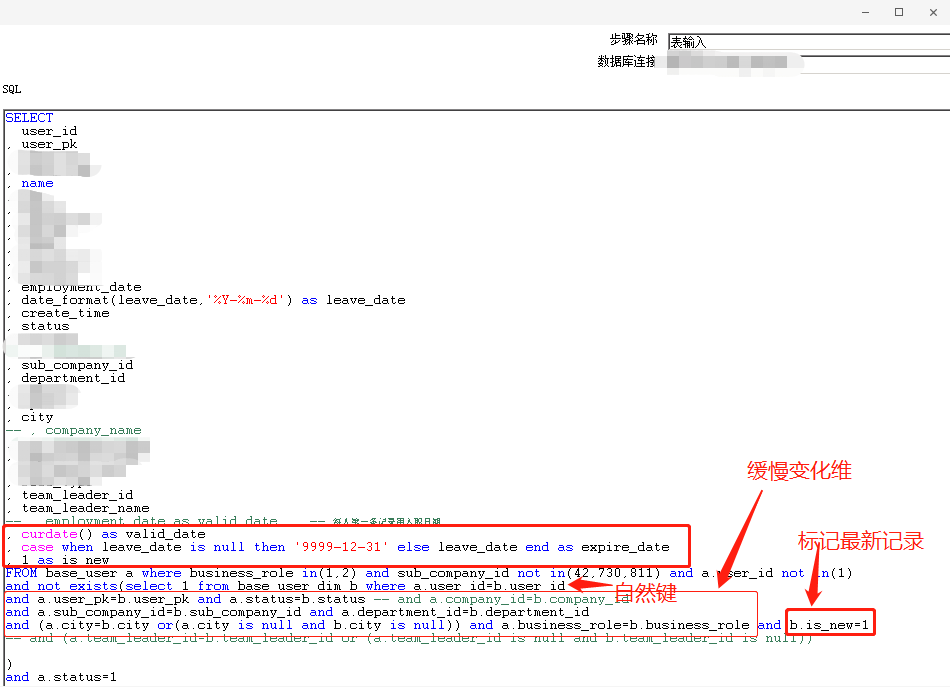

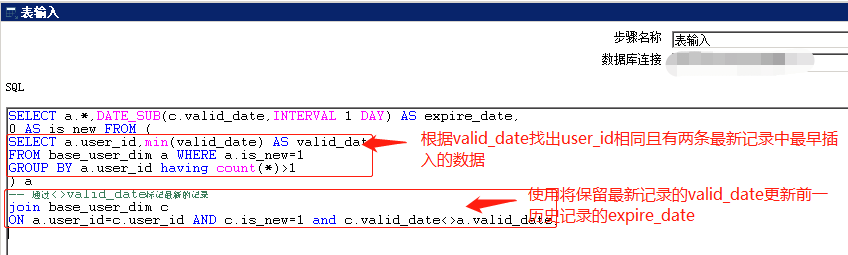
1.2 第二个转换,根据历史维度表中同一个自然键,相同end_date有两条的数据,更新start_date早的记录的end_date;
2、mysql存储过程
实现思路一的方式
/*
user_id是业务主键,sub_company_id,department_id,team_leader_id是三个需要新增的缓慢变化维
*/
CREATE PROCEDURE `base_user_dim`()
BEGIN
declare max_date VARCHAR(50) DEFAULT '9999-12-31';
declare pre_date VARCHAR(50) DEFAULT DATE_FORMAT(CURDATE()-1,'%Y-%m-%d');
delete from base_user_dim_tmp1;
/*
将有更新的记录在tmp1中,后续更新其expire_date
*/
insert into base_user_dim_tmp1
select a.id,a.user_id from base_user_dim a
left join base_user b on a.user_id=b.user_id
where a.is_new=1 and (b.user_id is null or a.sub_company_id<>b.sub_company_id or a.department_id<>b.department_id or a.team_leader_id<>b.team_leader_id);
/*
插入新增(b.user_id is null)和更新的数据(a.sub_company_id<>b.sub_company_id or a.department_id<>b.department_id or a.team_leader_id<>b.team_leader_id)
*/
insert into base_user_dim(user_id,name,sub_company_id,department_id,sub_company_name,
department_name,team_leader_id,team_leader_name,valid_date,expire_date,is_new)
select a.user_id,a.name,a.sub_company_id,a.department_id,a.sub_company_name,
a.department_name,a.team_leader_id,a.team_leader_name,curdate() as valid_date
, case when leave_date is null then max_date else leave_date end as expire_date,a.is_new
from base_user a left join base_user_dim b
on a.user_id=b.user_id and b.is_new=1
where a.business_role in(1,2) and a.sub_company_id not in(42,730,811) and a.user_id<>1 and a.`status`=1 and
(b.user_id is null or(a.sub_company_id<>b.sub_company_id or a.department_id<>b.department_id or a.team_leader_id<>b.team_leader_id));
/*
更新tmp1中数据的expire_date
*/
update base_user_dim set expire_date=pre_date,is_new=0 where id in(select id from base_user_dim_tmp1);
END
3、hive
实现思路二的方式
3.1 使用hive事务的方式
<!-- 设置hive支持事务
如果一个表要实现update和delete功能,该表就必须支持ACID,而支持ACID,就必须满足以下条件:
1、表的存储格式必须是ORC(STORED AS ORC);
2、表必须进行分桶(CLUSTERED BY (col_name, col_name, …) INTO num_buckets BUCKETS);
3、Table property中参数transactional必须设定为True(tblproperties(‘transactional’=‘true’));
-->
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.in.test</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
-- ---------------------初始化开始----------------------------------------------------------------------------------------------------
-- 如果一个表要实现update和delete功能,该表就必须支持ACID,而支持ACID,就必须满足以下条件:
-- 1、表的存储格式必须是ORC(STORED AS ORC);
-- 2、表必须进行分桶(CLUSTERED BY (col_name, col_name, …) INTO num_buckets BUCKETS);
-- 3、Table property中参数transactional必须设定为True(tblproperties(‘transactional’=‘true’));
-- 先导入到hdfs
create table base_user_dim2(
`id` int COMMENT '客户ID',
`user_id` int COMMENT '用户id',
`name` string COMMENT '用户姓名',
`sub_company_id` int COMMENT '分公司id',
`department_id` int COMMENT '部门id',
`sub_company_name` string COMMENT '所属分公司',
`department_name` string COMMENT '所属部门',
`team_leader_id` int COMMENT '团队长ID',
`team_leader_name` string COMMENT '团队长名字',
`valid_date` date COMMENT '有效期',
`expire_date` date COMMENT '到期日',
`is_new` int COMMENT '是否最新'
)clustered by (id) into 2 buckets
ROW FORMAT DELIMITED FIELDS TERMINATED BY '$' LINES TERMINATED BY '\n' STORED AS orc TBLPROPERTIES('transactional'='true');
sqoop import \
--connect jdbc:mysql://118.31.79.185:3306/crm_cronus \
--driver com.mysql.jdbc.Driver \
--username fang_read \
--password read2wsx \
--split-by user_id \
--query 'select user_id,name,sub_company_id,department_id,sub_company_name,department_name,team_leader_id,team_leader_name,entry_date as valid_date,'9999-12-31' as expire_date,1 as is_new from fangdb.base_user where $CONDITIONS' \
--target-dir base_user_tmp1 \
--fields-terminated-by '$' -m 3 \
--lines-terminated-by '\n'
-- load数据到base_user_tmp1
LOAD DATA INPATH 'hdfs://sjzx1:9000/user/hadoop/base_user_tmp1' overwrite INTO TABLE base_user_tmp1;
-- 产生代理建,自增主键
insert into base_user_dim2
select rank() over(order by user_id,valid_date) as rk,a.*
from base_user_tmp1 a;
-----------------------初始化结束----------------------------------------------------------------------------------------------------
-- 修改
sqoop import \
--connect jdbc:mysql://118.31.79.185:3306/crm_cronus \
--driver com.mysql.jdbc.Driver \
--username fang_read \
--password read2wsx \
--split-by user_id \
--query 'select user_id,name,sub_company_id,department_id,sub_company_name,department_name,team_leader_id,team_leader_name,curdate() as valid_date,'9999-12-31' as expire_date,1 as is_new from fangdb.base_user where business_role in(1,2) and sub_company_id not in(42,730,811) and user_id<>1 and status=1 and $CONDITIONS' \
--target-dir base_user_tmp1 \
--fields-terminated-by '$' -m 3 \
--lines-terminated-by '\n'
-- load数据到base_user_tmp1
LOAD DATA INPATH 'hdfs://sjzx1:9000/user/hadoop/base_user_tmp1' overwrite INTO TABLE base_user_tmp1;
-- 需要更新的数据
CREATE TEMPORARY TABLE mid as
select a.id
from base_user_dim2 a
left join base_user_tmp1 b on a.user_id=b.user_id
where a.is_new=1 and (b.user_id is null or a.sub_company_id<>b.sub_company_id or a.department_id<>b.department_id or a.team_leader_id<>b.team_leader_id);
-- 新增的数据
insert into base_user_dim2
select rank() over(order by a.user_id)+rk_max as id,a.* from(
select a.user_id,a.name,a.sub_company_id,a.department_id,a.sub_company_name,a.department_name,a.team_leader_id,a.team_leader_name, a.valid_date,a.expire_date,a.is_new
from base_user_tmp1 a
left join base_user_dim b on a.user_id=b.user_id and b.is_new=1
where (b.user_id is null or a.sub_company_id<>b.sub_company_id or a.department_id<>b.department_id or a.team_leader_id<>b.team_leader_id )
)a cross join (select coalesce(max(id),0) as rk_max from base_user_dim) b;
-- 更新需要更新的数据,expire_date更新为前一天,is_new更新为0
update base_user_dim2 set expire_date=date_add(current_date,-1),is_new=0
where exists (select 1 from mid b where base_user_dim2.id=b.id);
-- -------- 待定 第二步没有排除全部需要插入的数据,待优化------------------------------------------------
-- 更新需要更新的数据,expire_date更新为前一天,is_new更新为0,其中b.user_id is null表示已经删除的用户,
-- a.sub_company_id<>b.sub_company_id or a.department_id<>b.department_id or
-- a.team_leader_id<>b.team_leader_id表示变更的数据
update base_user_dim2 set expire_date=date_add(current_date,-1),is_new=0
where exists (select 1 from (
select a.id
from base_user_dim2 a
left join base_user_tmp1 b on a.user_id=b.user_id
where a.is_new=1 and (b.user_id is null or a.sub_company_id<>b.sub_company_id or a.department_id<>b.department_id or a.team_leader_id<>b.team_leader_id)
) b where base_user_dim2.id=b.id);
-- 新增的数据,其中b.user_id is null表示已经新增的用户,a.sub_company_id<>b.sub_company_id or
-- a.department_id<>b.department_id or a.team_leader_id<>b.team_leader_id表示变更的数据
insert into base_user_dim2
select rank() over(order by a.user_id)+rk_max as id,a.* from(
select a.user_id,a.name,a.sub_company_id,a.department_id,a.sub_company_name,a.department_name,a.team_leader_id,a.team_leader_name, a.valid_date,a.expire_date,a.is_new
from base_user_tmp1 a
left join base_user_dim2 b on a.user_id=b.user_id and b.is_new=0 and b.expire_date=date_add(current_date,-1)
where (b.user_id is null or a.sub_company_id<>b.sub_company_id or a.department_id<>b.department_id or a.team_leader_id<>b.team_leader_id )
)a cross join (select coalesce(max(id),0) as rk_max from base_user_dim) b;
-- -------- 待定 ------------------------------------------------------------------------------
3.2 不使用hive事务的方式
-- ---------------------初始化开始----------------------------------------------------------------------------------------------------
create table base_user_dim(
`id` int COMMENT '客户ID',
`user_id` int COMMENT '用户id',
`name` string COMMENT '用户姓名',
`sub_company_id` int COMMENT '分公司id',
`department_id` int COMMENT '部门id',
`sub_company_name` string COMMENT '所属分公司',
`department_name` string COMMENT '所属部门',
`team_leader_id` int COMMENT '团队长ID',
`team_leader_name` string COMMENT '团队长名字',
`valid_date` date COMMENT '有效期',
`expire_date` date COMMENT '到期日',
`is_new` int COMMENT '是否最新'
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '$' LINES TERMINATED BY '\n' STORED AS textfile;
create table base_user_tmp1(
`user_id` int COMMENT '用户id',
`name` string COMMENT '用户姓名',
`sub_company_id` int COMMENT '分公司id',
`department_id` int COMMENT '部门id',
`sub_company_name` string COMMENT '所属分公司',
`department_name` string COMMENT '所属部门',
`team_leader_id` int COMMENT '团队长ID',
`team_leader_name` string COMMENT '团队长名字',
`valid_date` date COMMENT '有效期',
`expire_date` date COMMENT '到期日',
`is_new` int COMMENT '是否最新'
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '$' LINES TERMINATED BY '\n' STORED AS textfile;
-- 先导入到hdfs
sqoop import \
--connect jdbc:mysql://118.31.79.185:3306/crm_cronus \
--driver com.mysql.jdbc.Driver \
--username fang_read \
--password read2wsx \
--split-by user_id \
--query 'select user_id,name,sub_company_id,department_id,sub_company_name,department_name,team_leader_id,team_leader_name,entry_date as valid_date,'9999-12-31' as expire_date,1 as is_new from fangdb.base_user where $CONDITIONS' \
--target-dir base_user_tmp1 \
--fields-terminated-by '$' -m 3 \
--lines-terminated-by '\n'
-- load数据到base_user_tmp1
LOAD DATA INPATH 'hdfs://sjzx1:9000/user/hadoop/base_user_tmp1' overwrite INTO TABLE base_user_tmp1;
-- 产生代理建,自增主键
insert into base_user_dim
select rank() over(order by user_id,valid_date) as rk,
a.*
from base_user_tmp1 a;
-- ---------------------初始化结束----------------------------------------------------------------------------------------------------
-- ---------------------定时任务开始----------------------------------------------------------------------------------------------------
hadoop fs -rm -r /user/hadoop/base_user_tmp1
-- 修改
sqoop import \
--connect jdbc:mysql://118.31.79.185:3306/crm_cronus \
--driver com.mysql.jdbc.Driver \
--username fang_read \
--password read2wsx \
--split-by user_id \
--query 'select user_id,name,sub_company_id,department_id,sub_company_name,department_name,team_leader_id,team_leader_name,curdate() as valid_date,'9999-12-31' as expire_date,1 as is_new from fangdb.base_user where business_role in(1,2) and sub_company_id not in(42,730,811) and user_id<>1 and status=1 and $CONDITIONS' \
--target-dir base_user_tmp1 \
--fields-terminated-by '$' -m 3 \
--lines-terminated-by '\n'
-- load数据到base_user_tmp1
LOAD DATA INPATH 'hdfs://sjzx1:9000/user/hadoop/base_user_tmp1' overwrite INTO TABLE base_user_tmp1;
-- 更新需要更新的数据mid1
CREATE TEMPORARY TABLE mid1 as
select a.id,a.user_id,a.name,a.sub_company_id,a.department_id,a.sub_company_name,a.department_name,a.team_leader_id,a.team_leader_name,a.valid_date,date_add(current_date,-1) as expire_date,0 as is_new
from base_user_dim a
left join base_user_tmp1 b on a.user_id=b.user_id
where a.is_new=1 and (b.user_id is null or a.sub_company_id<>b.sub_company_id or a.department_id<>b.department_id or a.team_leader_id<>b.team_leader_id);
-- 不变的数据 hive没有in
CREATE TEMPORARY TABLE mid2 as
select * from base_user_dim a
where not exists(select 1 from mid1 b where a.id=b.id);
-- 新增的数据
CREATE TEMPORARY TABLE mid3 as
select rank() over(order by a.user_id)+rk_max as id,a.* from(
select a.user_id,a.name,a.sub_company_id,a.department_id,a.sub_company_name,a.department_name,a.team_leader_id,a.team_leader_name, a.valid_date,a.expire_date,a.is_new
from base_user_tmp1 a
left join base_user_dim b on a.user_id=b.user_id and b.is_new=1
where (b.user_id is null or a.sub_company_id<>b.sub_company_id or a.department_id<>b.department_id or a.team_leader_id<>b.team_leader_id )
)a cross join (select coalesce(max(id),0) as rk_max from base_user_dim) b;
-- 全量覆盖目标表
INSERT overwrite table base_user_dim select * from mid1;
INSERT into base_user_dim select * from mid2;
INSERT into base_user_dim select * from mid3;
-- ---------------------定时任务结束-------------------------------------------------------------------------------------------------















 5510
5510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









