






Java集合是用来存放对象,那么它是如何存放,它的原理是什么?作为一名Java开发工程师,这些原理都是否真的了解?
Java的集合框架可以理解为数据结构,它的内容主要是栈、队列、Hash表等存放的内容。
因此集合则可以理解为是一种存储对象的容器,使用Java集合框架的算法原理进行存放。
同数组相比
集合的优势在于他的长度是可以变化;
集合可以存储多个类型的对象,而数组的长度是固定的,只能存储一个类型的元素;
集合不能存储基本数据类型,而数组却可以。
所有的集合类都是Collection接口的子类。实现Collection中定义的集合共有功能。
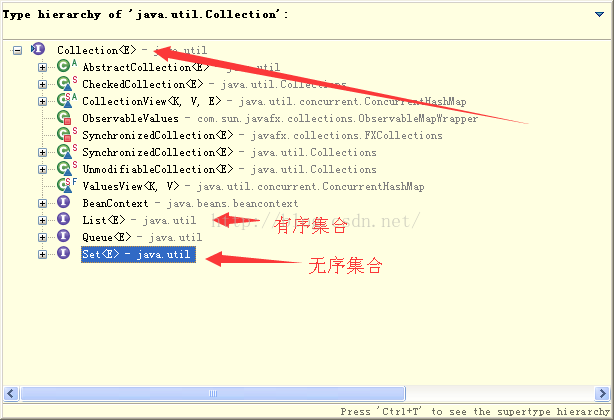
Collection有两个子类接口一个是List接口,一个是Set接口。List接口的子类集合是有序集合,可以根据集合中的角标对集合中元素进行操作,可以存在相同元素。而Set接口的子类集合是无序集合,但是他不允许存在相同的元素。
List接口子类所共有的方法其实就是在Collection的方法基础上增加了角标的操作。
List接口
List接口下有三个子类,分别是ArrayList,LinkedList,Vector。
ArrayList底层是数组结构,所以如果数据较大查询的效率较高,但也正因如此,他每次添加或者删除元素,都相当于重建了一个数组,所以如果集合中频繁有增删操作,建议使用LinkedList。线程不同步。方法基本都继承自List。
LinkedList底层是链表结构,每一个元素都是跟自己前一个和后一个元素发生关系,所以他的增删操作只需要改变与其位置相关联的两个元素关系即可,所以效率比较高,但是如果角标读取的话就要从1角标开始计算,所以如果集合中频繁有读取操作,建议使用ArrayList。线程不同步。因为底层结构的不同,所以LinkedList有自己的特有方法来增加效率。
Vector同ArrayList,底层都是数组结构,但是不同的是Vector是线程同步的,在一般情况下回大大降低效率。所以采用较少。但是Vector特有的取出方式枚举需要说一下。在IO流中的合并流SequenceInputStream中会用到。
Set接口
Set接口下的子类有HashSet和TreeSet。
HashSet的底层结构是哈希表(实际上是一个HashMap实例)。HashSet集合是通过元素中继承自Object超类的hashCode()方法和equal()方法来判断两个对象是否相同的。通过hashCode方法可以避免每次添加都需要equals的繁琐过程。所以我们在自己定义对象的时候,可以覆写对象继承自Object的这两个方法,使他们按照我们的意志来判断两个元素是否是同一元素。
TreeSet集合的底层是二叉树数据结构。他不仅不允许相同元素存在,更可以帮我们排序。我们将元素存入TreeSet集合之后他是按照自然顺序排序的。而我们要想让元素按照我们的意志进行排序,让元素实现Comparable接口,然后实现里面的CompareTo方法,返回0则代表元素相同,否则根据正数或者负数来判断排列顺序
如果一个类已经写好我们就尽量不要去改动它,这就用到了比较器。第二种方法是自定义一个比较器,该比较器实现Comparator,然后在比较器中覆写Compare方法,然后再创建TreeSet集合的时候将这个比较器作为参数传给TreeSet集合对象。
经过之间林靖在课程上的推荐,这边详细观察List系列接口
ArrayList
ArrayList是List接口的可变数组的实现。实现了所有可选列表操作,并允许包括 null 在内的所有元素。除了实现 List 接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。
每个ArrayList实例都有一个容量,该容量是指用来存储列表元素的数组的大小。它总是至少等于列表的大小。随着向ArrayList中不断添加元素,其容量也自动增长。自动增长会带来数据向新数组的重新拷贝,因此,如果可预知数据量的多少,可在构造ArrayList时指定其容量。在添加大量元素前,应用程序也可以使用ensureCapacity操作来增加ArrayList实例的容量,这可以减少递增式再分配的数量。
注意,此实现不是同步的。如果多个线程同时访问一个ArrayList实例,而其中至少一个线程从结构上修改了列表,那么它必须保持外部同步。那么我的理解ArrayList不是线程安全的。
1) 底层使用数组实现:
private transient Object[] elementData; 2) 构造方法:
ArrayList提供了三种方式的构造器,可以构造一个默认初始容量为10的空列表、构造一个指定初始容量的空列表以及构造一个包含指定collection的元素的列表,这些元素按照该collection的迭代器返回它们的顺序排列的。
public ArrayList() {
this(10);
}
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
this.elementData = new Object[initialCapacity];
}
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} 3) 存储:
ArrayList提供了set(int index, E element)、add(E e)、add(int index, E element)、addAll(Collection<? extends E> c)、addAll(int index, Collection<? extends E> c)这些添加元素的方法。
// 用指定的元素替代此列表中指定位置上的元素,并返回以前位于该位置上的元素。
public E set(int index, E element) {
RangeCheck(index);
E oldValue = (E) elementData[index];
elementData[index] = element;
return oldValue;
}
// 将指定的元素添加到此列表的尾部。
public boolean add(E e) {
ensureCapacity(size + 1);
elementData[size++] = e;
return true;
} 4) 读取:
// 返回此列表中指定位置上的元素。
public E get(int index) {
RangeCheck(index);
return (E) elementData[index];
} 5) 删除:
ArrayList提供了根据下标或者指定对象两种方式的删除功能。
// 移除此列表中指定位置上的元素。
public E remove(int index) {
RangeCheck(index);
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}
// 移除此列表中首次出现的指定元素(如果存在)。这是应为ArrayList中允许存放重复的元素。
public boolean remove(Object o) {
// 由于ArrayList中允许存放null,因此下面通过两种情况来分别处理。
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
// 类似remove(int index),移除列表中指定位置上的元素。
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
} 注意:从数组中移除元素的操作,也会导致被移除的元素以后的所有元素的向左移动一个位置。
6)Fail-Fast机制:
ArrayList也采用了快速失败的机制,通过记录modCount参数来实现。在面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险。
总结:
关于ArrayList的源码,给出几点比较重要的总结:
1、注意其三个不同的构造方法。无参构造方法构造的ArrayList的容量默认为10,带有Collection参数的构造方法,将Collection转化为数组赋给ArrayList的实现数组elementData。
2、注意扩充容量的方法ensureCapacity。ArrayList在每次增加元素(可能是1个,也可能是一组)时,都要调用该方法来确保足够的容量。当容量不足以容纳当前的元素个数时,就设置新的容量为旧的容量的1.5倍加1,如果设置后的新容量还不够,则直接新容量设置为传入的参数(也就是所需的容量),而后用Arrays.copyof()方法将元素拷贝到新的数组(详见下面的第3点)。从中可以看出,当容量不够时,每次增加元素,都要将原来的元素拷贝到一个新的数组中,非常之耗时,也因此建议在事先能确定元素数量的情况下,才使用ArrayList,否则建议使用LinkedList。
3、ArrayList的实现中大量地调用了Arrays.copyof()和System.arraycopy()方法。我们有必要对这两个方法的实现做下深入的了解。
首先来看Arrays.copyof()方法。它有很多个重载的方法,但实现思路都是一样的,我们来看泛型版本的源码:
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}很明显调用了另一个copyof方法,该方法有三个参数,最后一个参数指明要转换的数据的类型,其源码如下:
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
} 这里可以很明显地看出,该方法实际上是在其内部又创建了一个长度为newlength的数组,调用System.arraycopy()方法,将原来数组中的元素复制到了新的数组中。
下面来看System.arraycopy()方法。该方法被标记了native,调用了系统的C/C++代码,在JDK中是看不到的,但在openJDK中可以看到其源码。该函数实际上最终调用了C语言的memmove()函数,因此它可以保证同一个数组内元素的正确复制和移动,比一般的复制方法的实现效率要高很多,很适合用来批量处理数组。Java强烈推荐在复制大量数组元素时用该方法,以取得更高的效率。
4、ArrayList基于数组实现,可以通过下标索引直接查找到指定位置的元素,因此查找效率高,但每次插入或删除元素,就要大量地移动元素,插入删除元素的效率低。
5、在查找给定元素索引值等的方法中,源码都将该元素的值分为null和不为null两种情况处理,ArrayList中允许元素为null。















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









