






缓存设计实践
裸缓存资源的方式暴露出来一些问题:
- 缓存资源变更复杂度高
节点变更、扩缩容需要业务方变更配置重新上线,而且资源变更过程中业务方密切关注缓存的服务状况。
- 高可用策略无法复用
- 运维复杂度高
缺少简单友好的统一运维管理平台负责缓存资源的申请、分配、部署、变更、回收等操作。运维操作没有实现全界面化,且自动化程度不高。
- 缺少SLA指标保证
缓存资源异常导致业务出现问题时,缺少业务缓存SLA指标的监控及处理,更多的是依赖用户投诉后执行后续的运维处理,整个过程周期耗时较长,对业务影响较大
于是就出现了缓存中间件CacheService架构,这个架构同时存在着许多坑,既然前人踩过的坑,我们就整理出来,引以为鉴。
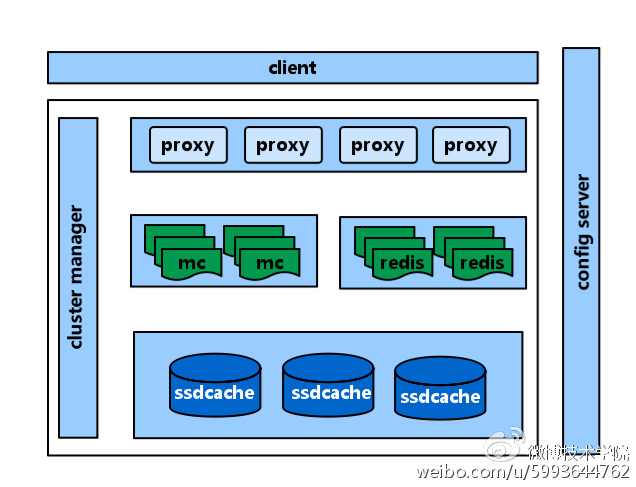
- 缓存Fail-Fast (快速失败)
当缓存层某个节点出现故障时,会导致请求持续穿透到存储层,使请求响应时间长(需要等到读写故障缓存节点超时),并且存储层负载居高不下。这就需要在使用缓存时考虑快速失败机制。快速失败指的是:当出现故障节点时,标识故障节点为不可用节点(策略举例:连续N次请求都出现超时,标识M时间段内为不可用),读写不可用节点快速返回。通过快速失败策略,解决请求响应时间长问题,保证SLA。
缓存无过期(Cache is Storage)
缓存无过期是指缓存中存储全量数据,不存在数据穿透的情况。 相比于缓存+DB的访问模型,使用内存存储简单可靠,但相应的内存成本也较高。选择内存缓存还是内存存储,需要结合具体的业务场景做权衡,比如单纯为解决Dog-Pile Effect而采用内存存储的话,内存成本可能就无法接受。通常情况下,内存存储模式,适合总体数据量很小,但是访问量巨大的业务场景,比如微博应用(来自weibo.com,weico等)列表。
dog-pile effect (狗桩效应)
狗桩效应是由于极热访问的缓存数据失效,大量请求发现没有缓存,进而穿透至DB,导致数据库load瞬间飙高甚至宕机。这是一个典型的并发访问穿透问题,理想情况下缓存失效对数据库应该只有一次穿透。要解决这个问题,首先从代码层面就要考虑到并发穿透的情况,保证一个进程只有一次穿透;同时,可以考虑使用基于mc的分布式锁来控制。不过使用分布式锁来实现会较为繁琐,通常在代码层面进行控制,就可以得到很好的效果。
极热点数据场景
微博在遇到一些突发事件时(如文章事件),流量会出现爆发式的增长,大量的热点数集中访问,导致某个缓存资源遇到性能瓶颈(比如明星的数据所在的端口),最终接口响应变慢影响正常的服务。为了应对这个问题我们在前端使用local cache, 以缓解后端缓存的压力。但是有些业务场景下,由于各种海量业务数据的冲刷,前端使用 local cache,命中率可能不高,性能提升也不明显,这种业务场景下可以考虑引入L1结构,通过部署多组小容量的L1缓存来应对突然的访问量增长。
避免雪崩
雪崩效应是由于缓存服务器宕机等原因导致命中率降低,大量的请求穿透到数据库,导致数据库被冲垮,业务系统出现故障,服务很难再短时间内回复。避免雪崩主要从以下几方面考虑:
- 缓存高可用
避免单点故障,保证缓存高命中率
- 降级和流控
故障期间通过降级非核心功能来保证核心功能可用性
故障期间通过拒掉部分请求保证有部分请求还能正常响应
- 清楚后端资源容量
更好的预知风险点,提前做好准备
即使出现问题,也便于更好的流控(具体应该放量多少)
数据一致性
我们知道,在CAP理论下,只能取其二,而无法保证全部。在分布式缓存中,通常要保证可用性(A)和可扩展性(P),并折中采用数据最终一致性,最终一致性包括:
- Master与副本一致性
- Cache与Storage一致性
- 业务各维度缓存数据一致性
缓存容量规划
进行缓存容量规划时,主要从以下几个方面进行考虑:
- 请求量
- 命中率:预热,防止雪崩
- 网络带宽:网卡、交换机
- 存储容量:预估存储大小,过期策略、剔除率
- 连接数
Memached Multiget-Hole(multigut黑洞)
在Memcached采用数据分片方式部署的情况下,对于multiget命令来说,部署部署更多的节点,并不能提升multiget的承载量,甚至出现节点数越多,multiget的效率反而会降低,这就是multiget黑洞。这是由于执行multiget命令时,会对每一个节点进行访问,通常SLA取决于最慢最坏的节点,而且节点数增多,出问题的概率也增大,客户端处理的压力也会增大。通常在数据分片时,我们推荐4~8个节点左右。解决multiget黑洞有两种方式可供参考:
- 使用多副本的方式扩容,增加multiget的承载量
- 通过业务层面来控制,multiget的keys尽可能放在同一个节点上,但具体实施时较难操作,可行性不是很高。
反向Cache
反向Cache就是将一个不存在的key放在缓存中,也就是在缓存中存一个空值。在某些场景下,比如微博维度的计数场景,若采用cache+DB的存储方式,由于大多数的微博并不存在转发、评论计数,这种场景下,就会出现由于大量访问不存在计数的mid,导致DB压力居高不下的情况。通过在cache中存一个null值,可减少对DB的穿透。当然这也存在潜在的风险或问题:
- 如果每次都是不同的mid,缓存效果可能不明显
- 需要更多的缓存容量
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









