






MySQL DB支持的主从复制
复制解决的问题
(1) 数据分布 (Data distribution )
(2) 负载平衡(load balancing)
(3) 备份(Backups)
(4) 高可用性和容错行 High availability and failover
复制如何工作
整体上来说,复制有3个步骤:
(1) master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2) slave将master的binary log events拷贝到它的中继日志(relay log);
(3) slave重做中继日志中的事件,将改变反映它自己的数据。
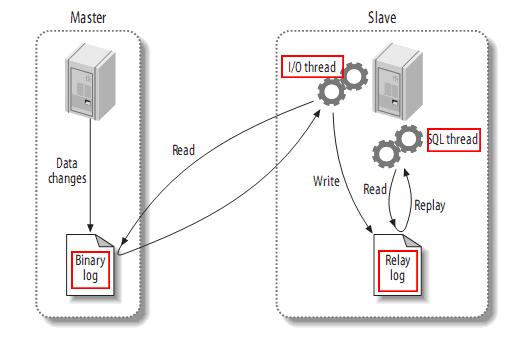
发送复制事件到其它slave
当设置log_slave_updates时,你可以让slave扮演其它slave的master。此时,slave把SQL线程执行的事件写进行自己的二进制日志(binary log),然后,它的slave可以获取这些事件并执行它。如下:
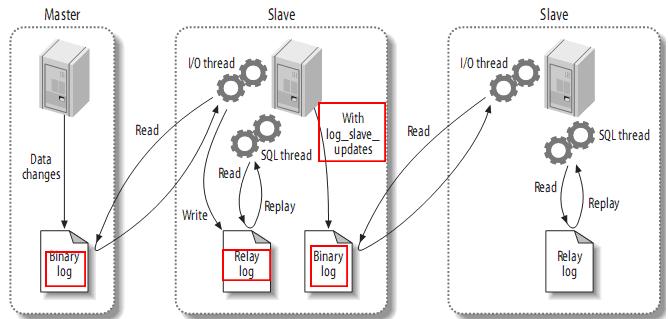
复制过滤
在master上过滤二进制日志中的事件;在slave上过滤中继日志中的事件。如下:
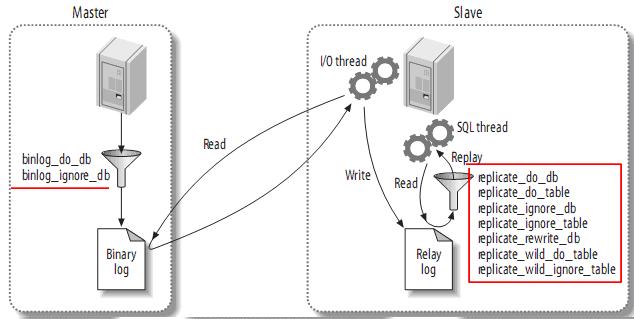
复制的常用拓扑结构
复制的体系结构有以下一些基本原则:
(1) 每个slave只能有一个master;
(2) 每个slave只能有一个唯一的服务器ID;
(3) 每个master可以有很多slave;
(4) 如果你设置log_slave_updates,slave可以是其它slave的master,从而扩散master的更新。
带从服务器的Master-Master结构(Master-Master with Slaves)
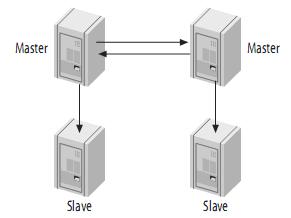
这种DualMaster与级联复制结合的架构,最大的好处就是既可以避免主Master的写入操作不会受到Slave集群的复制所带来的影响,同时主Master需要切换的时候也基本上不会出现重搭Replication的情况。但是,这个架构也有一个弊端,那就是备用的Master有可能成为瓶颈,因为如果后面的Slave集群比较大的话,备用Master可能会因为过多的SlaveIO线程请求而成为瓶颈。
该备用Master不提供任何的读服务的时候,瓶颈出现的可能性并不是特别高,如果出现瓶颈,也可以在备用Master后面再次进行级联复制,架设多层Slave集群。当然,级联复制的级别越多,Slave集群可能出现的数据延时也会更为明显,所以考虑使用多层级联复制之前,也需要评估数据延时对应用系统的影响。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









