






本文提要
最近写的几篇文章都是关于数据层优化方面的,这几天也在想还有哪些地方可以优化改进,结合日志和项目代码发现,关于数据层的优化,还是有几个方面可以继续修改的,代码方面,整合了druid数据源也开启了sql监控等,修改和规范了变量的命名方式,建表时的命名方式也做了修改,不过做的这些还不够,优化这件事真是一个长期和自觉的过程,mapper文件中的sql语句,依然不是十分的符合规范,有继续优化的必要,数据库中表的结构也需要继续优化。
前一篇文章主要讲了慢sql的整理,以及explain关键字在优化查询语句中的作用,也对sql做了一点小改动,但是修改的力度不是特别大,这一篇会稍微补充一下前一篇中关于索引的知识点,以及使用索引对查询语句进行优化。本文依然是代码优化和sql优化,主要还是讲一下索引及案例,前一篇文章较为简略,为了弥补这个懒惰造成的结果,这篇文章就详细一些。
表结构优化
建表语句规范,对原来的表结构重新做了一下修改,主要有:
- 字段非空修改
- 添加字段注释
- 添加索引(下面一个段落细讲)
这里只贴出部分修改后的代码,其余的自行通过github更新:
CREATE TABLE `ssm_article` (
`id` int(4) NOT NULL AUTO_INCREMENT COMMENT '主键',
`article_title` varchar(100) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '文章标题',
`article_create_date` varchar(50) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '创建时间',
`article_content` text COLLATE utf8_bin NOT NULL COMMENT '文章内容',
`is_top` int(4) NOT NULL DEFAULT '0' COMMENT '是否置顶,1为置顶,默认为0',
`add_name` varchar(50) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '添加人',
PRIMARY KEY (`id`)
) ENGINE=innodb DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
NOT NULL:防止索引失效,对表中一个列添加了索引的话,如果有记录为NULL,则查询时不会使用该索引。
表注释:同代码注释一样,可以帮助开发人员快速理解的建表的含义,但是同项目中的代码又不一样,没有注释,代码看久了总会理解其中的逻辑和功能,但是表字段,如果不懂就真的只能靠猜了。添加表注释就是为了大家都能理解字段的意思及建表意图,不要太相信自己的记忆力,它是比不了白纸黑字的,时间久了总会淡忘一些,如果连自己都忘了真的是搞笑了,因此注释的添加也是极其必要的,有些标示类型字段也是需要详细解释的,不同的值分别代表什么意思,如果不在注释中约定好,只靠口头来传达是很容易出现差错的,注释就是为了减少沟通成本,也减少理解出错的几率,从而提升工作效率。
查询语句优化
mapper文件中sql语句规范,修改select *语句,这里只贴出部分修改后的代码,其余的自行通过github更新:
<select id="findArticles" parameterType="Map" resultMap="ArticleResult">
select id,article_title,article_create_date,article_content,add_name from ssm_article
<where>
<if test="articleTitle!=null and articleTitle!='' ">
and article_title like #{articleTitle}
</if>
</where>
<if test="start!=null and size!=null">
limit #{start},#{size}
</if>
</select> 关于mapper文件中的sql语句,主要是修改了select语句,原本的select语句都是用select * from TABLE实现的,这种方式有不少缺点而且不是一个优雅的写法,因此做了一下规范,改为如下格式:
select COL(需要的列名) from TABLE关于避免使用select *语句的个人想法:
- 执行SELECT * 语句时,SQL Server首先要查找出表中有哪些列,然后才能开始执行SELECT * 语句,这在某些情况会产生性能问题。
- SELECT * 语句取出表中的所有字段,所有数据都会返回到结果集中。
- SELECT * 中返回的字段中有可能存在一个功能中不需要的字段。
- 使用SELECT * 语句可能会影响到索引的使用,不利于查询的性能优化。
针对这四点分别讲一下个人理解:
- 第一条,对于性能的影响可能不会太大,几毫秒或者几微妙的事情,似乎不是那么严重,而且SQL Server也有对应的缓存策略,不会每次都去查表中有哪些列。但是,我们现在是在做优化工作,既然做就要尽量做到最好,有优化的地方还是要去尝试一下,提升0.01秒也是提升,不要因为量小而忽略它。
- 第二条,所有的字段都返回,结果集的数据量也会相应的增大,对应的,也就会增加数据传输的时间,即使mysql服务和客户端是在同一台机器上,二者间通信时使用的协议还是tcp,通信也是需要额外的时间,因此,还是取所需内容为好。
- **第三条,举个例子,表中有16个字段,我们要实现一个功能,但是这个方法中需要其中6个字段就可以了,那么剩下的10个字段就是没用的了,如果用select *返回结果,一个sql返回列可能就要多创建10个String对象到jvm中,10000个呢?再多呢?这是浪费。而且,如果返回的列中有大字段,例如很长的varchar,blob,text,占用空间也更大,更浪费。**
- 第四条,举个例子,对于ssm_user表,创建了user_name和role_name的联合索引,对于以下两条sql语句:
select role_name from ssm_user where user_name='admin'和select * from ssm_user where user_name='admin',前者要比后者的速度快,因为表中存在user_name和role_name的联合索引,因此role_name可以在索引树上直接拿到,不再需要读取表中的这条记录,在下面会给出具体代码。
其实我也没想到一个select *会写这么多知识点。
既然优化select * from TABLE有那么多好处,那么是不是select count(*) from TABLE也要优化呢?OK,我们接着来分析,select count(*) from TABLE在不同情况下,性能表现的不同:
- innodb引擎:
select count(*)与select count(COL)的效率没有太大差距,都会扫描全表或者where条件语句后的结果,累加可能得到的结果不同。 - myisam引擎且没有where子句:可以直接得出myisam会记录总行数,很快。
- myisam有where子句:与innodb引擎相同。
注:
count(col) 是表示结果集中有多少个column字段不为空的记录。
count(*) 是表示整个结果集有多少条记录。
因此,通过上面的分析发现,select count(*)语句的性能提升,首先是引擎的选择(这个不重要,目前选择的是innodb引擎),重点是在where条件语句的优化,也就是索引的优化。
索引和优化案例
前面两个段落中基本都提到了一个知识点--索引,在sql语句优化中,合理和正确的索引真的是一个利器。
优化的意义:我们在前一篇讲到了慢sql给项目带来的危害,这里再补充一下,首先我们大多数用到的都是innodb引擎来建表,这个引擎已经做了挺大的优化,支持行级锁和表锁,并且默认锁为行级锁,对表锁做了一定的优化,因此对于行级锁的优化来说,就是尽量减少sql语句执行而带来的行级锁,尽量使得处于锁状态中的记录数减少。如果一条sql锁住过多的记录,那么对于其他sql语句的执行就是一个阻碍,需要等到锁释放并且竞争到锁才能正常的执行,因此我们优化慢sql不仅仅是提升执行速度和执行时间,同时也是优化查询过程,优化mysql的资源使用,减少锁资源的开销以及系统开销,同时,合理的查询语句也能降低各种错误的产生,比如事务死锁的产生。
从以上分析中我们可以得出一个结论,尽量使得sql语句执行时innodb使用行级锁而不是表锁,innodb行锁是通过给索引上的索引项加锁来实现的,innodb这种行锁实现特点意味着:只有通过索引条件检索数据,innodb才使用行级锁,否则,innodb将使用表锁!
索引的类型:
- 普通索引:这是最基本的索引类型,没唯一性之类的限制。
- 唯一性索引:和普通索引基本相同,但所有的索引列值保持唯一性。
- 主键索引:主键是一种唯一索引,但必须指定为”PRIMARY KEY”。
- 全文索引:不讲这个,想了解的自己去看一下
结合前文提到的ssm_user表来讲一个小例子:

从结果来看,依然是全表扫描。
对user_name,role_name字段添加索引:
alter table ssm_user add index idx_un_rn(user_name,role_name);
再次执行上面的分析语句:
explain select role_name from ssm_user where user_name='admin';
通过结果来看,添加了索引之后,type已由原来的全表扫描ALL变成了ref级别,也如前文所说,role_name直接通过索引树返回,extra中的using index参数表示直接访问索引就足够获取到所需要的数据,不需要通过索引回表。
这个例子是对上一段落select *和select COL间性能比较的补充,下面再讲解一个ssm_picture表的例子,对前一篇文章《Spring+SpringMVC+MyBatis+easyUI整合优化篇(十二)数据层优化-explain关键字及慢sql优化》做一个补充。
首先在数据库中插入20000条数据: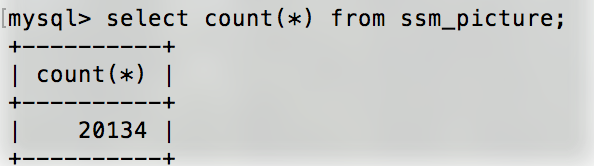
分析查询语句explain select id,path,type,time,url,grade from ssm_picture where type=1 and grade=1 limit 0,10;:
多次执行,时间基本都是0.02s:

在没有添加索引前,依然是全表扫描,记录总数为20134,前文做的一个小改动:

是通过order by id使得查询语句使用主键索引,type由ALL变为index,但是依然为全表扫描。因为where条件中是通过type和grade对结果集进行过滤,因此添加一个type字段和grade字段组成的多列索引。
在ssm_picture表中添加一个名称为idx_type_grade的索引:
alter table ssm_picture add index idx_type_grade (type,grade);此时再次分析查询语句得到结果如下:

多次执行后的执行时间如下:
比原来应该是有一些提升的,不仅仅是时间上的提升,关键是结构上的整理,不仅优化了查询过程和结果,也避免全表扫描节省了mysql的开销,降低可预见的错误发生几率。
最左前缀原则:
多列索引有一个特点,即最左前缀(Leftmost Prefixing)。假如有一个多列索引为key(firstname lastname age),当搜索条件是以下各种列的组合和顺序时,MySQL将使用该多列索引:
firstname,lastname,age
firstname,lastname
firstname
也就是说,相当于还建立了key(firstname lastname)和key(firstname)。
按照最左前缀原则,本例中的idx_type_grade(type,grade)即创建了两个索引:
type,grade
typeshow index from ssm_picture查看表的索引信息:

图中Key_name 为索引的名称,Seq_in_index为索引中的列序列号(从1开始),因此结果集表示的是,有一个索引名为idx_type_grade,第一列为type,第二列是grade,而不是像id主键索引表示单独的两个索引。分别以type和grade为where语句中的条件来执行sql验证一下:


type用到了索引,而grade依然是全表扫描,即无grade索引,也符合最左前缀原则的分析。
总结
使用索引的优点:
- 可以通过建立唯一索引或者主键索引,保证数据库表中每一行数据的唯一性
- 建立索引可以大大提高检索的数据,以及减少表的检索行数
- 在表连接的连接条件可以加速表与表直接的相连
- 在分组和排序字句进行数据检索,可以减少查询时间中分组和排序时所消耗的时间(数据库的记录会重新排序)
- 建立索引,在查询中使用索引可以提高性能
使用索引的缺点:
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要更新数据,还要更新一下索引文件,创建索引和维护索引 会耗费时间,随着数据量的增加而增加
- 建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
- 索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句
使用索引需要注意的地方:
- 在经常需要搜索的列上,可以加快索引的速度
- 在表与表的而连接条件上加上索引,可以加快连接查询的速度
- 在一些where 之后的 < <= > >= BETWEEN IN 以及某个情况下的like 建立字段的索引(B-TREE)
- 如果你对nickname字段建立了一个索引,当查询的时候的语句是 nickname lick '%ABC%'那么这个索引讲不会起到作用,而nickname lick 'ABC%'那么将可以用到索引
- 索引不会包含NULL列,如果列中包含NULL值都将不会被包含在索引中,复合索引中如果有一列含有NULL值那么这个组合索引都将失效,一般需要给默认值0或者' '字符串
- 使用短索引,如果你的一个字段是Char(32)或者int(32),在创建索引的时候指定前缀长度 比如前10个字符 (前提是多数值是唯一的..)那么短索引可以提高查询速度,并且可以减少磁盘的空间,也可以减少I/0操作.
- 不要在列上进行运算,这样会使得mysql索引失效,也会进行全表扫描
- 选择越小的数据类型越好,因为通常越小的数据类型通常在磁盘,内存,cpu,缓存中 占用的空间很少,处理起来更快
什么情况下不创建索引:
- 查询中很少使用到的列 不应该创建索引,如果建立了索引然而还会降低mysql的性能和增大了空间需求.
- 很少数据的列也不应该建立索引,比如一个性别字段0或者1,在查询中,结果集的数据占了表中数据行的比例比较大,mysql需要扫描的行数很多,增加索引,并不能提高效率
- 定义为text和image和bit数据类型的列不应该增加索引
- 当表的修改(UPDATE,INSERT,DELETE)操作远远大于检索(SELECT)操作时不应该创建索引,这两个操作是互斥的关系
索引不是越多越好,也不是所有的表都要创建索引,根据需求和实际运行的sql语句进行合理的索引创建。本文中的案例都是围绕ssm-demo这个项目来进行的,都是单表的简单查询sql语句,并没有复杂的连接查询或者复杂的where语句,join查询等复杂查询,以后有时间专门写几篇文章来详细讲解一下,本项目实在没有太好的切入点,只能重新建表来单独讲解,OK,本文结束。
这周并没有更新博客,是因为完成这两篇博客花费了不少的时间,从构思到整理资料和理出文章结构再到完成,前前后后大概有6个晚上,白天要上班或者有其他事情,基本都是抽出晚上的一段时间来写,也慢慢感觉随着项目的修改以及知识点的深入,后面会越来越难吧,也不知道自己坚不坚持得下来,加油啦。

















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









