






写在前面
flume 版本:1.6.0 , kafka 版本:0.9.0, storm 版本:1.0.2, hbase 版本:1.2.0
处理流程:整个流程为flume监听一个端口号随机发送字符串,经过kafka发送给storm,storm进行切割句子为单词并且统计单词个数,并且实时存入hbase.
具体的流程:flume sources.type采用avro模式监听端口44444,sink发送数据给kafka,kafka创建topic-->fkshTopic,storm使用自带的kafkaSpout消费消息,切割字符串,统计单词个数,存入hbase.
配置flume-ng
配置在flume-ng/conf 下新建配置文件 flume-conf-kafka.properties 内容如下
#单节点Flume配置 flume + kafka
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
#描述Sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = fkshTopic
a1.sinks.k1.brokerList = 172.17.201.142:6667,172.17.201.70:6667
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel = c1
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 10000
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
解释:
sources type类型为:avro
bind:本机
port:监听的端口号
sinks type: kafkaSink
topic: fkshTopic ---> 消息队列的topic的名字
brokerlist:kafka集群的broker 的主机和端口号
启动flume-ng
cd /flume-ng/bin
执行
./flume-ng agent --conf ../conf --conf-file ../conf/flume-conf-kafka.properties --name a1 -Dflume.root.logger=INFO,console
编写 flume 模拟数据程序
package leap.flume;
import org.apache.flume.api.RpcClient;
import java.util.Random;
/**
* Created by FromX on 2017/3/15.
*/
public class FlumeRpcApp {
public static void main(String[] args) {
RpcClient client = FlumeRPCClient.createClient("172.17.201.142", 44444);
Random _rand = new Random();
//随机发送句子
String[] sentences = new String[]{ "the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature"
,"难道 没有 中文 吗"};
for (int i=0;i<100;i++){
String data =sentences[_rand.nextInt(sentences.length)];
FlumeRPCClient.sendData(client,data);
System.out.println("sendData--------->"+data);
}
client.close();
}
}
package leap.flume;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
import java.nio.charset.Charset;
/**
* Created by FromX on 2017/3/15.
* Flume RPC 远程调用 客户端
*/
public class FlumeRPCClient {
/**
* 创建一个默认的flume rpc client
* @param hostname
* @param port
* @return
*/
public static RpcClient createClient(String hostname, Integer port) {
// Use the following method to create a thrift client (instead of the above line):
// return RpcClientFactory.getThriftInstance(hostname, port);
return RpcClientFactory.getDefaultInstance(hostname, port);
}
/**
* 关闭客户端
* @param client
*/
public static void closeClient(RpcClient client) {
client.close();
}
/**
* 发送 数据到flume 如果发生异常 关闭客户端
* @param client
* @param data
*/
public static void sendData(RpcClient client,String data) {
// Create a Flume Event object that encapsulates the sample data
Event event = EventBuilder.withBody(data, Charset.forName("UTF-8"));
// Send the event
try {
client.append(event);
} catch (EventDeliveryException e) {
}
}
}
运行效果:
解释:向 flume-ng agent 所在的主机的44444端口随机发送字符串
启动一个kafka consumer
这是一个可以选操作,目的是为了测试 flume-ng+kafka 是否成功,
./kafka-console-consumer.sh --zookeeper 172.17.201.142:2181,172.17.200.158:2181,172.17.201.15:2181 --from-beginning --topic flumeTopic
运行效果:
Storm程序进行 wordcount
如果对storm编程的基本概念不了解,
请参考:https://my.oschina.net/u/2969788/blog/859910
TopologyFksh
package leap.storm.fksh;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.kafka.KafkaSpout;
import org.apache.storm.kafka.SpoutConfig;
import org.apache.storm.kafka.StringScheme;
import org.apache.storm.kafka.ZkHosts;
import org.apache.storm.spout.SchemeAsMultiScheme;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
/**
* Created by FromX on 2017/3/15.
* 处理流程: flume--> kafka --> storm--> hbase
*/
public class TopologyFksh {
public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException, InterruptedException {
TopologyBuilder builder = new TopologyBuilder();
// config kafka spout kafkaspout topic 的名称 这个topic名称可以在 flume的配置文件中
String topic = "fkshTopic";
ZkHosts zkHosts = new ZkHosts("c1.wb3.com:2181,c2.wb4.com:2181,m1.wb1.com:2181");
//设置偏移量 每次不会从头开始读取 消息队列 而会从 上次读取的结尾读取 /fkshtest 目录用来存储偏移量 fkshApp 对应一个应用
SpoutConfig spoutConfig = new SpoutConfig(zkHosts, topic, "/fkshtest", "fkshApp");
List<String> zkServers = new ArrayList<String>();
for (String host : zkHosts.brokerZkStr.split(",")) {
zkServers.add(host.split(":")[0]);
}
spoutConfig.zkServers = zkServers;
spoutConfig.zkPort = 2181;
//超时时间 100分钟
spoutConfig.socketTimeoutMs = 60 * 1000 * 100;
// 定义输出格式为String
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
//创建 storm自带的kafkaspout
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
// set kafka spout 启用2个线程
builder.setSpout("kafka-spout", kafkaSpout, 2);
// set bolt 启动3个线程 随机分发
builder.setBolt("line-spilt", new BoltSpilt(), 3).shuffleGrouping("kafka-spout");
// 统计单词 fieldsGrouping 2线程 word 分组 分发
builder.setBolt("word-counter", new BoltWordCount(), 2)
.fieldsGrouping("line-spilt", new Fields("word"));
/**
* 提交任务配置
*/
Config conf = new Config();
conf.setDebug(false);
// set producer properties.
Properties props = new Properties();
props.put("metadata.broker.list", "172.17.201.142:6667,172.17.201.70:6667");
//ack机智 配置
props.put("request.required.acks", "1"); // 0 1 -1
props.put("serializer.class", "kafka.serializer.StringEnscoder");
conf.put("kafka.broker.properties", props);
//如果有任务id参数 则进行集群提交
if (args != null && args.length > 0) {
conf.setNumWorkers(5);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
}
//如果没有参数 默认本地提交任务
else {
//设置任务最大进程数
conf.setMaxTaskParallelism(3);
//创建本地集群
LocalCluster cluster = new LocalCluster();
//提交任务 任务id word-count
cluster.submitTopology("word-count", conf, builder.createTopology());
// 睡眠 10000*6毫秒后手动结停止本地集权
Thread.sleep(10000 * 6);
cluster.shutdown();
}
}
}
解释 :
kafkaspout: 使用storm提供的 kafkaspout来消费kafka消息,其中构造kafkaspout的参数为 zookeeper集群,端口号,偏移量,应用名称,应用名称随便起不重复就行,偏移量用来记录kafka消息队列的消费情况,不会每次都重新消费.
任务提交:任务提交的时候,需要特别注意在配置项, props里面需要制定 kafka的brokerlist
BoltSpilt:用来切割字符串为单词发送给下游
BoltWordCount:统计单词个数并且存入hbase
BoltSpilt
package leap.storm.fksh;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* Created by FromX on 2017/3/15.
* 切割 单句为 单词
*/
public class BoltSpilt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for (String word : words) {
word = word.trim();
if (!word.isEmpty()) {
word = word.toLowerCase();
// Emit the word
List a = new ArrayList();
a.add(input);
collector.emit(a, new Values(word));
}
}
//确认成功处理一个tuple
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
BoltWordCount
package leap.storm.fksh;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
/**
* Created by FromX on 2017/3/15.
* <p>
* 统计单词数 并且存入hbase
*/
public class BoltWordCount extends BaseRichBolt {
private OutputCollector collector;
//参数设置 hbase 连接参数
private static Configuration conf;
private static HTable table;
Map<String, Integer> counts = new HashMap<String, Integer>();
/**
* 初始化 collector 和hbase连接
* @param stormConf
* @param context
* @param collector
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.zookeeper.quorum", "172.17.201.142:2181,172.17.200.158:2181,172.17.201.15:2181");
conf.set("hbase.master", "172.17.201.142" + ":60000");
conf.set("zookeeper.znode.parent", "/hbase-unsecure");
// 表名
String tableName = "stormTable";
try {
table = new HTable(conf, tableName);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 统计并且存入hbase
*
* @param tuple
*/
@Override
public void execute(Tuple tuple) {
String word = tuple.getString(0);
Integer count = counts.get(word);
if (count == null)
count = 0;
count++;
counts.put(word, count);
//行key 随机生成一个
UUID uuid = UUID.randomUUID();
String rowKey = uuid.toString();
//列族
String columnFamily = "WCFy";
//标识符
String identifier = "WC";
Put p1 = new Put(Bytes.toBytes(rowKey));
p1.add(Bytes.toBytes(columnFamily), Bytes.toBytes(identifier), Bytes.toBytes(counts.toString()));
try {
table.put(p1);
} catch (IOException e) {
e.printStackTrace();
}
collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("resoult"));
}
}
解释:
初始化: prepare方法中初始化了 hbase的连接
注意: 务必预先 建好 hbase的表 建表语句 create "stormTable","WCFy"
提交storm任务
将TopologyFksh 达成jar 提交到storm集群即可
./storm jar poc.jar leap.storm.fksh.TopologyFksh fksh
关于如何打包参考:https://my.oschina.net/u/2969788/blog/859910
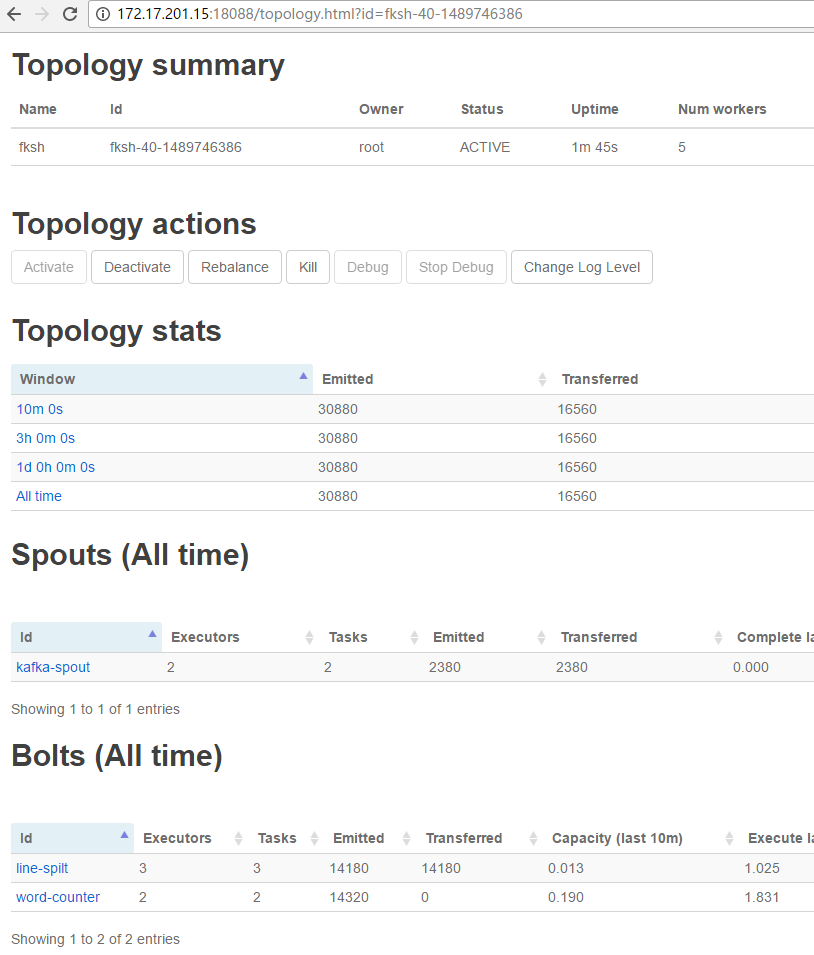
提交完任务之后 可以在 storm ui 中查看 任务
重新运行--FlumeRpcApp--main 产生随机字符串
在 storm ui中可以看到 tupl 元组的 emit情况
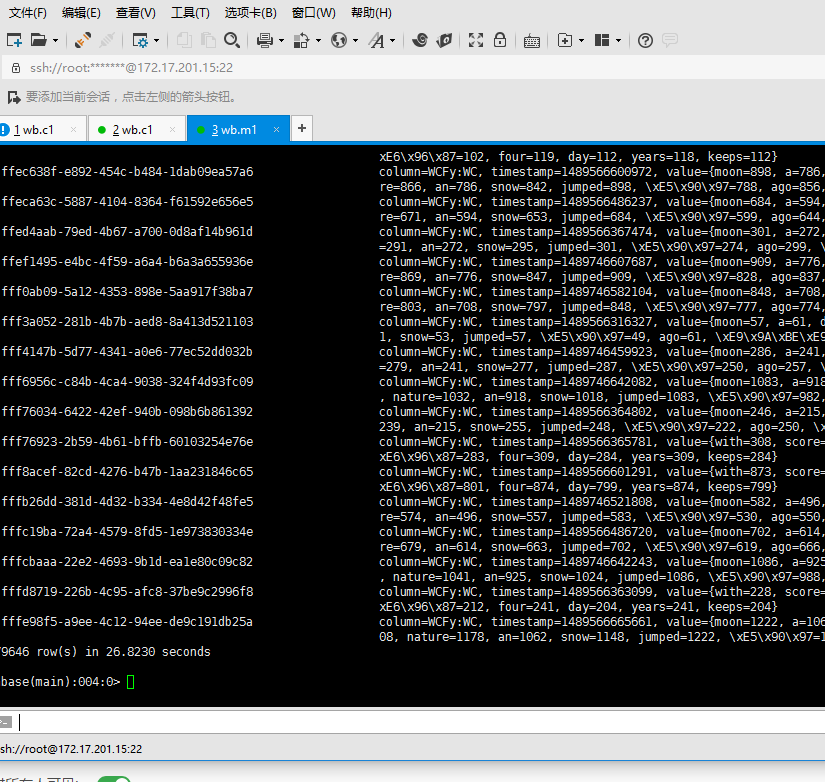
hbase中查看结果
scan "stormTable"
结果截图















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









