






前一段毕业选导师的时候发生了一些变故,导致学习AsterixDB的时间大大减少,甚至是搁置了一段时间.上周开始继续学习,阅读了几篇查询优化相关的Paper,老师也提出了几个思考的小问题,下面就是对这几个小问题的总结.
Q1: 对于一个Query Plan来说,Stage是根据什么划分的?

如图所示,一个过程是根据什么分为两个Stage的呢?
刚开始思考时我以为是根据所处理的数据对象所处的位置划分的,因为看到很多Stage的划分都是在Partition和Merge之间的,所以就想是不是数据在节点本地和节点之间进行shuffle之类的时候会进行Stage的切换呢?
之后在讨论的时候老师告诉我并不是这样的,Stage的划分依据是根据两个阶段之间的切换会不会"block"住,可以理解为数据依赖的关系.即如果后一阶段必须在前一阶段全部执行完成后才能开始执行,那么这两个阶段就分属两个不同的Stage.
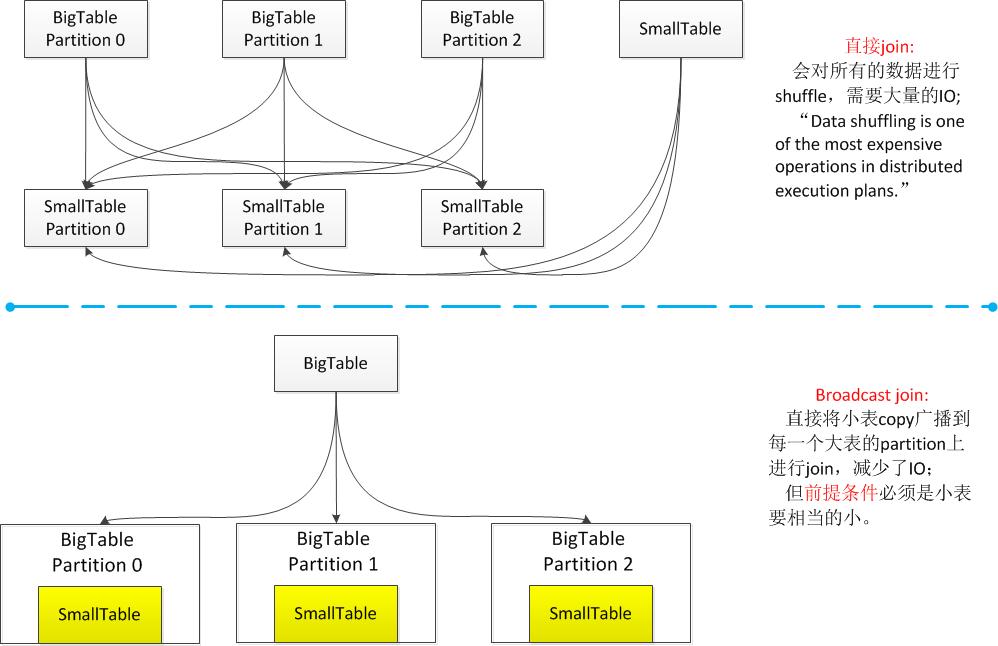
Q2: 关于Hash Partition和Broadcast Join的问题?

以这几组图为例,(b)中Hash Parition和Merge为什么必须以字段a作为对象,而(d)中可以以字段a和b共同作为处理对象?如果(b)中的a换为a和b会产生什么错误?为什么会产生错误?
初看这几幅图一直不理解上述的几个问题,觉得字段a和ab的区别就是解决数据skew的问题,后经过老师的一番解释才恍然大悟.
假设现在r.txt里有两条记录(1,1)和(2,1),对应字段(a,b),同样在s.txt里也有两条记录,现在有两个节点Node0和Node1,设定Hash函数规则为((sum(字段之和)) mod 2);
这样,
①如果左边HashPartition和Merge的对象为字段a,那么(1,1)分到Node1,(2,1)分到Node0;
(2,2)分到Node0,(1,2)分到Node1,最终同一节点内的记录根据字段a进行Hash Join,两个节点内都可以成功的Join;
②如果左边HashPartition和Merge的对象为字段a和b,那么(1,1)分到Node0,(2,1)分到Node1,最后跟右边的进行Hash Join,结果就是没有可以连接的字段,丢失了原本应该存在的信息!
问题来了,(d)的左边明明是根据a和b来Partition和Merge的啊!是不是有问题啊?!
非也非也,这时候Broadcast Join的作用就体现出来了,(d)中计划奏效的前提条件是s.txt经过用户自定义Filter过滤掉了大量的记录,相对于r.txt来说已经是一个非常小的表了,那么我们就可以直接将s.txt这整张表广播到r.txt的每个节点上去,进行本地Join,这样就大大节省了Shuffle所带来的大量IO,因为每个节点上都存有s.txt的所有记录,所以可以正常的Join,不会丢失记录,Broadcast Join的原理如下图所示:
Q3: 怎么看懂AsterixDB产生的Logical Plan和Hyracks Job?
Logical Plan: 自下向上看!大写Operator为Physical Operator,对应的上面的一条小写Operator是它的Logical Operator,将这些operator对应到你的每一条查询语句中去,找出其中每个$$参数所对应的你的查询所对应的字段,一层一层的向上看即可.

Hyracks Job: 自上向下看,分为很多个Connector,每个Connector Descriptor又包含两个Operator Descriptor,上一层的Out Operator是下一层Connector的In Operator,每个Operator又对应一个或多个实际的操作,层层向下慢慢看即可.需要注意,可以通过一个Connector的In和Out的编号来确定是否属于同一个Stage,如果In是'0'而Out是'1',那么这就是一个新Stage的切换位置!
















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









