







来自: http://my.oschina.net/XYleung/blog/99604
树状结构的数据保存在数据库中的常用方法有一下两种:
1、邻接表(adjacency list model)
2、预排序遍历树算法(modified preorder tree traversal algorithm)
用一下的例子讨论这两种方法的差异:
现有一棵树如下:
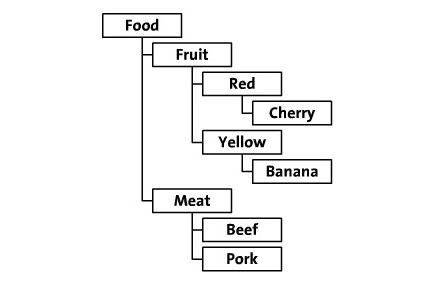
邻接表模式:
这种模式我们经常用到,很多的教程和书中也介绍过。我们通过给每个节点增加一个属性 parent 来表示这个节点的父节点从而将整个树状结构通过平面的表描述出来。根据这个原则,例子中的数据可以转化成如下的表:
我们看到 Pear 是Green的一个子节点,Green是Fruit的一个子节点。而根节点'Food'没有父节点。 为了简单地描述这个问题, 这个例子中只用了name来表示一个记录。 在实际的数据库中,你需要用数字的id来标示每个节点,数据库的表结构大概应该像这样:id, parent_id, name, description。
以下是代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
<?php
// $parent is the parent of the children we want to see
// $level is increased when we go deeper into the tree,
// used to display a nice indented tree
function
display_children(
$parent
,
$level
)
{
// 获得一个 父节点 $parent 的所有子节点
$result
= mysql_query(
'SELECT name FROM tree '
.
'WHERE parent="'
.
$parent
.
'";'
);
// 显示每个子节点
while
(
$row
= mysql_fetch_array(
$result
))
{
// 缩进显示节点名称
echo
str_repeat
(
' '
,
$level
).
$row
[
'name'
].
"n"
;
//再次调用这个函数显示子节点的子节点
display_children(
$row
[
'name'
],
$level
+1);
}
}
?>
|
Food
Fruit
Red
Cherry
Yellow
Banana
Meat
Beef
Pork
如果你只想显示整个结构中的一部分,比如说水果部分,就可以这样调用:display_children('Fruit',0);
几乎使用同样的方法我们可以知道从根节点到任意节点的路径。比如 Cherry 的路径是 "Food >; Fruit >; Red"。 为了得到这样的一个路径我们需要从最深的一级"Cherry"开始, 查询得到它的父节点"Red"把它添加到路径中, 然后我们再查询Red的父节点并把它也添加到路径中,以此类推直到最高层的"Food"
以下是代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
<?php
// $node 是那个最深的节点
function
get_path(
$node
)
{
// 查询这个节点的父节点
$result
= mysql_query(
'SELECT parent FROM tree '
.
'WHERE name="'
.
$node
.
'";'
);
$row
= mysql_fetch_array(
$result
);
// 用一个数组保存路径
$path
=
array
();
// 如果不是根节点则继续向上查询
// (根节点没有父节点)
if
(
$row
[
'parent'
]!=
''
)
{
// the last part of the path to $node, is the name
// of the parent of $node
$path
[] =
$row
[
'parent'
];
// we should add the path to the parent of this node
// to the path
$path
=
array_merge
(get_path(
$row
[
'parent'
]),
$path
);
}
// return the path
return
$path
;
}
?>
|
Array
(
[0] =>; Food
[1] =>; Fruit
[2] =>; Red
)
接下来如何把它打印成你希望的格式,就是你的事情了。
缺点:
这种方法很简单,容易理解,好上手。但是也有一些缺点。主要是因为运行速度很慢,由于得到每个节点都需要进行数据库查询,数据量大的时候要进行很多查询才能完成一个树。另外由于要进行递归运算,递归的每一级都需要占用一些内存所以在空间利用上效率也比较低。
预排序遍历树算法
现在让我们看一看另外一种不使用递归计算,更加快速的方法,这就是预排序遍历树算法(modified preorder tree traversal algorithm) 这种方法大家可能接触的比较少,初次使用也不像上面的方法容易理解,但是由于这种方法不使用递归查询算法,有更高的查询效率。
我们首先将多级数据按照下面的方式画在纸上,在根节点Food的左侧写上 1 然后沿着这个树继续向下 在 Fruit 的左侧写上 2 然后继续前进,沿着整个树的边缘给每一个节点都标上左侧和右侧的数字。最后一个数字是标在Food 右侧的 18。 在下面的这张图中你可以看到整个标好了数字的多级结构。(没有看懂?用你的手指指着数字从1数到18就明白怎么回事了。还不明白,再数一遍,注意移动你的手指)。
这些数字标明了各个节点之间的关系,"Red"的号是3和6,它是 "Food" 1-18 的子孙节点。 同样,我们可以看到 所有左值大于2和右值小于11的节点 都是"Fruit" 2-11 的子孙节点

这样整个树状结构可以通过左右值来存储到数据库中。继续之前,我们看一看下面整理过的数据表。

注意:由于"left"和"right"在 SQL中有特殊的意义,所以我们需要用"lft"和"rgt"来表示左右字段。 另外这种结构中不再需要"parent"字段来表示树状结构。也就是 说下面这样的表结构就足够了。
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11;

看到了吧,只要一个查询就可以得到所有这些节点。为了能够像上面的递归函数那样显示整个树状结构,我们还需要对这样的查询进行排序。用节点的左值进行排序:
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11 ORDER BY lft ASC;
那么某个节点到底有多少子孙节点呢?很简单,子孙总数=(右值-左值-1)/2
descendants = (right – left - 1) / 2 ,如果不是很清楚这个公式,那就去翻下书,我们在上数据结构写的很清楚!
添加同一层次的节点的方法如下:
|
1
2
3
4
5
6
7
8
9
10
|
LOCK
TABLE
nested_category WRITE;
SELECT
@myRight := rgt
FROM
nested_category
WHERE
name
=
'Cherry'
;
UPDATE
nested_category
SET
rgt = rgt + 2
WHERE
rgt > @myRight;
UPDATE
nested_category
SET
lft = lft + 2
WHERE
lft > @myRight;
INSERT
INTO
nested_category(
name
, lft, rgt)
VALUES
(
'Strawberry'
, @myRight + 1, @myRight + 2);
UNLOCK TABLES;
|
|
1
2
3
4
5
6
7
8
9
10
|
LOCK
TABLE
nested_category WRITE;
SELECT
@myLeft := lft
FROM
nested_category
WHERE
name
=
'Beef'
;
UPDATE
nested_category
SET
rgt = rgt + 2
WHERE
rgt > @myLeft;
UPDATE
nested_category
SET
lft = lft + 2
WHERE
lft > @myLeft;
INSERT
INTO
nested_category(
name
, lft, rgt)
VALUES
(
'charqui'
, @myLeft + 1, @myLeft + 2);
UNLOCK TABLES;
|
|
1
2
3
4
5
6
|
SELECT
CONCAT( REPEAT(
' '
, (
COUNT
(parent.
name
) - 1) ), node.
name
)
AS
name
FROM
nested_category
AS
node,
nested_category
AS
parent
WHERE
node.lft
BETWEEN
parent.lft
AND
parent.rgt
GROUP
BY
node.
name
ORDER
BY
node.lft;
|
|
1
2
3
4
5
6
7
8
9
10
11
|
LOCK
TABLE
nested_category WRITE;
SELECT
@myLeft := lft, @myRight := rgt, @myWidth := rgt - lft + 1
FROM
nested_category
WHERE
name
=
'Cherry'
;
DELETE
FROM
nested_category
WHERE
lft
BETWEEN
@myLeft
AND
@myRight;
UPDATE
nested_category
SET
rgt = rgt - @myWidth
WHERE
rgt > @myRight;
UPDATE
nested_category
SET
lft = lft - @myWidth
WHERE
lft > @myRight;
UNLOCK TABLES;
|















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









