







有时候修改环境变量的时候,不小心误删了一些环境变量,就会出现好多程序无法打开,显示操作系统找不到已输入的
环境选项。
例如这样:
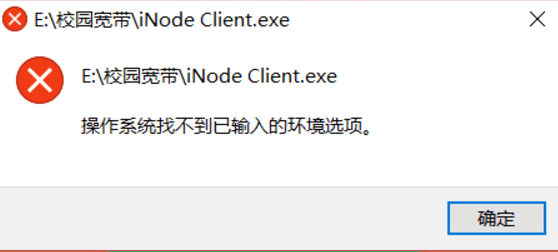
你会去设置环境变量那看看哪个不见了,把它加回来,结果又出现这样的情况:
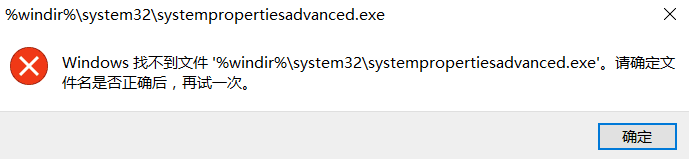
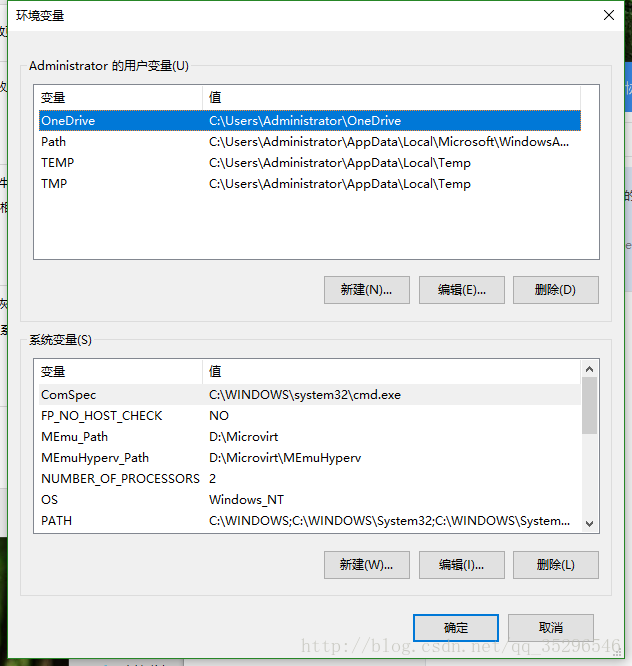
类似这种状况是误删了系统环境变量,系统环境变量中的两项可能有问题变量“windir”和“Path”,尤其可能已经误删除了或全部删除了。此时已经从资源管理器的“系统”打不开“高级系统设置”,需要从目录里打开,位于“C:\Windows\System32\SystemPropertiesAdvanced.exe”双击即可(直接在中运行就能找到了)。然后将下面的默认变量和值输进去就解决了:
用户变量
| 变量 | 值 |
|---|---|
| Path | %USERPROFILE%\AppData\Local\Microsoft\WindowsApps; |
| TEMP | %USERPROFILE%\AppData\Local\Temp |
| TMP | %USERPROFILE%\AppData\Local\Temp |
系统变量
| 变量 | 值 |
|---|---|
| ComSpec | %SystemRoot%\system32\cmd.exe |
| NUMBER_OF_PROCESSORS | 2 |
| OS | Windows_NT |
| PATH | %SystemRoot%;%SystemRoot%\system32;%SystemRoot%\System32\wbem;%SYSTEMROOT%\System32\WindowsPowerShell\v1.0\ |
| PATHEXT | .COM;.EXE;.BAT;.CMD;.VBS;.VBE;.JS;.JSE;.WSF;.WSH;.MSC |
| PROCESSOR_ARCHITECTURE | AMD64 |
| PROCESSOR_IDENTIFIER | Intel64 Family 6 Model 58 Stepping 9, GenuineIntel |
| PROCESSOR_LEVEL | 6 |
| PROCESSOR_REVISION | 3a09 |
| PSModulePath | %ProgramFiles%\WindowsPowerShell\Modules;%SystemRoot%\system32\WindowsPowerShell\v1.0\Modules |
| TEMP | %SystemRoot%\TEMP |
| TMP | %SystemRoot%\TEMP |
| USERNAME | SYSTEM |
| windir | %SystemRoot% |
具体步骤:
1. 双击运行“C:\Windows\System32\SystemPropertiesAdvanced.exe”
2. 点击“环境变量”按钮进入环境变量界面
3. 在“用户变量”和“系统变量”中将上表缺少的默认变量和值输进去
4. 完成编辑后点击“确认”保存
注意:如果“C:\Windows\System32\SystemPropertiesAdvanced.exe”程序双击无法运行,一些系统设置如注册表、音量设置、防火墙、高级系统设置等等都无法打开,或很多程序无法以管理员身份运行,又或者所有的系统文件夹在菜单栏都显示成这样:
那么就要重启电脑进入安全模式进行以上操作,因为此时所有操作都无法以管理员身份运行。很多人就因为这样而无法操作成功,以失败而告终。
Tips:
如何进入“安全模式”?
有两种版本的安全模式:安全模式和网络安全模式。虽然它们非常相似,但是网络安全模式包含网络驱动程序和服务,你将需要访问 Internet 和网络上的其他计算机。
一、通过“设置”
1. 按键盘上的 Windows 徽标键 + I 可打开“设置”。如果不起作用,请选择屏幕左下角的“开始”按钮,然后选择“设置”。
2. 依次选择“更新和安全” >“恢复”。
3. 在“高级启动”下,选择“立即重启”。
4. 在电脑重启到“选择一个选项”屏幕后,依次选择“疑难解答”>“高级选项”>“启动设置”>“重新启动”。
5. 在电脑重新启动后,你将看到一列选项。选择 4 或 F4 以在“安全模式” 下启动电脑。或者,如果你需要使用 Internet,请选择“5”或“F5”进入“网络安全模式”。
二、通过登录屏幕
1. 重新启动你的电脑。当你进入到登录屏幕后,在按住 Shift 键的同时依次选择“电源”“重新启动”。
2. 在电脑重启到“选择一个选项”屏幕后,依次选择“疑难解答”>“高级选项”>“启动设置”>“重新启动”。
3. 在电脑重新启动后,你将看到一列选项。选择“4”或“F4”以在“安全模式”下启动电脑。或者,如果你需要使用 Internet,请选择“5”或“F5”进入“网络安全模式”。
三、通过重启
1. 重新启动你的电脑,狂按F8,选择安全模式进入
四、msconfig
1、鼠标点击Win10系统电脑桌面左下角的“开始”菜单,选择运行选项;
2、在打开的运行对话框里输入命令“msconfig”字符命令,点击确定键;
3、在打开的系统配置窗口,切换到“引导”标签,在引导选项下勾选安全引导(F),点击确定键;
勾选安全引导(F)
4、点击后,系统提示重新启动后,会进入安全模式;
五、有时候前面几种都还是进步了安全模式,那就可以试下这个暴力的方法,关机后,按下开机,启动界面时长按开机键强制关机,重复3次左右后再开机,就会进入修复模式,这时候就进入了类似方法二的 2 3步骤从而进入安全模式。
进入安全模式后,和之前的方法一样,打开C:\Windows\System32\SystemPropertiesAdvanced.exe, 添加环境变
windir=c:\windows,这样重启后,就能正常使用了。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









