







支持向量机模型实验指导书
一:实验目的
1.了解支持向量机模型相关知识。
2.学习scikit-learn机器学习库的基本使用。
二:实验环境
需要安装的库:
- python3.6+
- numpy
- matplotlib
- sklearn
三:实验内容
随机生成一组数据,数据格式为(x1,x2),同时数据划分为2类,分别为0和1。比如样本(x1,x2)属于0类。使用以上数据训练支持向量机模型,得到最优的超平面,输出模型参数W和b。并对新出现的样本,预测样本属于哪个类别。
四:实验步骤
- 环境搭建
Win10系统中安装python3.6,然后使用pip安装所需要的各个库。
命令如下:
pip install 库名 - 随机生成数据
随机生成40个样本数据,数据分为两类。 数据格式为(x1,x2,y),x1、x2为数据的特征,y是数据所属类别。
五:参考代码
SupportVectorMachine.py:
#encoding=utf-8
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
“”"
--------获取数据--------
随机生成40个独立的点,一共有两类
X数据格式[[6.37734541 ,-10.61510727],[6.50072722 ,-3.82403586]…]
Y数据格式[1 0 1 0 1 …1 0 1] 0和1代表类别
“”"
train_num=40
test_num=20
#随机生成2类数据,一共含40个样本
X,Y=Data.make_blobs(n_samples=train_num,centers=2,random_state=6)
plt.scatter(X[:,0],X[:,1],c=Y)
“”"
--------训练SVM模型--------
kernel=‘linear’ 核函数选择Linear核,主要用于线性可分的情形。参数少,速度快。
C=1000 惩罚参数,C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,
趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,
将他们当成噪声点,泛化能力较强。
“”"
lin=svm.SVC(kernel='linear',C=1000)
lin.fit(X,Y)
print('权重参数:',lin.coef_)
print("偏置项:",lin.intercept_)
print("支持向量:",lin.support_vectors_)
#输入参数并预测
x_,y_=X,Y=Data.make_blobs(n_samples=test_num,centers=2,random_state=6)
predict=lin.predict(x_)
acc_num=sum(y_==predict)
print("分类准确率:",acc_num/test_num)
“”"
--------可视化(作为了解)--------
“”"
ax=plt.gca()
xlim=ax.get_xlim()
ylim=ax.get_ylim()
xx=np.linspace(xlim[0] , xlim[1],30)
yy=np.linspace(ylim[0] , ylim[1],30)
YY , XX=np.meshgrid(yy ,xx)
xy=np.vstack([XX.ravel(),YY.ravel()]).T
Z=lin.decision_function(xy).reshape(XX.shape)#绘制出支持向量机的分割界核分割面
ax.contour(XX, YY,Z,color='g' ,levels=[-1,0,1],alpha=0.5,linestyles=['--','-','--'])
ax.scatter(lin.support_vectors_[:,0],lin.support_vectors_[:,1],linewidth=1,facecolors='red')
plt.scatter(x_[:,0],x_[:,1],c=predict,marker='x')
plt.show()
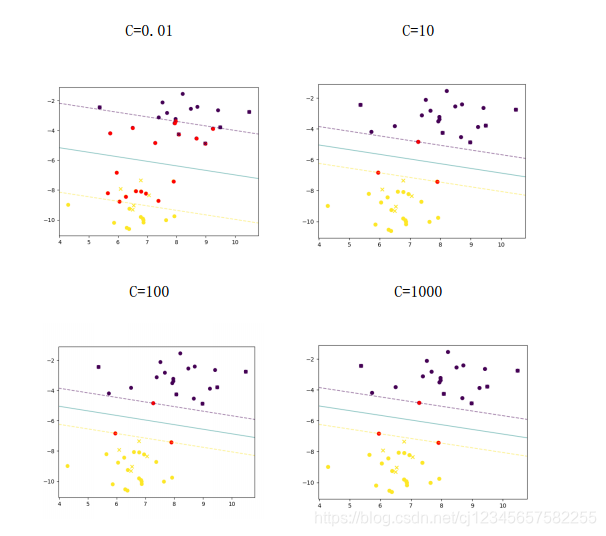
图一 不同的C值影响
结果分析:当C越大时,SVM的训练拟合结果越好,而泛化能力却会有一定下降。















 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









