







From the machine learning held by Andrew Ng in Coursera, I have learned these two concepts. When you are training data and find results not so good, you want to find where the problem comes out. He has mentioned if both training error and cross validation error are high, you probably have the bias problem, which is underfitting. If your training error is low but cross validation error is far higher than training error, you probably have the variance problem, which is overfitting.
When I first learned this, I just memorized the two concepts without understanding why the first situation corresponds to "bias" and the second situation corresponds to "variance".
Yesterday I learned it from deep learning class.
When we are training data from a model, it is same to estimate value of parameters from given data. The parameters have ground truth value but we may not recover them from data. If the expectation of estimate values (with respect to random choice of data) is ground truth value, then the model is suitable. So we call the difference between the two is bias.
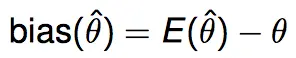
If bias is large as data size goes up, then there is a gap between estimation and ground truth. So the model cannot explain data well no matter how many data we will use. This means the concavity of model cannot cover data. So we have to increase concavity, or complexity of model. That's the problem of under-fitting.
The "variance" is the variance of estimated parameters.
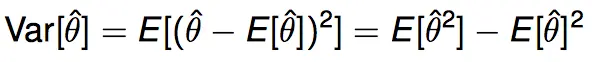
Variance typically decreases as the size of train data set increases. Because the model has a degree of complexity, and more data will give more control of the complexity. For example, if data comes from a 5-th degree polynomial and you train with 10-th degree polynomial model, then using small data set may give you improper results, like a real 10-th degree polynomial model. But using large data set will more probably give you a 5-th degree polynomial. High variance corresponds to overfitting problem, because estimation varies a lot between different data, that means we fit each data too much. To fix the problem of overfitting, we need to make size of data and model complexity compatible. Using more data and decreasing feature numbers are two good ways.
The sum of bias and variance is estimation error, which describes the difference between estimated value and ground truth value.
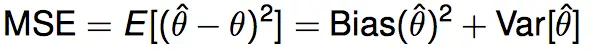
The expectation is taken over all possible data. So if we fix data size, then the left side is constant, resulting right side is fixed. Therefore, if bias increases, variance will decrease. That's why if we increase model complexity, we will fix high bias problem but may result in high variance. Usually data scientists are trying to find a balance from this equation.















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









