






ORA-00600: 内部错误代码, 参数: [13013]
数据库版本:Oracle 11.2.0.1.0
数据库服务器操作系统:Windows server 2008
错误号(1):ORA-00600: internal error code, arguments: [13013], [5001], [267], [8460734], [2], [8460734], [17], [], [], [], []
详细报错如下:
Mon May 30 11:40:28 2016
Errors in file e:\app\administrator\diag\rdbms\klnew\klnew\trace\klnew_smon_2184.trc (incident=93782):
ORA-00600: internal error code, arguments: [13013], [5001], [267], [8460734], [2], [8460734], [17], [], [], [], [], []
Incident details in: e:\app\administrator\diag\rdbms\klnew\klnew\incident\incdir_93782\klnew_smon_2184_i93782.trc
Non-fatal internal error happenned while SMON was doing logging scn->time mapping.
SMON encountered 3 out of maximum 100 non-fatal internal errors.
Mon May 30 11:40:30 2016
问题现象(1):
SMON encountered 3 out of maximum 100 non-fatal internal errors.
数据库运行一段时间,实例自动关闭;
查看:klnew_smon_2184_i93782.trc
========= Dump for incident 93782 (ORA 600 [13013]) ========
*** 2016-05-30 11:40:28.480
dbkedDefDump(): Starting incident default dumps (flags=0x2, level=3, mask=0x0)
----- Current SQL Statement for this session (sql_id=dma0vxbwh325p) -----
update smon_scn_time
set time_mp = :1,
time_dp = :2,
scn = :3,
scn_wrp = :4,
scn_bas = :5,
num_mappings = :6,
tim_scn_map = :7
where scn = (select min(scn) from smon_scn_time)
错误号(2):ORA-00600: internal error code, arguments: [13011], [267], [8460734], [2], [8460734], [17], [], [], [], [], [], []
详细报错如下:
Mon May 30 11:30:24 2016
Errors in file e:\app\administrator\diag\rdbms\klnew\klnew\trace\klnew_smon_2184.trc (incident=93780):
ORA-00600: internal error code, arguments: [13011], [267], [8460734], [2], [8460734], [17], [], [], [], [], [], []
Incident details in: e:\app\administrator\diag\rdbms\klnew\klnew\incident\incdir_93780\klnew_smon_2184_i93780.trc
Non-fatal internal error happenned while SMON was doing logging scn->time mapping.
SMON encountered 1 out of maximum 100 non-fatal internal errors.
Mon May 30 11:30:26 2016
问题现象(2):
SMON encountered 3 out of maximum 100 non-fatal internal errors.
数据库运行一段时间,实例自动关闭;
查看klnew_smon_2184_i93780.trc:
========= Dump for incident 93780 (ORA 600 [13011]) ========
*** 2016-05-30 11:30:24.650
dbkedDefDump(): Starting incident default dumps (flags=0x2, level=3, mask=0x0)
----- Current SQL Statement for this session (sql_id=gm9t6ycmb1yu6) -----
delete from smon_scn_time where scn = (select min(scn) from smon_scn_time)
错误号(3):ORA-00600: internal error code, arguments: [13013], [5001], [456], [4338038], [0], [4338038], [17], [], [], [], [], []
详细报错如下:
Fri May 27 17:25:50 2016
Errors in file e:\app\administrator\diag\rdbms\klnew\klnew\trace\klnew_smon_516.trc (incident=90132):
ORA-00600: internal error code, arguments: [13013], [5001], [456], [4338038], [0], [4338038], [17], [], [], [], [], []
Incident details in: e:\app\administrator\diag\rdbms\klnew\klnew\incident\incdir_90132\klnew_smon_516_i90132.trc
Non-fatal internal error happenned while SMON was doing flushing of monitored table stats.
SMON encountered 1 out of maximum 100 non-fatal internal errors.
问题现象(3):
数据库无法通过shutdown immediate方式关闭,只能通过shutdown abort关闭
查看:klnew_smon_516_i90132.trc
========= Dump for incident 90132 (ORA 600 [13013]) ========
*** 2016-05-27 17:25:50.929
dbkedDefDump(): Starting incident default dumps (flags=0x2, level=3, mask=0x0)
----- Current SQL Statement for this session (sql_id=3c1kubcdjnppq) -----
update sys.col_usage$
set equality_preds = equality_preds +
decode(bitand(:flag, 1), 0, 0, 1),
equijoin_preds = equijoin_preds +
decode(bitand(:flag, 2), 0, 0, 1),
nonequijoin_preds = nonequijoin_preds +
decode(bitand(:flag, 4), 0, 0, 1),
range_preds = range_preds + decode(bitand(:flag, 8), 0, 0, 1),
like_preds = like_preds + decode(bitand(:flag, 16), 0, 0, 1),
null_preds = null_preds + decode(bitand(:flag, 32), 0, 0, 1),
timestamp = :time
where obj# = :objn
and intcol# = :coln
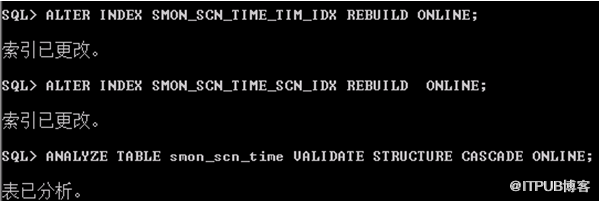
解决方案:
ORA-00600: [13013], [5001], [267]
ORA-00600: [13011], [267]
select * from dba_objects where object_id=267;

select * from dba_ind_columns where table_name='SMON_SCN_TIME';

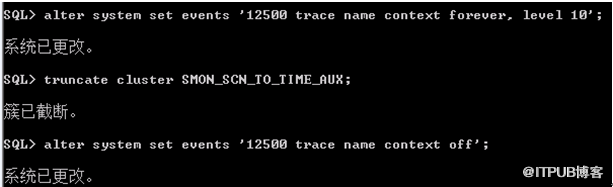
ORA-00600: [13013], [5001], [456]
select * from dba_objects where object_id=456;
![]()
select * from dba_ind_columns where table_name='COL_USAGE$';
select dbms_metadata.get_ddl('INDEX','I_COL_USAGE$','SYS') from dual;

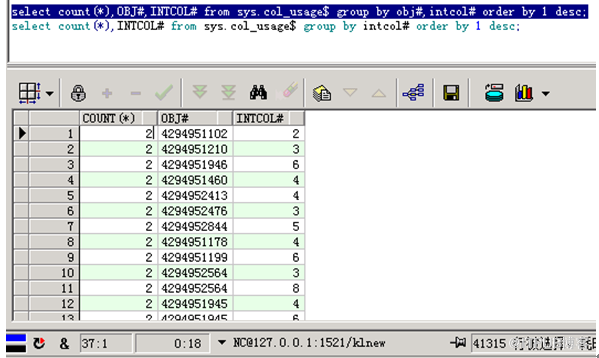
唯一索引里出现了重复数据
删除索引I_COL_USAGE$,重建非唯一索引;
其中MOS中查询有关ORA-00600[13013]问题相关信息;
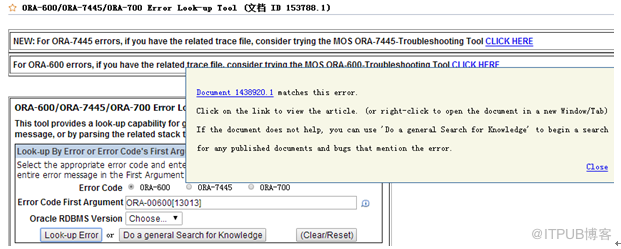
| New and Improved: ORA-600 [13013] "Unable to get a Stable set of Records" (文档 ID 1438920.1) |
|
|
| ***Checked for relevance on 10-Jul-2015*** Note: For additional ORA-600 related information please read Note: 146580.1 PURPOSE: This article is a new and improved copy of OERI Note: 28185.1 which is designed to pilot a new feature to help identify known bugs for ORA-600[13013] issues. If you do not want to use the new feature, please use the original Note: 28185.1. The new feature available in this version of the OERI note provides a list of conditions most commonly identified for bugs related to this error. These conditions can be used to narrow down the possible cause of the error. Our goal with this pilot is to determine if this level of detail will lead our readers to a quicker resolution. After having used this new feature, please email Vickie.Carbonneau with your feedback. Please provide answers to the following:
This article has been published because the ORA-600 error has been reported in at least one confirmed bug. ERROR: Format: ORA-600 [13013] [a] [b] [c] [d] [e] [f] VERSIONS: versions 6.0 and above DESCRIPTION: During the execution of an UPDATE statement, after several attempts (Arg [a] passcount) we are unable to get a stable set of rows that conform to the WHERE clause. ARGUMENTS: The number of arguments and their meaning vary depending on the Oracle 2 Argument format This format relates to Oracle Server 8.0.4 and above and Index Only Tables (IOT) Arg [a] Passcount 5 Argument format This format relates to Oracle Server 6.0 to 7.3.4 Arg [a] Passcount 6 Argument format This format relates to Oracle Server 8.0.3 and above Arg [a] Passcount FUNCTIONALITY: Update Execute IMPACT: PROCESS FAILURE SUGGESTIONS: This error could indicate a corrupt index. Check for corrupted indices using the following command : ANALYZE TABLE VALIDATE STRUCTURE CASCADE; Where is the table being updated. Drop and recreate any indexes that show problems. On Parallel Server instances (OPS - Oracle Server <= 7.X) this can be due to an inappropriate setting of max_commit_propagation_delay. Setting this parameter to 0 can avoid this error. For 7.3.2 releases please see ALERT: 40673.1 ALERT: Incorrect Results or Internal Errors from Indexed Table Access If the Known Issues section below does not help in terms of identifying a solution, please submit the trace files and alert.log to Oracle Support Services for further analysis.
KNOWN BUGS:
|
| Bug 9469117 - Corrupt index after PDML executed in serial. Wrong results. OERI[kdsgrp1]/ORA-1499 by analyze (文档 ID 9469117.8) |
|
|
|
Bug 9469117 Corrupt index after PDML executed in serial. Wrong results. OERI[kdsgrp1]/ORA-1499 by analyze This note gives a brief overview of bug 9469117. Affects:
Fixed:
DescriptionIndex maintenance is not being done for UPDATE/DELETE/MERGE statements that UPDATE/DELETE only one row when a parallel plan (PDML) is executed in serial; e.g., there are not enough parallel server processes. Example: alter session enable parallel dml; update tbug set col1=30 where col1=9; -> this statement is executed in serial instead of parallel and updates one row only as col1 is a unique key. As the index is inconsistent with the table, this results in a corrupt index causing wrong results or errors like: ORA-600 [kdsgrp1] ORA-600 [qertbFetchByRowID] ORA-600 [13013] with error code 17 KDCMPF11 by an update ORA-8102 ORA-1499 by "analyze table validate structure cascade" with a trace file containing error messages like: "Table/Index row count mismatch" "row mismatch in index" Workaround To avoid the problem: Make sure that there are enough parallel server processes (increase parallel_max_servers) or Execute the DML statement in serial (disable Parallel DML). To repair the index inconsistency, Drop/Create the index.
References Bug:9469117 (This link will only work for PUBLISHED bugs) | ||||||||||||||||||||||||||
| Bug 9229891 - Bitmap index corruption by update or delete with error logging (文档 ID 9229891.8) |
|
|
|
Bug 9229891 Bitmap index corruption by update or delete with error logging This note gives a brief overview of bug 9229891. Affects:
Fixed:
DescriptionA Bitmap index can be missing keys after UPDATE or DELETE when error logging is used (DBMS_ERRLOG.CREATE_ERROR_LOG). Wrong result or next errors can be produced: ORA-1499 by "analyze validate structure cascade" and trace file has: "row not found in index" ORA-600[13013] with error code 17 (KDCMPF11) by an update
References Bug:9229891 (This link will only work for PUBLISHED bugs) |
| High Executions Of Statement "delete from smon_scn_time..." (文档 ID 375401.1) |
|
|
| In this Document
APPLIES TO: Oracle Database - Enterprise Edition - Version 10.1.0.2 to 10.2.0.4 [Release 10.1 to 10.2] A delete from smon_scn_time is performing excessive gets and executions as viewed from AWR report: Buffer Gets Executions Gets per Exec %Total CPU Time (s) Elapsed Time (s) There are inconsistencies between the indexes and table smon_scn_time. To implement the solution, please execute the following steps: 1. Ensure you have a usable backup in case of failures 2. Drop and recreate the indexes on table smon_scn_time connect / as sysdba |
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/29785807/viewspace-2118427/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/29785807/viewspace-2118427/















 8078
8078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









