







导读:最近在进行sql编写时,发现delete +using性能并不高, 这篇文章主要通过执行计划对多表关联删除操作进行性能分析,并给出另一种高性能exists关联删除的方法,具有很好的参考价值,希望对大家有所帮助。
postgresql特有一种多表关联删除的写法,使用delete using语法。本人公司所使用的是Gauss DB分布式数据库,其基于postgresql内核打造,同样适用delete using语句进行多表关联删除,但此类语句在业务使用过程中发现其效率并不高。经过实验测试发现当外表的关联数据存在重复值时,效率下降明显。
使用delete using的写法
delete from test1 a using test2 b where a.id<b.id and a.name=b.name;
using 有点类似子查询,可以关联包含在where子语句中的字段的表。本例子中的a.id<b.id就是筛选出a表中id小于b表中id的记录。
delete using多表关联删除性能分析
我们对建立两张表test1和test2,其中test1为主表,test2为关联的外表。利用test2中的statistics_dt关联删除test1中的数据。
create table maple.test1 (statistics_dt date, id int) DISTRIBUTE BY HASH(id);
create TEMP table test2 (statistics_dt date, id int) DISTRIBUTE BY HASH(id);
insert into maple.test1 values ('20210708',1);
insert into maple.test1 values ('20210708',2);
insert into maple.test1 values ('20210708',4);
insert into maple.test1 values ('20210708',5);
insert into maple.test1 values ('20210708',6);
insert into maple.test1 values ('20210709',1);
insert into maple.test1 values ('20210709',2);
insert into maple.test1 values ('20210709',3);
insert into test2 values ('20210708',1);
insert into test2 values ('20210708',2);
insert into test2 values ('20210708',3);
我们使用insert into select的语法对将要删除的test1表进行数据翻倍处理:
insert into maple.test1 select * from maple.test1
多次执行后,test1的表的数据量到达2048条。为了确保执行计划的准确性,对两张表进行统计信息收集,并打印执行计划。
analyze test2;
analyze maple.test1;
explain delete from maple.test1 t1
using test2 t2
where 1=1 and t1.statistics_dt=t2.statistics_dt;
执行计划如下:
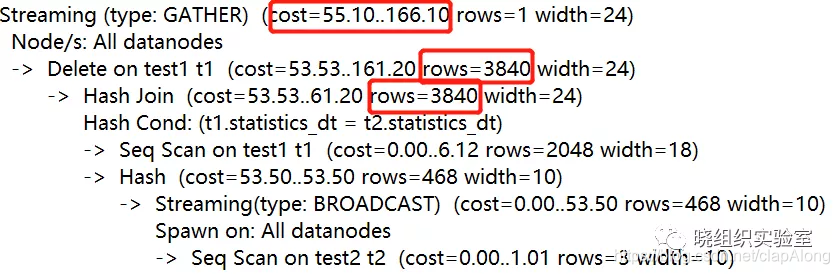
可以发现,在关联删除时,预计删除test1的数据数量为3840条,远远超过test1中原有的2048条数据。这是为什么呢?
查询test1和test2的关联字段statistics_dt可以发现,test2中只有三条statistics_dt为20210708的数据,而test1的statistics_dt字段有20210708和20210709两个值,且经过我们多次插入后,两者数据量分别为1280和768。两者关联删除时,在statistics_dt字段为20210708的日期中出现笛卡尔积,刚好达到数据量为1280*3=3840条,导致cost值上升。在关联中出现笛卡尔积是一件非常可怕且难以预料的事情,尤其是分布式数据库中表的数据量常常是千万级,这更是一场可怕的灾难。下一节将介绍使用exists方式进行多表删除。
exists多表关联删除
先附上exists多表关联删除的写法及执行计划:
delete from maple.test1 t1
where exists(
select 1 from test2 t2
where 1=1 and t1.statistics_dt=t2.statistics_dt
);

可以发现cost从delete using的166.10下降到89.41,执行效率提升了接近一倍,是不是突然兴奋了起来。但是为什么同样的数据,不同的写法执行效率会差距这么大呢,这么长的执行计划该如何去看呢。没关系,我已经将重点用红圈画起来了。可以看到,exists的写法在对test1删除时,删除的数据量为1280,刚好对应test1中20210708的数据条数,并没有出现笛卡尔积。
再往下翻阅执行计划时,出现了group by的语句,使用group by进行去重也是我们应对笛卡尔积的常用手法之一。
看来原因找到了,使用exists语句进行多表关联时,首先会对外表进行group by操作,再进行关联操作,大大减少了关联的结果集,运行效率当然会快。(应该不会有人外表是大表,内表是小表进行关联吧)
有人会问了,你这是test2表中出现了重复值造成的,如果test2表中没有重复值,两者的性能又如何呢?
这次我们对于test2中插入没有重复值的数据,如下:
insert into test2 values ('20210708',1);
insert into test2 values ('20210709',2);
insert into test2 values ('202107010',3);
delete using执行计划
Streaming (type: GATHER) (cost=1.92..109.52 rows=1 width=24)
Node/s: All datanodes
-> Delete on test1 t1 (cost=1.11..104.61 rows=2048 width=24)
-> Streaming(type: REDISTRIBUTE) (cost=1.11..52.61 rows=2048 width=24)
Spawn on: All datanodes
-> Hash Join (cost=1.11..52.20 rows=2048 width=24)
Hash Cond: (t1.statistics_dt = t2.statistics_dt)
Skew Join Optimized by Statistic
-> Streaming(type: PART REDISTRIBUTE PART ROUNDROBIN) (cost=0.00..50.92 rows=2048 width=18)
Spawn on: All datanodes
-> Seq Scan on test1 t1 (cost=0.00..6.12 rows=2048 width=18)
-> Hash (cost=1.10..1.10 rows=156 width=10)
-> Streaming(type: PART REDISTRIBUTE PART BROADCAST) (cost=0.00..1.10 rows=3 width=10)
Spawn on: All datanodes
-> Seq Scan on test2 t2 (cost=0.00..1.01 rows=3 width=10
exists执行计划
Streaming (type: GATHER) (cost=1.92..109.52 rows=1 width=24)
Node/s: All datanodes
-> Delete on test1 t1 (cost=1.11..104.61 rows=2048 width=24)
-> Streaming(type: REDISTRIBUTE) (cost=1.11..52.61 rows=2048 width=24)
Spawn on: All datanodes
-> Hash Semi Join (cost=1.11..52.20 rows=2048 width=24)
Hash Cond: (t1.statistics_dt = t2.statistics_dt)
Skew Join Optimized by Statistic
-> Streaming(type: PART REDISTRIBUTE PART ROUNDROBIN) (cost=0.00..50.92 rows=2048 width=18)
Spawn on: All datanodes
-> Seq Scan on test1 t1 (cost=0.00..6.12 rows=2048 width=18)
-> Hash (cost=1.10..1.10 rows=156 width=10)
-> Streaming(type: PART REDISTRIBUTE PART BROADCAST) (cost=0.00..1.10 rows=3 width=10)
Spawn on: All datanodes
-> Seq Scan on test2 t2 (cost=0.00..1.01 rows=3 width=10)
可以看到,两者的执行计划中cost值相同,删除的数据条数也同为2048条。delete using的方法并没有出现笛卡尔积,而exists方法在Seq Scan 扫描后,也没有出现group by。执行计划中,只有第6行的hash join不同,也就说明两者在关联时,关联字段在外表中不存在重复值时,两者的执行效率是相同的。
总结
在进行多表关联删除操作时,外表与内表相比,常常都是数据量很小的小表,采用exists关联删除的方法,可以在关联前对外表进行group by操作,有效避免因外表出现重复值而造成关联删除中出现笛卡尔积的现象。与delete using语句相比,exists关联删除性能更高,值得大家在业务场景中进行借鉴。
在列存表的业务场景中,使用exists关联删除还可以避免一些因列存表存储机制,造成并发删除同一张表而引发error的问题,因篇幅有限,将在后续的文章中介绍到。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









