






近期,IDC发布了《数据要素全景研究,2024》报告,预测数据要素市场将在2024年迎来快速发展期。作为入选了该报告的代表企业之一,腾讯云一直致力于提供全面的数据要素解决方案。腾讯云大数据 TBDS+WeData 解决方案,能够为企业提供从数据采集、存储、治理、分析到应用的全链路数据要素服务,帮助企业高效挖掘数据价值,助力产业数字化升级。
报告指出,数据要素市场是利用公共数据、企业数据、个人数据进行数据的价值化,为产业生产和社会发展服务。数据要素市场的发展,尤其是生成式AI技术提供了前所未有的从非结构化数据中提取价值的能力,将驱动数据基础设施、数据治理、数据安全、数据应用等相关产业的快速增长。
国家数据局发布的《“数据要素×”三年行动计划(2024—2026年)》中提出,构建以数据为关键要素的数字经济,赋能与推动经济社会高质量发展。到2026年底,数据要素应用广度和深度大幅拓展,数据产业年均增速预计超过20%,数据交易规模翻倍,数据要素在经济发展中的乘数效应将更加明显。
作为国内领先的云计算服务商,腾讯云在数据要素市场已有多年的布局,拥有深厚的技术积累和丰富的行业经验。 腾讯云大数据 TBDS + WeData 解决方案,通过自主创新大数据存算底座和全链路数据开发与数据资产治理平台,提供全链路DataOps数据开发能力、数据资产、数据地图、数据质量、数据安全等一系列数据治理和运营能力,帮助企业在数据资产与数据要素构建与应用过程中提高数据开发效率,提升数据质量,建立常态化数据要素运营能力,实现数据价值增长。
//腾讯云大数据 TBDS+WeData 在数据要素市场中的优势
腾讯云大数据 TBDS+WeData 方案在数据要素市场可作为承载可信空间建设的数据底座,同时提供了数据资产管理、数据开发治理和湖仓一体的支撑能力。产品技术架构完全适配数据要素技术要求,包括:
● 数据采集: 支持异构数据高效入湖。
● 存储: 支持多种存储格式,数据湖上的数据无需搬迁即可建仓。
● 计算: 支持存算分离,容器化虚拟计算引擎,适应多种计算场景。
● 元数据: 统一管理湖仓元数据。
● 安全: 完备的数据安全体系,包括授权认证和权限管控。
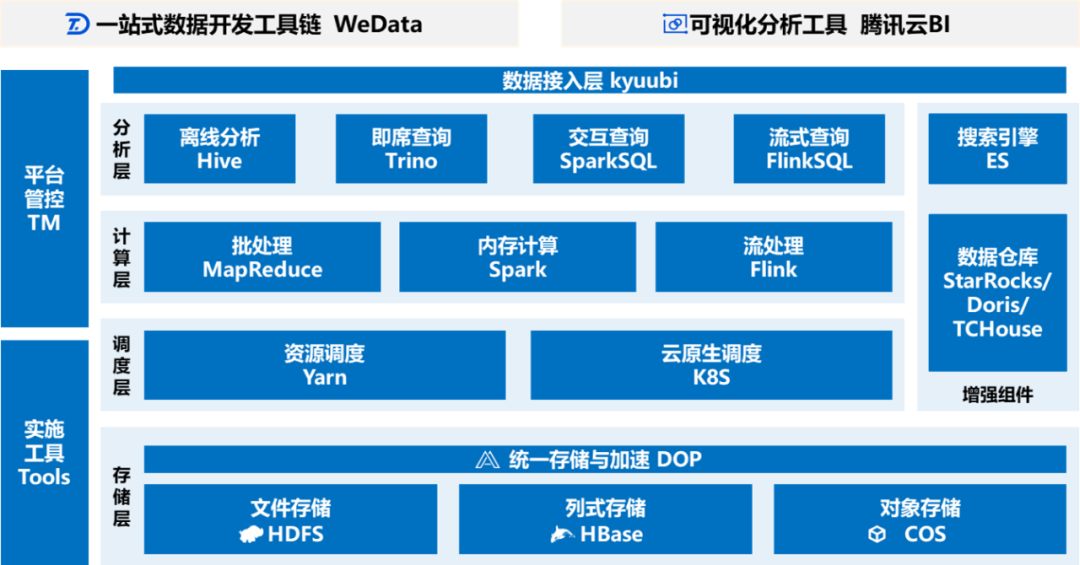 架构图
架构图
腾讯云大数据 TBDS+WeData 方案的具体优势体现在:
技术创新性:
● 湖仓融合架构,在统一资源、数据和安全管理方面具有较高的技术创新性和架构先进性,同时支持新老架构的平滑演进。
安全可靠与性能卓越:
● 5A安全体系,平台高可用与多场景容灾方案,拥有10万+节点集群大规模运营经验,基于开源组件深度优化性能。
定制与适应性服务:
● 深耕行业领域,在金融等特定领域按需提供定制化服务和多场景解决方案。
生态兼容与全面开放:
● 全面兼容开源生态,与各行业优秀的大数据开发治理服务及应用商深度合作,为行业客户提供“基础软件平台+应用+服务”的专业一体化大数据解决方案。
//腾讯云大数据在数据要素产业的实践
腾讯云已与多个行业的头部客户开展了数据要素市场合作。近期,腾讯云大数据方案成功助力某一线城市的政务公共数据授权和运营项目,充分展示了其在数据要素产业中的领先能力。该项目中,腾讯云大数据 TBDS+WeData 方案提供了高效的数据存储、计算、安全和服务能力。项目创新性地采用“一场景、一清单、一授权”模式,严格遵守数据合规要求,确保数据使用的合法性和合规性。此外,项目遵循数据可用不可见原则,利用隐私计算平台和可信数据平台对公共数据进行产品化,并在接入数据可信计算安全域后进行访问,有效提升数据使用效率,为数据安全和隐私保护提供了坚实保障。
未来,腾讯云大数据将继续与合作伙伴携手,深入探索数据要素市场,帮助企业释放数据要素价值,推动数字经济的高质量发展。
关注腾讯云大数据公众号
邀您探索数据的无限可能

点击阅读原文,了解更多产品详情
↓↓↓














 1832
1832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









