






简单案例描述:
某运营商持续出现library cache lock,library cache load lock以及library cache latch冲突,即使是重新启动之后也只是简单缓解之后很快就会继续发生状况。初步判断是shared pool不足引起,持续观察shared pool,发现自由空间不断的迅速减少,当减少到一定程度之后出现大量libray cache lock和library cache load lock。由于系统中存在大量的hard parse,增加cursor sharing之后,该问题基本消失。但是由于打开cursor sharing之后导致部分业务不可继续,无法启用cursor sharing。最后通过持续监控shared pool,在shared pool达到阀值之后进行flush pool,该问题得到控制。最后我们判断为Oracle bug,Oracle无法正确处理shared pool的lru策略,等待Oracle patch。后续补丁到位之后,打上补丁,该问题消失。
我们本章来讨论两个常见的队列锁:row cache lock和library cache lock,library cache load lock
row cache: Oracle数据字典的缓存,其作用为了加速对于Oracle数据字典的访问。row cache是Oracle buffer cache的缓存,采用更加高效的方法来组织对于数据字典的访问。Oracle一直在做这方面的努力,比如现在把undo segment的部分事务访问也从buffer cache中复制出来在shared pool中进行缓冲处理,以更好的处理undo segment的并发和响应的问题,这就是in memory undo。
row cache lock主要用来保护对于数据字典的更新,显然当row cache更新频繁的时候会产生比较大的row cache lock需求。

在实践中似乎没有看到row cache lock的共享锁定,基本是独占锁。也就是说数据字典发生了更新。
dc_database_link: link$
dc_files: file$
dc_global_oid: global_names
dc_histogram_data: hist$
dc_object_grants: 权限相关
dc_object_ids: obj$
dc_objects: obj$
dc_rollback_segs: undo$
dc_segments: seg$
dc_sequence: seq$
dc_tablespace: ts$
dc_username: user$
dc_users: user$
以下row cache演化为全局
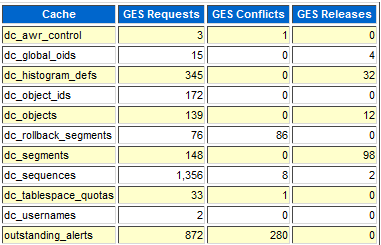
大家事实上可以发现,除了dc_sequence,其他的row cache lock几乎都只跟ddl操作有关。也是这个原因,大家在日常所看到的row cache lock几乎都是ddl操作引发的。至于在dc_sequence之上引发的row cache lock在上篇已经描述过不再重复。
其他容易引发问题的row cache:
dc_rollback_segments
dc_object_ids
dc_tablespace
dc_users
dc_rollback_segments:由于undo segment的offline,online以及autotune会导致频繁占用row cache lock。undo segment的New block和New extent应该不会引起在dc_rollback_segments上的row cache lock。
dc_object_ids:主要由于truncate引起,truncate引起data_object_id的变化会在dc_object_id上进行row cache lock锁定。
dc_tablespace:在New extent期间需要锁定tablespace的空间分配,可能需要在dc_tablespace进行row cache lock锁定。
dc_users:更多的发生在授权操作上
明了以上原因之后,row cache lock除了sequence采用cache处理之外,其他处理都是尽可能避免在业务高峰期进行ddl操作。
其他的关键识别在于New block和New extent是否会产生row cache lock,如果会产生,则会产生dc_segment,dc_rollback_segments上面的冲突。目前倾向于仅仅在dc_tablespace上锁定。Oracle应该在segment header处理采用 buffer lock会更加合理,而不是采用row cache lock。这个是否如此,只要简单的并发性insert案例就可以测试出来,在有时间的时候后续会进行测试验证。
当然,除此以外,第一次的从buffer cache到row cache的加载自然会产生row cache lock。也就是当数据字典第一次从磁盘缓冲到buffer cache的时候会发生row cache lock锁定的需求。至于在buffer cache被清理出buffer cache,是否会同时清理出row cache,有待验证。个人倾向于保留row cache的内容。
大部分row cache对象会在parse阶段进行加载,也就是parse过程中会产生row cache lock,但是row cache lock和是否更多hard parse没有必然的联系。
LIBRARY CACHE LOCK:
library cache lock作用parse过程中,在parse过程中,发现library cache object不存在,则依次加载LIBRARY CACHE LOAD LOCK和LIBRARY CAHCE LOCK,LIBRARY CACHE LOAD LOCK基本是独占的,而LIBRARY CACHE LOCK基本是共享的(只有在加载尽library cache期间是独占的,随即很快下降为共享锁)。
LIBRARY CAHCE中任何对象,除了cursor之外都受到library cache lock的保护,包括table,index,package,view,sequence,execute plan,pcode等等。
共享锁主要是为了防止object被改变,library cache lock的冲突主要发生在获得独占锁,或者在共享锁升级为独占锁。
由此可以知道library cache lock的冲突主要发生在以下情况:
parse过程的对象加载
ddl操作引起依赖对象无效
library cache lock会演变为全局锁,使其在RAC系统比较一般系统出现的更加频繁,防御措施最简单的方式为避免在业务高峰期执行DDL操作。
hard parse并不会增加在object上的library cache冲突,但是显然在执行计划和pcode层面上会存在问题(事实上,这个存在疑问,是否需要library cache lock的保护)。
虽然如此,hard parse会更加频繁的进行library cache lock的加载,hard parse会引起library cache object不断被交换出shared_pool,产生更多的library cache lock需求,所以说hard parse和library cache lock具有一定的关系。
如何降低library cache lock的冲突:
(1)、增加shared_pool,避免shared_pool空间不足
(2)、降低hard parse
(3)、避免在业务高峰期进行ddl操作以及flush shared pool操作。
从理论上来讲,library cache的根本问题在于shared pool不足引起,而hard parse系统必然会导致再大的shared pool也会快速用光。当然ddl操作自然会引起该问题。
至于在发生了row cache lock和library cache lock的冲突之后这么办,几乎别无他法,只能kill hold process,个别情况下flush shared pool具有一定的作用。
某运营商持续出现library cache lock,library cache load lock以及library cache latch冲突,即使是重新启动之后也只是简单缓解之后很快就会继续发生状况。初步判断是shared pool不足引起,持续观察shared pool,发现自由空间不断的迅速减少,当减少到一定程度之后出现大量libray cache lock和library cache load lock。由于系统中存在大量的hard parse,增加cursor sharing之后,该问题基本消失。但是由于打开cursor sharing之后导致部分业务不可继续,无法启用cursor sharing。最后通过持续监控shared pool,在shared pool达到阀值之后进行flush pool,该问题得到控制。最后我们判断为Oracle bug,Oracle无法正确处理shared pool的lru策略,等待Oracle patch。后续补丁到位之后,打上补丁,该问题消失。
我们本章来讨论两个常见的队列锁:row cache lock和library cache lock,library cache load lock
row cache: Oracle数据字典的缓存,其作用为了加速对于Oracle数据字典的访问。row cache是Oracle buffer cache的缓存,采用更加高效的方法来组织对于数据字典的访问。Oracle一直在做这方面的努力,比如现在把undo segment的部分事务访问也从buffer cache中复制出来在shared pool中进行缓冲处理,以更好的处理undo segment的并发和响应的问题,这就是in memory undo。
row cache lock主要用来保护对于数据字典的更新,显然当row cache更新频繁的时候会产生比较大的row cache lock需求。
在实践中似乎没有看到row cache lock的共享锁定,基本是独占锁。也就是说数据字典发生了更新。
dc_database_link: link$
dc_files: file$
dc_global_oid: global_names
dc_histogram_data: hist$
dc_object_grants: 权限相关
dc_object_ids: obj$
dc_objects: obj$
dc_rollback_segs: undo$
dc_segments: seg$
dc_sequence: seq$
dc_tablespace: ts$
dc_username: user$
dc_users: user$
以下row cache演化为全局
大家事实上可以发现,除了dc_sequence,其他的row cache lock几乎都只跟ddl操作有关。也是这个原因,大家在日常所看到的row cache lock几乎都是ddl操作引发的。至于在dc_sequence之上引发的row cache lock在上篇已经描述过不再重复。
其他容易引发问题的row cache:
dc_rollback_segments
dc_object_ids
dc_tablespace
dc_users
dc_rollback_segments:由于undo segment的offline,online以及autotune会导致频繁占用row cache lock。undo segment的New block和New extent应该不会引起在dc_rollback_segments上的row cache lock。
dc_object_ids:主要由于truncate引起,truncate引起data_object_id的变化会在dc_object_id上进行row cache lock锁定。
dc_tablespace:在New extent期间需要锁定tablespace的空间分配,可能需要在dc_tablespace进行row cache lock锁定。
dc_users:更多的发生在授权操作上
明了以上原因之后,row cache lock除了sequence采用cache处理之外,其他处理都是尽可能避免在业务高峰期进行ddl操作。
其他的关键识别在于New block和New extent是否会产生row cache lock,如果会产生,则会产生dc_segment,dc_rollback_segments上面的冲突。目前倾向于仅仅在dc_tablespace上锁定。Oracle应该在segment header处理采用 buffer lock会更加合理,而不是采用row cache lock。这个是否如此,只要简单的并发性insert案例就可以测试出来,在有时间的时候后续会进行测试验证。
当然,除此以外,第一次的从buffer cache到row cache的加载自然会产生row cache lock。也就是当数据字典第一次从磁盘缓冲到buffer cache的时候会发生row cache lock锁定的需求。至于在buffer cache被清理出buffer cache,是否会同时清理出row cache,有待验证。个人倾向于保留row cache的内容。
大部分row cache对象会在parse阶段进行加载,也就是parse过程中会产生row cache lock,但是row cache lock和是否更多hard parse没有必然的联系。
LIBRARY CACHE LOCK:
library cache lock作用parse过程中,在parse过程中,发现library cache object不存在,则依次加载LIBRARY CACHE LOAD LOCK和LIBRARY CAHCE LOCK,LIBRARY CACHE LOAD LOCK基本是独占的,而LIBRARY CACHE LOCK基本是共享的(只有在加载尽library cache期间是独占的,随即很快下降为共享锁)。
LIBRARY CAHCE中任何对象,除了cursor之外都受到library cache lock的保护,包括table,index,package,view,sequence,execute plan,pcode等等。
共享锁主要是为了防止object被改变,library cache lock的冲突主要发生在获得独占锁,或者在共享锁升级为独占锁。
由此可以知道library cache lock的冲突主要发生在以下情况:
parse过程的对象加载
ddl操作引起依赖对象无效
library cache lock会演变为全局锁,使其在RAC系统比较一般系统出现的更加频繁,防御措施最简单的方式为避免在业务高峰期执行DDL操作。
hard parse并不会增加在object上的library cache冲突,但是显然在执行计划和pcode层面上会存在问题(事实上,这个存在疑问,是否需要library cache lock的保护)。
虽然如此,hard parse会更加频繁的进行library cache lock的加载,hard parse会引起library cache object不断被交换出shared_pool,产生更多的library cache lock需求,所以说hard parse和library cache lock具有一定的关系。
如何降低library cache lock的冲突:
(1)、增加shared_pool,避免shared_pool空间不足
(2)、降低hard parse
(3)、避免在业务高峰期进行ddl操作以及flush shared pool操作。
从理论上来讲,library cache的根本问题在于shared pool不足引起,而hard parse系统必然会导致再大的shared pool也会快速用光。当然ddl操作自然会引起该问题。
至于在发生了row cache lock和library cache lock的冲突之后这么办,几乎别无他法,只能kill hold process,个别情况下flush shared pool具有一定的作用。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/92650/viewspace-1062092/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/92650/viewspace-1062092/















 3606
3606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









