






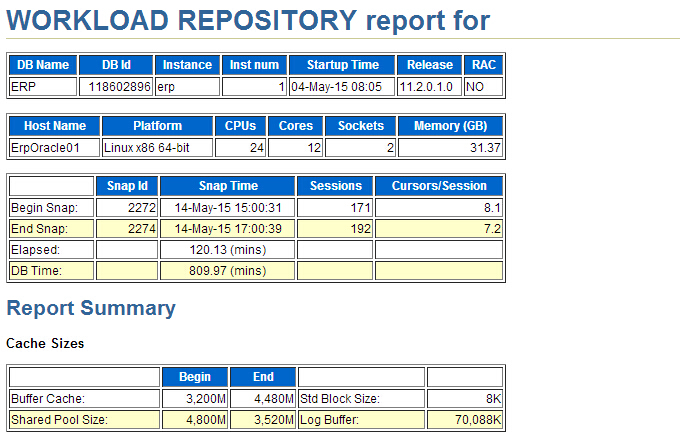
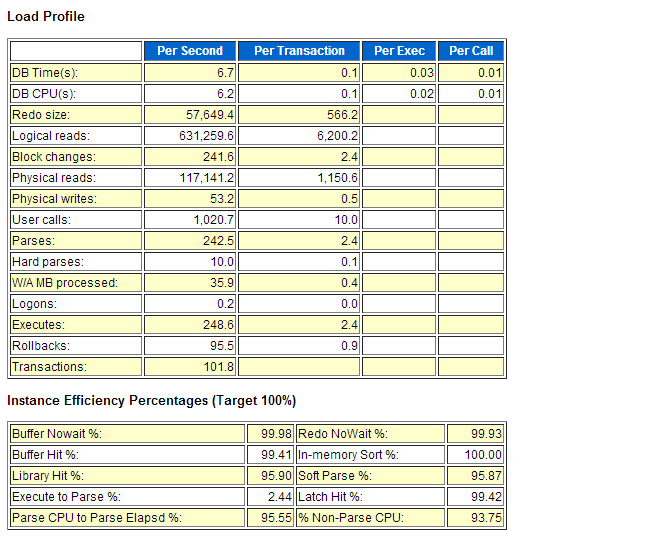
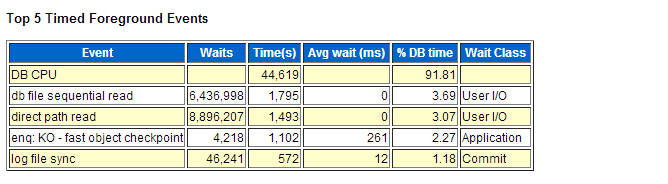
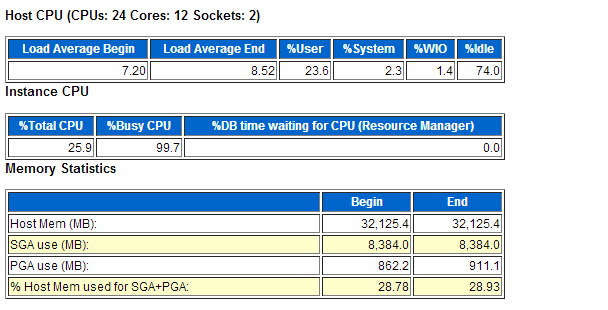
朋友公司一个erp系统业务办理不了,但从前台等待事件来看 DB CPU占了%DB time的91.81%,这个awr报告采样时间是两个小时,总的DB time是810分种服务器显示有24个逻辑CPU,每个CPU的耗时是33.75分钟,CPU的使用率也不是很高,那么我们来看一下后台等待事件。
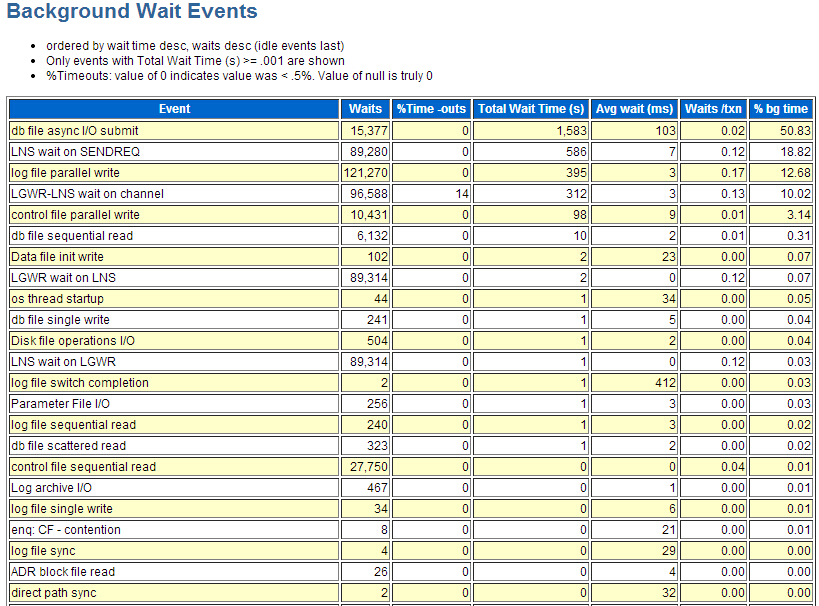
后台等待事件排在第一的是 db file async I/O submit,这是一个异步IO相关的等待事件,而LNS wait on SENDREQ,LGWR-LNS wait on channel是与DG相关的日志传输相关的等待事件。这里的操作系统是Linux,而根据Doc ID 1274737.1文档描述,当disk_asynch_io=true时,而filesystemio_options=none,那么正常的文件系统在Linux系统支持异步I/O的情况下Oracle也不能使用异常I/O。
我们先来检查一下Linux系统中是否执行过异步I/O操作
[oracle@ErpOracle01 ~]$ cat /proc/slabinfo | grep kio kioctx 376 640 384 10 1 : tunables 54 27 8 : slabdata 64 64 2 kiocb 0 0 256 15 1 : tunables 120 60 8 : slabdata 0 0 0
可以看到kiocb的前两列为0说明没有执行异步I/O操作,用于存储Oracle数据文件的就是正常的文件系统
[root@ErpOracle01 ~]# fdisk -l Disk /dev/sda: 598.9 GB, 598879502336 bytes 255 heads, 63 sectors/track, 72809 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x000a66fb Device Boot Start End Blocks Id System /dev/sda1 * 1 131 1048576 83 Linux Partition 1 does not end on cylinder boundary. /dev/sda2 131 8486 67108864 82 Linux swap / Solaris /dev/sda3 8486 72810 516684800 83 Linux
在这种情况下要让Oracle使用异步I/O将参数filesystemio_options设置为’asynch’。
SQL> show parameter disk_asynch_io NAME TYPE VALUE ------------------------------------ --------------------------------- ------------------------------ disk_asynch_io boolean TRUE SQL> show parameter filesystemio_options NAME TYPE VALUE ------------------------------------ --------------------------------- ------------------------------ filesystemio_options string none SQL> alter system set filesystemio_options='asynch' scope=spfile; System altered.
LNS wait on SENDREQ是DG的RFS I/O时间和网络时间的总计,而它可能是由网络带宽或备库的I/O性能引起的。而这经确认是备库的I/O性能引起的,再加上在这期间后台维护人员在主库做大批量的数据更新。在主库中出现了Log file sync和log file parallel write等待事件。LGWR-LNS wait on channel等待事件是日志写进程或网络服务器进程在KSR通道上等待接受消息所花的时间.LNS wait on SENDREQ, Log file sync, log file parallel write, LGWR-LNS wait on channel通过调整备库I/O性能和对主库增加online and standby redo logs来改善。然后在中午休息时间重启了数据库,经过三天的运行,业务没有出现办理不了的情况了。
朋友公司一个erp系统业务办理不了,但从前台等待事件来看 DB CPU占了%DB time的91.81%,这个awr报告采样时间是两个小时,总的DB time是810分种服务器显示有24个逻辑CPU,每个CPU的耗时是33.75分钟,CPU的使用率也不是很高,那么我们来看一下后台等待事件。
后台等待事件排在第一的是 db file async I/O submit,这是一个异步IO相关的等待事件,而LNS wait on SENDREQ,LGWR-LNS wait on channel是与DG相关的日志传输相关的等待事件。这里的操作系统是Linux,而根据Doc ID 1274737.1文档描述,当disk_asynch_io=true时,而filesystemio_options=none,那么正常的文件系统在Linux系统支持异步I/O的情况下Oracle也不能使用异常I/O。
我们先来检查一下Linux系统中是否执行过异步I/O操作
[oracle@ErpOracle01 ~]$ cat /proc/slabinfo | grep kio kioctx 376 640 384 10 1 : tunables 54 27 8 : slabdata 64 64 2 kiocb 0 0 256 15 1 : tunables 120 60 8 : slabdata 0 0 0
可以看到kiocb的前两列为0说明没有执行异步I/O操作,用于存储Oracle数据文件的就是正常的文件系统
[root@ErpOracle01 ~]# fdisk -l Disk /dev/sda: 598.9 GB, 598879502336 bytes 255 heads, 63 sectors/track, 72809 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x000a66fb Device Boot Start End Blocks Id System /dev/sda1 * 1 131 1048576 83 Linux Partition 1 does not end on cylinder boundary. /dev/sda2 131 8486 67108864 82 Linux swap / Solaris /dev/sda3 8486 72810 516684800 83 Linux
在这种情况下要让Oracle使用异步I/O将参数filesystemio_options设置为’asynch’。
SQL> show parameter disk_asynch_io NAME TYPE VALUE ------------------------------------ --------------------------------- ------------------------------ disk_asynch_io boolean TRUE SQL> show parameter filesystemio_options NAME TYPE VALUE ------------------------------------ --------------------------------- ------------------------------ filesystemio_options string none SQL> alter system set filesystemio_options='asynch' scope=spfile; System altered.
LNS wait on SENDREQ是DG的RFS I/O时间和网络时间的总计,而它可能是由网络带宽或备库的I/O性能引起的。而这经确认是备库的I/O性能引起的,再加上在这期间后台维护人员在主库做大批量的数据更新。在主库中出现了Log file sync和log file parallel write等待事件。LGWR-LNS wait on channel等待事件是日志写进程或网络服务器进程在KSR通道上等待接受消息所花的时间.LNS wait on SENDREQ, Log file sync, log file parallel write, LGWR-LNS wait on channel通过调整备库I/O性能和对主库增加online and standby redo logs来改善。然后在中午休息时间重启了数据库,经过三天的运行,业务没有出现办理不了的情况了。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/26015009/viewspace-1667515/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/26015009/viewspace-1667515/















 3085
3085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









