






mysql的分页比较简单,只需要limit offset,length就可以获取数据了,但是当offset和length比较大的时候,mysql明显性能下降
1.子查询优化法
先找出第一条数据,然后大于等于这条数据的id就是要获取的数据
缺点:数据必须是连续的,可以说不能有where条件,where条件会筛选数据,导致数据失去连续性,具体方法请看下面的查询实例:
复制代码 代码如下:
mysql> set profiling=1;
Query OK, 0 rows affected (0.00 sec)
mysql> select count(*) from Member;
+----------+
| count(*) |
+----------+
| 169566 |
+----------+
1 row in set (0.00 sec)
mysql> pager grep !~-
PAGER set to 'grep !~-'
mysql> select * from Member limit 10, 100;
100 rows in set (0.00 sec)
mysql> select * from Member where MemberID >= (select MemberID from Member limit 10,1) limit 100;
100 rows in set (0.00 sec)
mysql> select * from Member limit 1000, 100;
100 rows in set (0.01 sec)
mysql> select * from Member where MemberID >= (select MemberID from Member limit 1000,1) limit 100;
100 rows in set (0.00 sec)
mysql> select * from Member limit 100000, 100;
100 rows in set (0.10 sec)
mysql> select * from Member where MemberID >= (select MemberID from Member limit 100000,1) limit 100;
100 rows in set (0.02 sec)
mysql> nopager
PAGER set to stdout
mysql> show profiles\G
*************************** 1. row ***************************
Query_ID: 1
Duration: 0.00003300
Query: select count(*) from Member
*************************** 2. row ***************************
Query_ID: 2
Duration: 0.00167000
Query: select * from Member limit 10, 100
*************************** 3. row ***************************
Query_ID: 3
Duration: 0.00112400
Query: select * from Member where MemberID >= (select MemberID from Member limit 10,1) limit 100
*************************** 4. row ***************************
Query_ID: 4
Duration: 0.00263200
Query: select * from Member limit 1000, 100
*************************** 5. row ***************************
Query_ID: 5
Duration: 0.00134000
Query: select * from Member where MemberID >= (select MemberID from Member limit 1000,1) limit 100
*************************** 6. row ***************************
Query_ID: 6
Duration: 0.09956700
Query: select * from Member limit 100000, 100
*************************** 7. row ***************************
Query_ID: 7
Duration: 0.02447700
Query: select * from Member where MemberID >= (select MemberID from Member limit 100000,1) limit 100
从结果中可以得知,当偏移1000以上使用子查询法可以有效的提高性能。
2.倒排表优化法
倒排表法类似建立索引,用一张表来维护页数,然后通过高效的连接得到数据
缺点:只适合数据数固定的情况,数据不能删除,维护页表困难
倒排表介绍:(而倒排索引具称是搜索引擎的算法基石)
倒排表是指存放在内存中的能够追加倒排记录的倒排索引。倒排表是迷你的倒排索引。
临时倒排文件是指存放在磁盘中,以文件的形式存储的不能够追加倒排记录的倒排索引。临时倒排文件是中等规模的倒排索引。
最终倒排文件是指由存放在磁盘中,以文件的形式存储的临时倒排文件归并得到的倒排索引。最终倒排文件是较大规模的倒排索引。
倒排索引作为抽象概念,而倒排表、临时倒排文件、最终倒排文件是倒排索引的三种不同的表现形式。
3.反向查找优化法
当偏移超过一半记录数的时候,先用排序,这样偏移就反转了
缺点:order by优化比较麻烦,要增加索引,索引影响数据的修改效率,并且要知道总记录数 ,偏移大于数据的一半
limit偏移算法:
正向查找: (当前页 - 1) * 页长度
反向查找: 总记录 - 当前页 * 页长度
做下实验,看看性能如何
总记录数:1,628,775
每页记录数: 40
总页数:1,628,775 / 40 = 40720
中间页数:40720 / 2 = 20360
第21000页
正向查找SQL:
复制代码 代码如下:
SELECT * FROM `abc` WHERE `BatchID` = 123 LIMIT 839960, 40
时间:1.8696 秒
反向查找sql:
复制代码 代码如下:
SELECT * FROM `abc` WHERE `BatchID` = 123 ORDER BY InputDate DESC LIMIT 788775, 40
时间:1.8336 秒
第30000页
正向查找SQL:
复制代码 代码如下:
SELECT * FROM `abc` WHERE `BatchID` = 123 LIMIT 1199960, 40
时间:2.6493 秒
反向查找sql:
复制代码 代码如下:
SELECT * FROM `abc` WHERE `BatchID` = 123 ORDER BY InputDate DESC LIMIT 428775, 40
时间:1.0035 秒
注意,反向查找的结果是是降序desc的,并且InputDate是记录的插入时间,也可以用主键联合索引,但是不方便。
4.只查索引法
MySQL的limit工作原理就是先读取n条记录,然后抛弃前n条,读m条想要的,所以n越大,性能会越差。
优化前SQL:
复制代码 代码如下:
SELECT * FROM member ORDER BY last_active LIMIT 50,5
优化后SQL:
复制代码 代码如下:
SELECT * FROM member INNER JOIN (SELECT member_id FROM member ORDER BY last_active LIMIT 50, 5) USING (member_id)
区别在于,优化前的SQL需要更多I/O浪费,因为先读索引,再读数据,然后抛弃无需的行。而优化后的SQL(子查询那条)只读索引(Cover index)就可以了,然后通过member_id读取需要的列。
总结:limit的优化限制都比较多,所以实际情况用或者不用只能具体情况具体分析了。页数那么后,基本很少人看的。。。
MySQL中的limit分页优化
MySQL的limit优化
在mysql中limit可以实现快速分页,但是如果数据到了几百万时我们的limit必须优化才能有效的合理的实现分页了,否则可能卡死你的服务器哦。
当一个表数据有几百万的数据的时候成了问题!
如 * from table limit 0,10 这个没有问题 当 limit 200000,10 的时候数据读取就很慢,可以按照一下方法解决
第一页会很快
PERCONA PERFORMANCE CONFERENCE 2009上,来自雅虎的几位工程师带来了一篇”EfficientPagination Using MySQL”的报告
limit10000,20的意思扫描满足条件的10020行,扔掉前面的10000行,返回最后的20行,问题就在这里。
LIMIT 451350 , 30 扫描了45万多行,怪不得慢的都堵死了。
但是
limit 30 这样的语句仅仅扫描30行。
那么如果我们之前记录了最大ID,就可以在这里做文章
举个例子
日常分页SQL语句
select id,name,content from users order by id asc limit 100000,20
扫描100020行
如果记录了上次的最大ID
select id,name,content from users where id>100073 order by id asc limit 20
扫描20行。
总数据有500万左右
以下例子 当时候 select * from wl_tagindex where byname='f' order by id limit 300000,10 执行时间是 3.21s
优化后:
点击(此处)折叠或打开
- select * from (
- select id from wl_tagindex
- where byname='f' order by id limit 300000,10
- ) a
- left join wl_tagindex b on a.id=b.id
执行时间为 0.11s 速度明显提升
这里需要说明的是 我这里用到的字段是 byname ,id 需要把这两个字段做复合索引,否则的话效果提升不明显
总结
当一个数据库表过于庞大,LIMIT offset, length中的offset值过大,则SQL查询语句会非常缓慢,你需增加order by,并且order by字段需要建立索引。
如果使用子查询去优化LIMIT的话,则子查询必须是连续的,某种意义来讲,子查询不应该有where条件,where会过滤数据,使数据失去连续性。
如果你查询的记录比较大,并且数据传输量比较大,比如包含了text类型的field,则可以通过建立子查询。
SELECT id,title,content FROM items WHERE id IN (SELECT id FROM items ORDER BY id limit 900000, 10);
如果limit语句的offset较大,你可以通过传递pk键值来减小offset = 0,这个主键最好是int类型并且auto_increment
SELECT * FROM users WHERE uid > 456891 ORDER BY uid LIMIT 0, 10;
这条语句,大意如下:
SELECT * FROM users WHERE uid >= (SELECT uid FROM users ORDER BY uid limit 895682, 1) limit 0, 10;
如果limit的offset值过大,用户也会翻页疲劳,你可以设置一个offset最大的,超过了可以另行处理,一般连续翻页过大,用户体验很差,则应该提供更优的用户体验给用户。
原文地址:SQL优化:limit分页优化 作者:wyett
分页查询
分页查询的问题点主要集中在
- 如何快速定位起始点
- 减少无用数据缓存
mysql为分页查询提供了很方便的关键字limit,但这个关键字在数据量较大时,却很低效。
“limit m,n”关键字的意思是,从第m行开始,扫描满足条件的n个偏移行。若需从第1行开始,则不需要指定m值。
示例
表aaaaa中共有2375690数据。
优化前的SQLSQL执行结果:
SELECT DISTINCT(device_id) uid FROM aaaaa WHERE status = 0 LIMIT 88000,1000; 1000 rows in set (0.48 sec)
SQL执行计划:
MariaDB [star]> explain SELECT sql_no_cache DISTINCT(device_id) uid FROM aaaaa WHERE status = 0 LIMIT 88000,1000; +------+-------------+---------------+------+---------------+------+---------+------+---------+------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+---------------+------+---------------+------+---------+------+---------+------------------------------+ | 1 | SIMPLE | aaaaa | ALL | NULL | NULL | NULL | NULL | 2375690 | Using where; Using temporary | +------+-------------+---------------+------+---------------+------+---------+------+---------+------------------------------+优化方式
迅速定位起始ID,利用主键索引,加快扫描速度。可以看到,derived中,SQL使用到了覆盖索引进行扫描,虽然还是全表扫,因为只扫描id列,大大降低了扫描的IO耗费,快速定位到了id。
MariaDB [star]> explain SELECT sql_no_cache DISTINCT(device_id) uid FROM aaaaa join (select id from aaaaa limit 88000,1) k on star_device_5.id>=k.id
where status=0 limit 1000; +------+-------------+---------------+-------+---------------+-------------+---------+------+---------+------------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+---------------+-------+---------------+-------------+---------+------+---------+------------------------------------------------+ | 1 | PRIMARY | | ALL | NULL | NULL | NULL | NULL | 88001 | Using temporary | | 1 | PRIMARY | star_device_5 | ALL | PRIMARY | NULL | NULL | NULL | 2377112 | Range checked for each record (index map: 0x1) | | 2 | DERIVED | star_device_5 | index | NULL | idx_star_id | 8 | NULL | 2377112 | Using index | +------+-------------+---------------+-------+---------------+-------------+---------+------+---------+------------------------------------------------+
执行结果:
SELECT sql_no_cache DISTINCT(device_id) uid FROM star_device_5 join (select id from star_device_5 limit 880000,1) k on star_device_5.id>=k.id
where status=0 limit 1000; 1000 rows in set (0.19 sec)
随着m的增大和n的增大,两种写法的SQL执行时间会有本质差别。我做了测试,当m值增加到880000时,优化前的SQL需要2分钟,优化后的SQL还是0.1s左右。
MySQL5.6中Limit的工作机制
如果你仅需要在一个结果集中返回特定的几行,通常是使用limit,而不是取回整个结果集再舍去不需要的数据,MySQL通常按照如下的方式优化一个包含limit row_count或HAVING的语句:
◎只有limit
如果你只通过limit返回少量的行,那么正常情况下mysql会使用全盘扫描,有些场合会使用索引,以下是使用了覆盖索引的情况:

以下是使用全表扫描的情况:

◎order by和limit
如果你order by和limit一起使用,那么mysql在排序结果中找到最初的row_count行之后就会完成这条语句,而不是对整个结果集进行排序。如果使用了索引排序,它就非常快地完成。如果整个filesort必须都做完的话,那么在找到最初的row_count行之前,匹配该查询的所有行都将被select,并且做sort操作。如果这些行找到了,mysql将不会对剩余的结果集进行排序。
◎distinct和limit
当limit row_count和distinct一起使用时,MySQL在找到最初的unique的row_count行之后就会停止检索。
◎group by和limit
在某些场合下,group by会用于某些key行的排序,并且计算汇总信息,这时如果使用limit row_count的话将不会计算任何额外的grup by值。
◎SQL_CALC_FOUND_ROWS和limit
只要MySQL已经返回了需要的行数给客户端,它将终止这个查询,除非你在查询中使用了SQL_CALC_FOUND_ROWS。
◎limit 0的用法
Limit 0会非常快地返回一个空结果,这个功能可被应用于检测一条SQL的合法性。
◎临时表和limit
如果服务器在查询中使用了临时表,它会使用limit row_count语句来计算需求的空间大小。
Order by和Limit混合使用引起的问题
如果在order by语句中返回的结果集有很多行,那么非排序的列的返回结果是不确定的,即随机的,所以如果配合limit的话每次返回的结果集的顺序是不固定的,比如下面这个例子
mysql> SELECT * FROM ratings ORDER BY category;
+----+----------+--------+
| id | category | rating |
+----+----------+--------+
| 1 | 1 | 4.5 |
| 5 | 1 | 3.2 |
| 3 | 2 | 3.7 |
| 4 | 2 | 3.5 |
| 6 | 2 | 3.5 |
| 2 | 3 | 5.0 |
| 7 | 3 | 2.7 |
+----+----------+--------+
使用了limit以后,可发现id列和rating列和之前的结果集顺序有出入:
mysql> SELECT * FROM ratings ORDER BY category LIMIT 5;
+----+----------+--------+
| id | category | rating |
+----+----------+--------+
| 1 | 1 | 4.5 |
| 5 | 1 | 3.2 |
| 4 | 2 | 3.5 |
| 3 | 2 | 3.7 |
| 6 | 2 | 3.5 |
+----+----------+--------+
如果你有必要保证每次有相同的结果集,则需要order by你需要的那几列了:
mysql> SELECT * FROM ratings ORDER BY category, id;
+----+----------+--------+
| id | category | rating |
+----+----------+--------+
| 1 | 1 | 4.5 |
| 5 | 1 | 3.2 |
| 3 | 2 | 3.7 |
| 4 | 2 | 3.5 |
| 6 | 2 | 3.5 |
| 2 | 3 | 5.0 |
| 7 | 3 | 2.7 |
+----+----------+--------+
mysql> SELECT * FROM ratings ORDER BY category, id LIMIT 5;
+----+----------+--------+
| id | category | rating |
+----+----------+--------+
| 1 | 1 | 4.5 |
| 5 | 1 | 3.2 |
| 3 | 2 | 3.7 |
| 4 | 2 | 3.5 |
| 6 | 2 | 3.5 |
+----+----------+--------+
Order by和limit一起使用的优化原理
从MySQL5.6.2版本以后,优化器将更加智能地处理下面形式的查询了
SELECT ... FROM single_table ... ORDER BY non_index_column [DESC] LIMIT [M,]N;
这种在很大的结果集中只返回很少的行数的查询类型在web应用中非常常见,比如
SELECT col1, ... FROM t1 ... ORDER BY name LIMIT 10;
SELECT col1, ... FROM t1 ... ORDER BY RAND() LIMIT 15;
排序缓存有一个参数是sort_buffer_size,如果这个参数大小足够上面范例中的N行的排序结果集(如果M也被定义,那就是M+N行的结果集大小),那么服务器将会避免一个文件排序操作,使得排序完全在内存中完成。
内存排序+limit原理
1 扫描表,在内存中插入那些被选择排序的列的数据到一个排好序的队列中,比如order by col1,col2,则插入col1和col2列的数据。如果队列满了,则挤出排序在末尾的数据。
2 返回队列中的前N行记录,如果M也被定义,则调到第M行开始返回后续的N行记录。
文件排序+limit原理
1扫描表,重复步骤2和3,直到表的结尾
2选中这些行数直到排序缓存被填满
3在排序缓存中写入第一个N行(如果M被定义,则M+N行)到一个排序文件中。
两者比较
在内存中排序和使用文件排序相比,扫描表的代价几乎是一样的,不同的是其他的开销:
内存排序的方法在插入数据到一个有序队列中会牵扯到更多的cpu资源,而文件排序会消耗更多的磁盘IO,优化器在考虑两者的平衡性上会主要考虑N的值大小
LIMIT是什么?
LIMIT的概念,其实大家应该都很清楚,在百度百科中是这样描述的:
LIMIT是一种数据语言,主要是用于查询之后要显示返回的前几条或者中间某几行数据。
这里着重需要注意的是,offset为开始角标,count代表数量,如下图所示: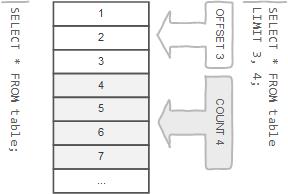
(网络配图)
理解了这个概念之后,我们就能够知道下面这两个语句的意思了:
LIMIT 0,100; (A)
LIMIT 10,100; (B)
语句A代表的是 : 从起始角标为0的位置,往后获取100条记录。
语句B代表的是 : 从起始角标为10的位置,往后获取100条记录。
(别以为这很简单,在之前的面试过程中,就有很多童鞋搞混了,将语句B理解成了: 从起始角标为10的位置,获取90条数据呢。)
其实,LIMIT还有一个比较常用的简化写法,如下所示:
LIMIT 100;
这其实就是对上述A语句的简化,其意思代表的是: 从其实角标为0的位置,往后获取100条记录。只是将其实角标0省略掉了而已。真是这样的特性,有很多应用也直接使用LIMIT来进行分页操作。
提问时间
上面我们介绍了,LIMIT的概念,也理清楚了LIMIT每个参数的含义,那现在就留一个问题:
- 问: LIMIT 0,100与 LIMIT 100000,100的执行效率是一样吗? 一样为什么?不一样又为什么?
ps: 面试时经常有这样的问题哦。这个之前我也被问到过。
执行LIMIT发生了什么?
我们知道,一般是在order by xx asc|desc语句后紧跟着LIMIT语句,下面我们就来看看下面这两个语句,揭露一下:
语句A:
select * from t_base_user order by oid desc limit 0,100;
语句B:
select * from t_base_user order by oid desc limit 10000,100;
分别看下执行计划:
语句A的执行计划是:
explain select * from t_base_user order by oid desc limit 0,100;
结果:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | t_base_user | index | null | PRIMARY | 8 | null | 100 | null |
语句B的执行计划是:
explain select * from t_base_user order by oid desc limit 10000,100;
结果:
id|select_type|table|type|possible_keys|key|key_len|ref|rows|Extra
—|—|—|—|—|—|—|—|–|–|
1 | SIMPLE|t_base_user|index|null|PRIMARY|8|null|1000100|null
到这里,我们会发现扫描的行数是完全不一样的,在语句B中,其实MySQL实际扫描1000100行记录,然后只返回100条记录,将前面的1000000条记录活生生的抛弃掉,你说这成本大不大,代价高不高? 看到这里,我们应该已经知道上面问题的答案了。
如何优化
现在我们来说说如何优化LIMIT,我们知道,在offset比较大的时候,效率会非常低,所以,对LIMIT优化,要么限制分页的数量,要么降低offset的大小。
例如:
select * from t_base_user limit 100000,100
比如上面这语句,因为我们主键是连续的。
方法一 : 我们就可以通过这样来优化:
select * from t_base_user where oid between 100000 and 1000100;
此时如果我们看执行计划的话,其实type已经从all(全表扫描)扫描优化到range(范围查找),也走了PRIMARY索引。
方法二: 我们可以倒序LIMIT
如果我们表中一共有120万数据,此时我们就可以倒序LIMIT,如下所述:
select * from t_base_user order by oid desc limit 100;
或者这样:
select * from t_base_user where oid<1000000 order by oid desc limit 100;
同样也达到来优化的效果。
数据结构
本文所有数据,均基于以下数据结构:
create table t_base_user(
oid bigint(20) not null primary key auto_increment,
name varchar(30) null comment “name”,
email varchar(30) null comment “email”,
age int null comment “age”,
telephone varchar(30) null comment “telephone”,
status tinyint(4) null comment “0 无效 1 有效”,
created_at datetime null default now() comment “创建时间”,
updated_at datetime null default now() comment “修改时间”
)
// 新增记录:
insert into t_base_user(name,email,age,telephone,status,created_at,updated_at) values (“andyqian”,”andytohome”,20,”15608411”,1,now(),now());
这里提供一个简单的方法复制数据
insert into t_base_user(name,email,age,telephone,status) select name,email,age,telephone,status from t_base_user;
使用该语句,可以快速的复制数据。执行多次后,就能够生成不少数据,(备注: 该数据仅用作LIMIT关键字演示,新建索引,计算区分度其值偏差会比较大,请勿将该结果作为建索引的参考值。)
小结
上面对MySQL LIMIT关键字做了详细的讲解,你可别小瞧它哦,它在平时开发中有很大的用处哦,例如: 在平时开发查询数据时,加上LIMIT后,查询效果可会大大增加,能节省不少时间呢。在查询数据时养成加上LIMIT是一个不错的习惯。
About Me
.............................................................................................................................................
● 本文作者:小麦苗,部分内容整理自网络,若有侵权请联系小麦苗删除
● 本文在itpub(http://blog.itpub.net/26736162/abstract/1/)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版、个人简介及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● DBA宝典今日头条号地址:http://www.toutiao.com/c/user/6401772890/#mid=1564638659405826
.............................................................................................................................................
● QQ群号:230161599(满)、618766405
● 微信群:可加我微信,我拉大家进群,非诚勿扰
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-12-01 09:00 ~ 2017-12-31 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
.............................................................................................................................................
● 小麦苗的微店:https://weidian.com/s/793741433?wfr=c&ifr=shopdetail
● 小麦苗出版的数据库类丛书:http://blog.itpub.net/26736162/viewspace-2142121/
.............................................................................................................................................
使用微信客户端扫描下面的二维码来关注小麦苗的微信公众号(xiaomaimiaolhr)及QQ群(DBA宝典),学习最实用的数据库技术。
小麦苗的微信公众号 小麦苗的DBA宝典QQ群2 《DBA笔试面宝典》读者群 小麦苗的微店
.............................................................................................................................................








来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/26736162/viewspace-2148816/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/26736162/viewspace-2148816/















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









