








接着续,每天5分钟:Learning Spark - LIGHTNING-FAST DATA ANALYSIS 第四章 - (2)
数据分区(高级)
本章讨论的最后一个Spark的特性是如何控制数据跨节点分区。分布式程序中,通信十分昂贵,所以对数据布局来最小化网络传输可以大幅提高性能。跟单机程序为数据集合选择一个正确的数据结构很类似,Spark程序可以选择控制分区来减少网络通信。分区不是对所有的应用都有好处,比如,对给定的RDD仅扫描一次,那么预先分区就没有意义。仅当数据集需要多次重用来面向主键比如连接这样的操作时才会有用。随后我们会给出示例。
Spark的分区对所有的键值对RDD都可用,使系统基于函数对每个主键进行数据分组。尽管Spark没有显式的控制每个主键的数据到哪个worker节点(部分是因为系统被设计为即使某个节点出错也能工作),但是也会让程序确保同一个主键的数据集中出现在某些节点上。比如你可以选择用哈希分区将RDD分成100个分区,主键模100有相同结果的数据在同一个节点上。或者按范围分区,使得主键在同一个范围的元素在同一个节点上。
一个简单例子,假设程序在内存中持有一个非常大的用户信息表,或者说一个(UserID,UserInfo)键值对RDD。其中UserInfo包含用户订阅的主题列表。应用程序周期性的将该表和另一个小文件合并。这个小文件以(UserID, LinkInfo)键值对的形式记录过去5分钟里在网页上点击过链接的事件表。比如我们现在想计算有多少用户访问了不是他们订阅的主题的链接。这可以通过Spark的join()操作来完成这个合并,按照主键将UserInfo和LinkInfo配对。程序看起来如示例4-22。
示例4-22. Scala的一个简单应用
// Initialization code; we load the user info from a Hadoop SequenceFile on HDFS.
// This distributes elements of userData by the HDFS block where they are found,
// and doesn't provide Spark with any way of knowing in which partition a
// particular UserID is located.
val sc = new SparkContext(...)
val userData = sc.sequenceFile[UserID, UserInfo]("hdfs://...").persist()
// Function called periodically to process a logfile of events in the past 5 minutes;
// we assume that this is a SequenceFile containing (UserID, LinkInfo) pairs.
def processNewLogs(logFileName: String) {
val events = sc.sequenceFile[UserID, LinkInfo](logFileName)
val joined = userData.join(events)// RDD of (UserID, (UserInfo, LinkInfo)) pairs
val offTopicVisits = joined.filter {
case (userId, (userInfo, linkInfo)) => // Expand the tuple into its components
!userInfo.topics.contains(linkInfo.topic)
}.count()
println("Number of visits to non-subscribed topics: " + offTopicVisits)
}
代码可以执行,但是有些低效。这是因为每次processNewLogs()被调用时都会调用的join()操作不知道数据集中的主键是如何分区的。默认情况下,join()操作会对两个RDD的主键都做哈希,通过网络发送相同主键的元素到同一个机器上,然后在这个机器上按主键进行连接(见图4-4)。因为我们能预料到userData表远远大于每五分钟一个的较小的事件日志,太浪费了:即使根本没有变化,也要每次都把userData表跨网络的哈希和shuffle一遍。
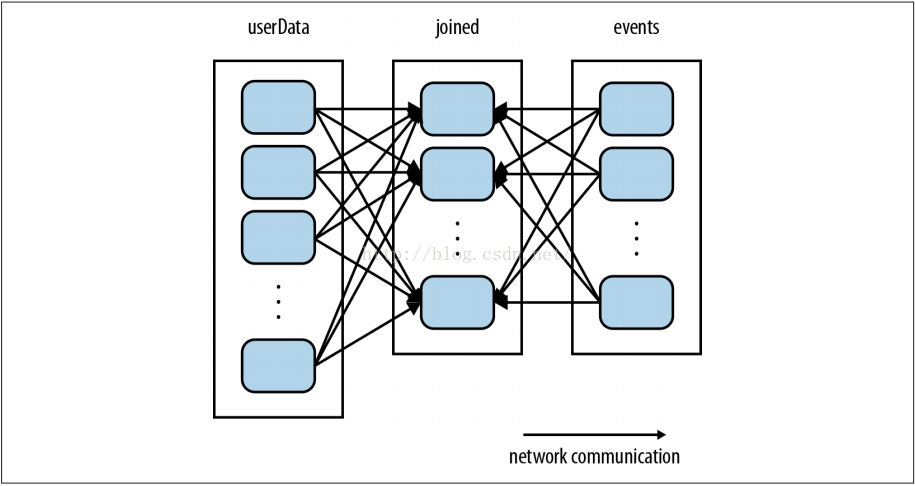
图 4-4 未使用partitionBy()的userData和events的每一次join
修改很简单:在程序启动时的对userData使用partitionBy()变换进行哈希分区。将spark.HashPartitionner对象传入partitionBy()函数,见示例4-23。
示例4-23. Scala中使用自定义分区
val sc = new SparkContext(...)
val userData = sc.sequenceFile[UserID, UserInfo]("hdfs://...")
.partitionBy(new HashPartitioner(100)) // Create 100 partitions
.persist()
processNewLogs()方法保持不变:对于processNewLogs()来说events RDD是本地的,并且只在这个方法里用到,所以对event RDD指定分区不会有改善。因为在构建userData时我们调用了partitionBy()函数,这样Spark就知道它是哈希分区的,在执行join()时会利用这个信息。特别是在调用userData.join(events)的时候,Spark仅会对events RDD进行shuffle,并根据UserID将events发送到userData的哈希分区对应的机器上(见图4-5)。结果就是网络上传输的数据大量减少,程序运行的明显快了。
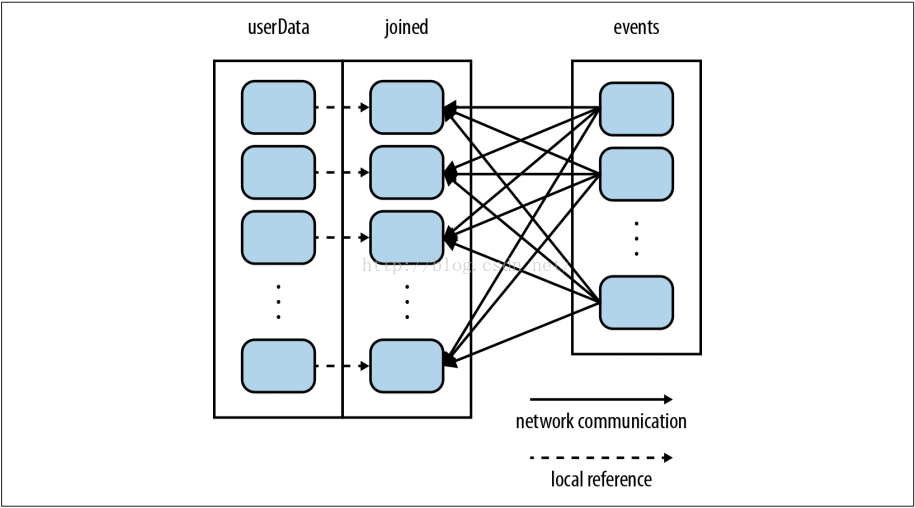
图 4-5 使用了partitionBy()的userData和events的每一次join
注意,partitionBy()是个变换,它总是返回一个新的RDD,不会改变原始的RDD。RDD一旦创建就不会被修改。因此,重要的是持久化和保存userData这个partitionBy()的结果,而不是原始的sequenceFile()。传递给partitionBy()的100是表达的分区的个数,它控制对RDD执行更多操作(比如join)的并发任务数。一般来说,至少让它和集群的核数一样大。

事实上,Spark的很多其他操作自动地导致RDD中带有已知的分区信息,除了join()之外的很多操作都会利用这些信息。例如sortByKey()和groupByKey()分别会产生范围分区和哈希分区的RDD。另一方面,像map()这样的操作会导致新RDD忘记父RDD的分区信息,因为这些操作理论上能修改每个记录的主键。下一节讲述如何确定RDD是已分区的,以及分区如何精确的影响各种Spark操作。

Spark的Java和Python API跟Scala API一样会从分区中获益。然而在Python中不能传入HashPartition对象来分区,你只能指定分区的数目(比如rdd.partitionBy(100))。
确定RDD的分区
在Scala和Java中可以通过分区属性(或者Java中用partitioner()方法)来确定RDD是如何分区的2。它会返回一个scala.Option对象,这是个Scala的容器类,可能包含或者没包含一个对象。你可以对Option对象调用isDefined()来检查是否有值,并用get()函数得到该值。如果有的话,这个值将是一个spark.Partitioner对象。本质上,这是个函数,告诉RDD每个主键都到了哪个分区里。后面会更详细说这个。
在Spark Shell中,分区属性是测试Spark操作对分区影响有多么不同的很好的方式,以及检查你程序中要做的操作会否得到正确的结果(见示例4-24)。
2 Python API没有提供方法来查询分区,尽管在内部仍然使用分区。
示例4-24. 确定RDD的partitioner
scala> val pairs = sc.parallelize(List((1, 1), (2, 2), (3, 3)))
pairs: spark.RDD[(Int, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:12
scala> pairs.partitioner
res0: Option[spark.Partitioner] = None
scala> val partitioned = pairs.partitionBy(new spark.HashPartitioner(2))
partitioned: spark.RDD[(Int, Int)] = ShuffledRDD[1] at partitionBy at <console>:14
scala> partitioned.partitioner
res1: Option[spark.Partitioner] = Some(spark.HashPartitioner@5147788d)
在这个短会话中,我们创建了一个(Int, Int)类型的pair RDD,最初是没有分区信息的(Option的值是None)。然后对第一个RDD进行哈希分区创建了第二个RDD。实际上如果我们要在以后的操作中用到这个分区后的RDD,应该在输入的第三行的结尾增加persist()持久化一下,这时分区就定义好了。原因和之前的userData要持久化的例子相同:没有持久化,后续的RDD动作会对整个分区的RDD的血统重新求值,这会导致不断地哈希分区动作。














 6243
6243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









