




下载包到本地安装
1. 包地址 https://www.lfd.uci.edu/~gohlke/pythonlibs/
2. 找到对应包, 下载到本地
3. cmd 进入包所在文件夹, pip3 install xxx 完成安装
2-4 pycharm的安装和配置
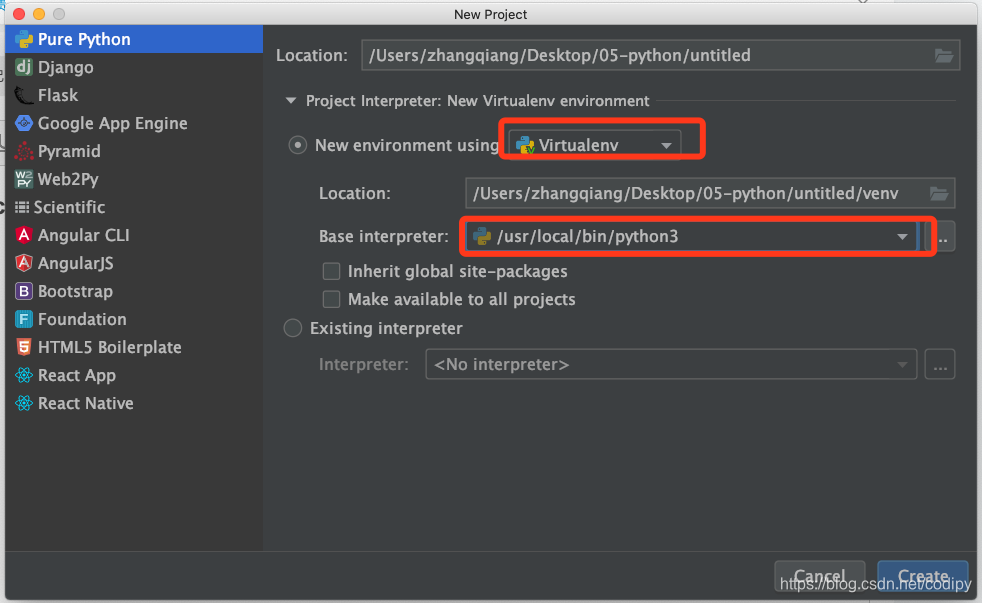
安装虚拟环境。这种是把虚拟环境装在目录下。
2-5 pycharm快捷键 (Eclipse Mac OS x)
| ctrl + 左键点击 | 查看引用 |
| Command + otption+ 右箭头 | 返回查看引用 |
| option + 向上箭头,向下箭头 | 整行代码的上下移动 |
| command + d | 删除整行代码 |
| ctrl + h | 全局搜索 |
| command + k | 文件内搜索 |
| tab | 退4格 |
| shift + tab | 回退(向前4格) |
| command + 左键 | 定位到行首 |
| command + 右键 | 定位到行尾 |
| ctrl + o | 显示大岗 |
| command + shift + r | 快速搜索 |
| command + shift + f | 格式化代码 |
2-9 虚拟环境 virtualenv的安装
mac下配置
1. 安装 virtualenv pip install virtualenv
2. 安装虚拟环境管理器 pip install virtualenvwrapper
3. 完成后,vim ~/.bash_profile
4. 在里面输入
export WORKON_HOME='~/.envs'
export VIRTUALENVWRAPPER_PYTHON='/usr/local/bin/python3'
source /usr/local/bin/virtualenvwrapper.sh
5. WORKON_HOME 是虚拟环境所存在的目录,用点开头,mkdir .envs自己先建立好,这里必须以 .开头
6. VIRTUALENVWRAPPER_PYTHON 是默认的python3,可以用 sudo find / -name python3 来查找python3的路径
7. 可以用 sudo find / -name virtualenvwrapper.sh 来查询 位置 5,6,7是第四步的解释
8. 这3行写好之后,wq保存退出。
9. 运行 source ~/.bash_profile 先运行才可以操作.
10. 创建一个虚拟环境 mkvirtualenv -p /usr/local/bin/python3 env1 (mkvirtualenv env1) 上面设置了默认为 python3,但是测试的时候不行。
11. 介绍
1. 列出虚拟环境:lsvirtualenv -b
2. 切换虚拟环境:workon env1
3. 退出虚拟环境:deactivate
4. 删除虚拟环境:rmvirtualenv test2
6-2 request介绍
参考: Python - requests库 学习笔记(持续更新) - 知乎
- get方式
- post方式
import json
import requests
## 1、get 请求
res = requests.get('http://www.baidu.com')
# 编码
print(res.encoding)
# 文本
print(res.text)
## 2、post 请求
payload = dict(key1='value1', key2='value2')
res = requests.post('http://192.168.0.77:20021/admin/order/refund/index', data=payload)
# 编码
print(res.encoding)
# json 结果
print(res.json())
# 状态码
print(res.status_code)
## 3、设置 header 头
my_headers = {
'user-agent': 'requests',
'imooc_uid': '321',
'authorization': '53270679ec4193939e04ca4d13e3dac3'
}
res = requests.post('http://192.168.0.77:20021/admin/order/refund/index', headers=my_headers, data=payload)
# json 结果
print(res.json())
# 打印 response的headers
print(res.headers)
## 4、参数 json 化 , 这样服务器端接受到的是 json 数据
res = requests.post('http://192.168.0.77:20021/admin/order/refund/index', headers=my_headers, data=json.dumps(payload))
6-3 正则表达式
| . | 匹配任意字符(不包含换行符) |
| ^ | 匹配开始位置,多行模式下匹配每一行的开始 |
| $ | 匹配结束位置,多行模式下匹配每一行的结束 |
| * | 匹配前一个元字符 0到多次 |
| + | 匹配前一个元字符 1到多次 |
| ? | 匹配前一个元字符 0到1次 |
| {m,n} | 匹配前一个元字符 m到n次 |
| \\ | 转移字符 |
| [] | 字符集,一个字符的集合,可匹配其中任意一个字符 |
| | | 逻辑表达式 或,比如 a|b 代表可匹配 a 或者 b |
| \b | 匹配位于单词开始或结束位置的空字符串 |
| \B | 匹配不位于单词开始或结束位置的空字符串 |
| \d | 匹配一个数字,相当于 [0-9] |
| \D | 匹配非数字,相当于 [^0-9] |
| \s | 匹配任意空白字符,相当于 [ \t\n\r\f\v] |
| \S | 匹配非空白字符,相当于 [^ \t\n\r\f\v] |
| \w | 匹配数字、字母、下划线中任意一个字符,相当于 [a-zA-Z0-9] |
| \W | 匹配非数字、字母、下划线中的任意字符,相当于[^a-zA-Z0-9] |
1.查找 findall 找到所有数据
import re
info = "姓名:bobby 生日:1987年10月11日 本科:2005年9月1日"
# 查找
print(re.findall('\d{4}', info))2. re.match() re.search() 查找 re.compile() 匹配
re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
re.match() 是从最开始的时候匹配的
re.search() 是全文匹配,不用在前面加 .*
import re
info = "姓名:bobby1987 生日:1987年10月11日 本科:2005年9月1日"
# 查找
# print(re.findall('\d{4}', info))
print(re.match(".*生日.*\d{4}", info))
print(re.search("生日.*\d{4}", info))
# match方法是从字符串最开始匹配的
# search 方式不是从最开始的地方匹配,所以不用在最前面加 .*结果用 group() 来获取
match_result = re.match(".*生日.*?(\d{4})", info)
print(match_result.group())
print(match_result.group(0))
print(match_result.group(1)) 3. re.sub() 替换字符串
info = "姓名:bobby1987 生日:1987年10月11日 本科:2005年9月1日"
# 替换
sub_result = re.sub('\d{4}', '2019', info)
print(sub_result) #姓名:bobby2019 生日:2019年10月11日 本科:2019年9月1日
4. 匹配模式
re.IGNORECASE 忽略大小写
re.DOTALL 不会因为换行符而停止匹配,有换行也会一直匹配
# 匹配模式
name = "my name is Bobby"
print(re.search("bobby", name, re.IGNORECASE).group())6-5 beautifulsoup 用法
安装 pip install beautifulsoup4
查询元素几种方式
from bs4 import BeautifulSoup
bs = BeautifulSoup(html, "html.parser")- bs.title.string 获取title标签下的字符串
- bs.find() 找到满足条件的第一个结果
- bs.find_all() 找到所有满足条件的结果
find() 5种用法
div_tag = bs.find('div')
div_tag = bs.find(id="info")
div_tag = bs.find('div', id="info")
div_tag = bs.find('div', id=re.compile("post-\d+")) 通过正则
div_tag = bs.find(string="hello") 通过内容定位元素
div_tag = bs.find(string=re.compile("post-\d+")) 通过内容正则定位元素查找子元素
div_tag = bs.find(id="info")
childrens = div_tag.contents 获取一级子元素
for child in childrens:
if child.name:
print(child.name)
------------------------------
div_tag = bs.find(id="info")
childrens = div_tag.descendants 获取所有子元素
for child in childrens:
if child.name:
print(child.name)获取父元素
div_tag = bs.find(id="info")
parent = bs.find("p", {"class", "name"}).parent 查找直接父元素
--------------------------------------------------
div_tag = bs.find(id="info")
parents = bs.find("p", {"class", "name"}).parents 查找所有父元素
for parent in parents:
print parent.name获取兄弟节点
div_tag = bs.find(id="info")
next_siblings = bs.find("p", {"class", "name"}).next_siblings 获取之后的兄弟节点
for sibling in next_siblings:
print(sibling.name)
---------
div_tag = bs.find(id="info")
prev_siblings = bs.find("p", {"class", "name"}).prev_siblings 获取之前的兄弟节点
for sibling in prev_siblings:
print(sibling.name)获取div的属性
name_tag = bs.find("p", ['class', 'name'])
print(name_tag['class']) 第一种方法
print(name_tag.get('class')) 第二种方法,比较好,没有则为空,不会报错,
上面返回的是一个 list
如果是一个自定义属性,返回的是一个 字符串,例如 <div xxx data-test="abc eft"></div>
name_tag = bs.find("p", ['class', 'name'])
print(name_tag['data-test']) 返回字符串 abc eft
6-7 xpath基本语法
插件下载:https://www.lfd.uci.edu/~gohlke/pythonlibs/
1.安装 pip install lxml
2. 安装 pip install twisted
3. 按照 pip install scrapy
ps: mac上安装出现 无法安装的情况,有2种方法解决
1. xcode-select --install 先安装这个
2. 原生下载太慢了,用 豆瓣的镜像
pip install -i https://pypi.douban.com/simple twisted
pip install -i https://pypi.douban.com/simple scrapy
1. xpath 简介
1.1 xpath使用路径表达式在xml和html中进行导航
1.2 xpath包含标准函数库
1.3 xpath是一个w3c的标准
2. xpath节点关系
2.1 父节点
2.2 子节点
2.3 同胞节点
2.4 先辈节点
2.5 后代节点
3. xpath语法
//* 表示所有代码
[@id='info'] 表示id=info的节点
/div 表示 id=info下面的div节点
/p[1] 表示 id=info 下面的div节点 下面的 第一个p节点
/text() 表示获取里面的 文字,输出为 str
.extract() 把结果转为 list类型
[0] 表示取list的第一个值
| 表达式 | 说明 |
| article | 选取所有 article 元素的所有子节点 |
| /article | 选取根元素 article |
| article/a | 选取所有属于article的子元素的a元素 |
| //div | 选取所有div子元素(不论出现在文档任何地方) |
| article//div | 选取所有属于 article 元素的后代的 div 元素,不管它出现在 article 之下的任何位置 |
| //@class | 选取所有名为 class 的属性 |
| /article/div[1] | 选取属于 article 子元素的第一个div元素 |
| /article/div[last()] | 选取属于article子元素的最后一个div元素 |
| /article/div[last()-1] | 选取属于article子元素的倒数第二个div元素 |
| //div[@lang] | 选取所有拥有lang属性的div元素 |
| //div[@lang="eng"] | 选取所有lang属性为eng的div元素 |
| /div/* | 选取属于div元素的所有子节点 |
| //* | 选取所有元素 |
| //div[@*] | 选取所有带属性的div元素 |
| //div/a | //div/p | 选取所有 div元素的a和p元素 |
| //span | //ul | 选取文档中的 span和ul元素 |
| article/div/p | //span | 选取所有属于article元素的div元素的p元素 以及文档中所有的span元素 |
ps1: xpath 可以配置, 可以从数据库中提取,很灵活
from scrapy import Selector
sel = Selector(text=html)
name_xpath = "//*[@id='info']/div/p[1]/text()"
tag = sel.xpath(name_xpath).extract()[0]ps2: xpath 获取一个节点,同时有2个class的情况下,必须要写2个,或者用下面的写法
写一个获取不到
teacher_tag = sel.xpath("//div[@class='teacher_info']/p")
写2个才可以获取
teacher_tag = sel.xpath("//div[@class='teacher_info info']/p")
或者用如下方法
teacher_tag = sel.xpath("//div[contains(@class,'teacher_info)]/p") ps3: xpath 获取属性值 最后加 /@class
text_xpath ="//*[contains(@class, 'nav')]/ul/@class"ps4: xpath方法
ps5: 同时获取2个节点 |
text_xpath ="//p[@class='age']|//p[@class='work_years']"css 用法
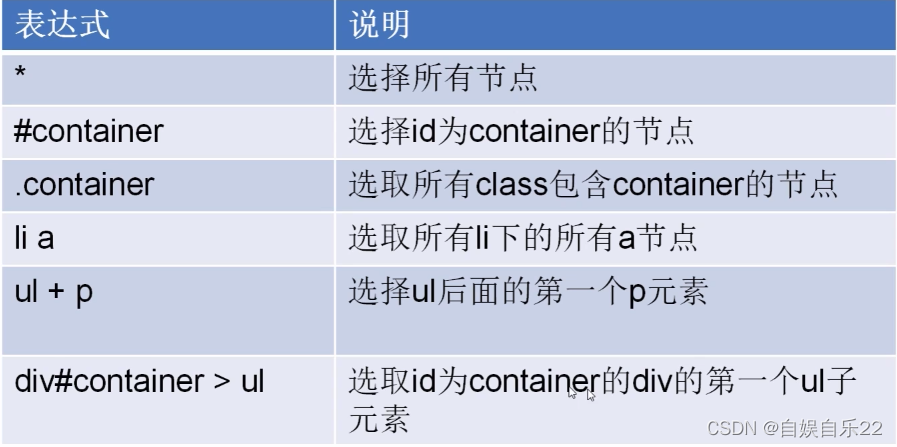
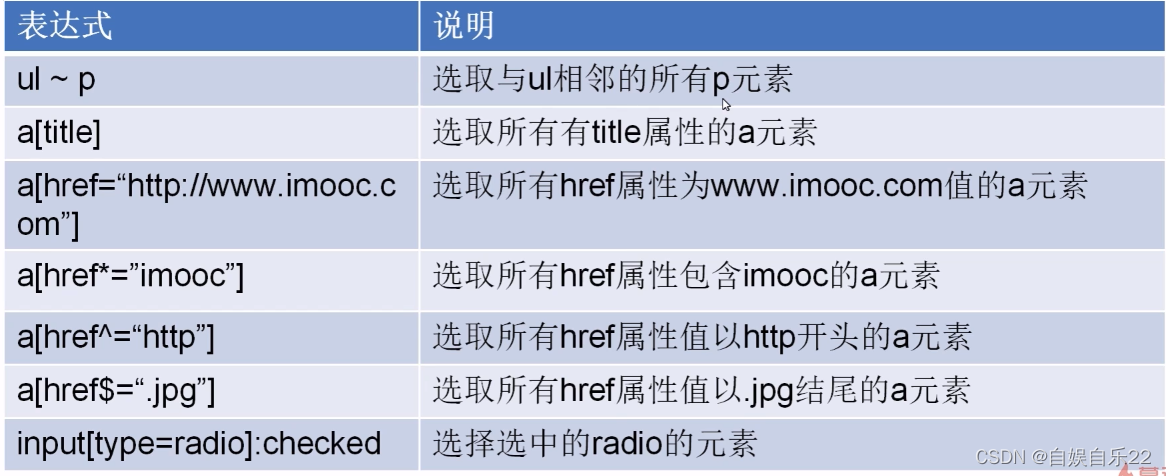

from scrapy import Selector
import requests
# 解析html内容
html = requests.get('https://www.lfd.uci.edu/~gohlke/pythonlibs/')
# 解析后内容
html = html.text
# css选择器
sel = Selector(text=html)
# 获取值
ret = sel.css('#sitemenu>li a::text')
# 打印
print(ret.extract()[0])
















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









