







Rcnn
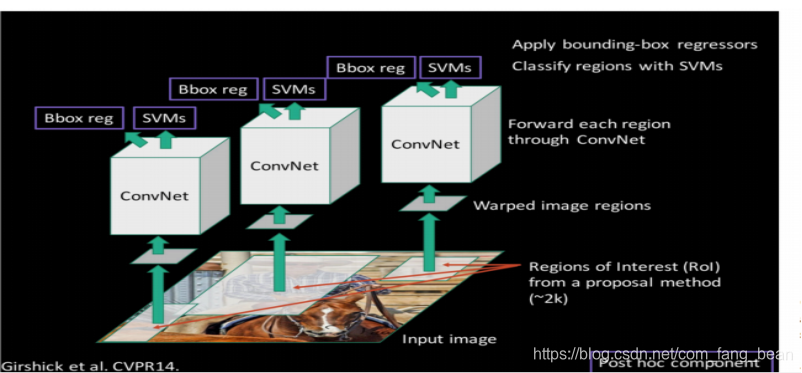
第一步:输入图像,采用Selective Search 从原始图片中提取2000个左右区域候选框
第二步:划分区域提案,进行归一化:将所有候选框变为固定大小的(227*227)区域,对每个候选区域,使用深度网络提取特征
第三步:CNN网络提取特征 送入每一类的SVM 分类器,判别是否属于该类
第四步:NMS(非极大值抑制)区域边框,采用DPM精修边框的位置
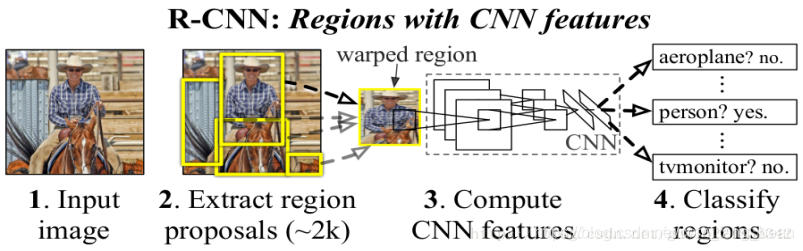
先模型输入为一张图片,然后在图片上提出了约2000个待检测区域,然后这2000个待检测区域一个一个地(串联方式)通过卷积神经网络提取特征,然后这些被提取的特征通过一个支持向量机(SVM)进行分类,得到物体的类别,并通过一个bounding box regression调整目标包围框的大小。
第一步:候选区域生成
RCNN开创性的提出了候选区(Region Proposals)的方法,先从图片中搜索出一些可能存在对象的候选区(Selective Search),使用了Selective Search方法从一张图像生成约2000-3000个候选区域。
基本思路如下:
- 使用一种过分割手段,将图像分割成小区域
- 查看现有小区域,合并可能性最高的两个区域。重复直到整张图像合并成一个区域位置
- 输出所有曾经存在过的区域,所谓候选区域
Selective research for object recognition(选择性搜索)
1.适应不同尺度:通过改变窗口的大小来适应物体的不同尺度,算法采用图像分割(image segmentation)和层次算法(Hierarchical Algorithm)
2.通过使用颜色、纹理、大小等多种分割策略对于分割好的区域进行合并
第二步:特征提取
1:预处理
使用深度网络提取特征之前,首先把候选区域归一化成同一尺寸227×227。 利用AlexNet网络对每个候选区域提取4096维特征向量(第7层的输出)。首先将候选区域转化为227×227分辨率的RGB图像,以便于可以作为CNN的输入。然后图像通过五个卷积层和两个全连接层向前传播来提取特征。
此处有一些细节可做变化:外扩的尺寸大小,形变时是否保持原比例,对框外区域直接截取还是补灰。会轻微影响性能。
2:预训练 训练过程是分阶段的,CNN与SVM分别单独进行训练。
1网络结构
上面AlexNet网络提取的特征为4096维,之后送入五个卷积层和两个全连接层进行分类。 学习率0.01。
2训练数据
使用ILVCR 2012的全部数据进行训练,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









