







1. java中wait和sleep有什么区别?多线程条件下如何保证数据安全?
wait会释放锁,线程时交互
sleep会持有锁,用于暂停执行
2. spring主要使用了哪些?IOC实现原理是什么?AOP实现原理是什么?
spring主要功能有IOC,AOP,MVC。
IOC实现原理:先反射生成实例,然后调用时主动注入。
AOP原理:主要使用java动态代理
3.mybatis与hibernate?
都是轻量级ORM框架。
hibernate实现功能比较多,通过HQL操作数据库,比较简单方便,但hibernate自动生成的sql相长,不利测试和查找原因。复杂sql时,编写比较困难,同时性能也会降低。
mybatis是半自动化,手动编写SQL语句,同时提供丰富的参数判断功能。sql语句较清晰,可以直接进行测试,性能也较好,操作起来非常简单。
4.缓存框架有哪些?memcache和redis有什么区别?项目中,怎么去选择?
缓存有:ehcache,memcache和redis。
EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认CacheProvider。Ehcache是一种广泛使用的开源Java分布式缓存。主要面向通用缓存,Java EE和轻量级容器。它具有内存和磁盘存储,缓存加载器,缓存扩展,缓存异常处理程序,一个gzip缓存servlet过滤器,支持REST和SOAP api等特点
特点:
- 快速、简单
- 多种
缓存策略 - 缓存数据有两级:
内存和磁盘,因此无需担心容量问题 - 缓存数据会在虚拟机
重启的过程中写入磁盘 - 可以通过
RMI、可插入API等方式进行分布式缓存 - 具有缓存和缓存管理器的侦听接口
- 支持
多缓存管理器实例,以及一个实例的多个缓存区域 - 提供
Hibernate的缓存实现
MemCache是一个自由、源码开放、高性能、分布式的分布式内存对象缓存系统,用于动态Web应用以减轻数据库的负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站访问的速度。MemCaChe是一个存储键值对的HashMap,在内存中对任意的数据(比如字符串、对象等)所使用的key-value存储,数据可以来自数据库调用、API调用,或者页面渲染的结果。
Redis 是完全开源的,是一个高性能的 key-value 数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis 优势
- 性能极高
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 通知, key 过期等等特性。
区别:
1、 Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过 memcache还可用于缓存其他东西,例如图片、视频等等。
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的 存储。
3、虚拟内存--Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
4、过期策略--memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通 过例如expire 设定,例如expire name 10
5、分布式--设定memcache集群,利用magent做一主多从;redis可以做一主多从。都 可以一主一从
6、存储数据安全--memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)
7、灾难恢复--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
8、Redis支持数据的备份,即master-slave模式的数据备份。
项目选择:
并发:使用redis
存储数据较大:memcache
5.说说数据库性能优化有哪些方法?
使用explain进行优化;
sql是否充分使用索引;
避免使用in,用exist替代;
简化字段值;
查询时要尽可能将操作移至等号右边。使用连接查询(join)代替子查询。
对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 应尽量避免在 where 子句中对字段进行 null 值、使用!=或<>操作符、使用 or 来连接条件、拼接字符串判断、
where 子句中的“=”左边进行函数、算术运算或其他表达式运算,可以在num上设置默认值0,确保表中num列没有null值
6. HTTP请求方法get和post有什么区别?
Post传输:URL不显示,传输的数据量大
Post传数据到service,Ge是为了从service取得数据。
7.JVM内存模型是如何?垃圾回收机制有哪些?如何对JVM进行调优?
由栈和堆组成,栈是运行时单位,堆内存则分为年轻代、年老代、持久代。
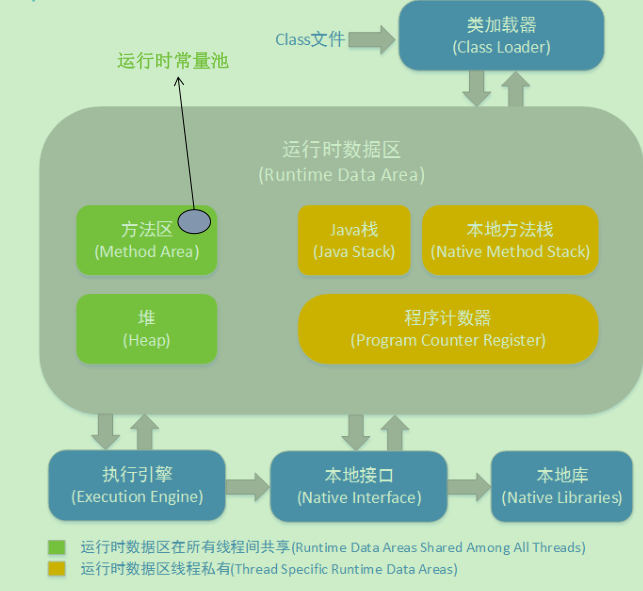
回收机制:主要对年轻代和年老代中的存活对象进行回收,分为以下:
年轻代串行(Serial Copying)、年轻代并行(ParNew)、年老代串行(SerialMSC),年老代并行(Parallel Mark Sweep),年老代并发(Concurrent Mark-Sweep GC,即CMS)等等,目前CMS回收算法使用最广泛。
8.如何保证数据一致性,高并发时,又如何保证性能和数据正确?
如果是单机内完成这些操作,那使用数据库的事务.
分布式事务可以采用分布式锁进行实现,目前zookeeper就提供此锁;分布式锁需要牺牲一定性能去实现。
9. java抽象类和接口有什么区别?项目中怎么去使用它们?
两者都是抽象类,都不能实例化。 interface实现类及abstractclass的子类都必须要实现已经声明的抽象方法。
区别:接口需要实现,抽象类需要继承
类和接口是一对多,类和抽象类是一对一
接口强调功能实现,抽象类强调类关系
10.极高并发下HashTable和ConcurrentHashMap哪个性能更好,为什么,如何实现的。
- HashTable使用一把锁处理并发问题,当有多个线程访问时,需要多个线程竞争一把锁,导致阻塞
- ConcurrentHashMap则使用分段,相当于把一个HashMap分成多个,然后每个部分分配一把锁,这样就可以支持多线程访问。
11.HashMap在高并发下如果没有处理
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 413
413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









